咱就是说,最近就开始刷到不少本地部署DeepSeek-R1的内容。
很多网友发文/发视频称成功在本地部署并用上了比肩OpenAI-o1的DeepSeek-R1模型。虽然感觉上还是有些不对劲,但是DeepSeek-R1作为开源模型,它确实是可以本地部署。
作为一名RTX4090用户,在家用电脑玩家里也算是高配党了,我寻思这么多人都成功本地部署上了,那我这配置应该也可以吧。于是我就跟着去看了一看,嗯……然后发现:
翻译真是个好东西!
如果你不愿意用谷歌网页翻译,那你真的可以试试翻译插件——小红书英文评论太多看不懂了?推荐你试试沉浸式翻译。
确实,DeepSeek跟R1一块发布了几个小参数模型,1.5B、7B、8B都有。但看名字,就算不认识Llama,你不觉得那个Qwen有点眼熟吗?我拼音都在嘴边要拼出来了。
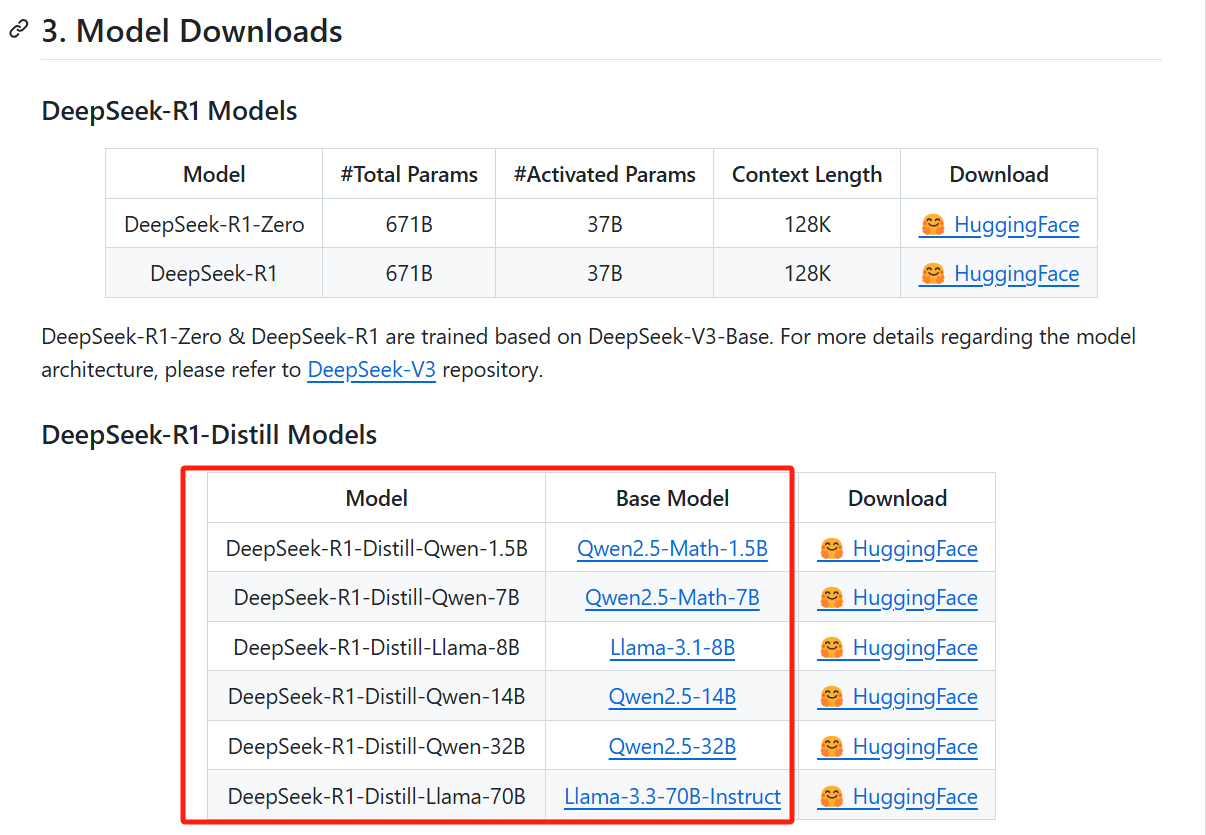
GitHub和抱抱脸的页面上写的都很清楚,如果要选个背锅的,我觉得可能是Ollama。
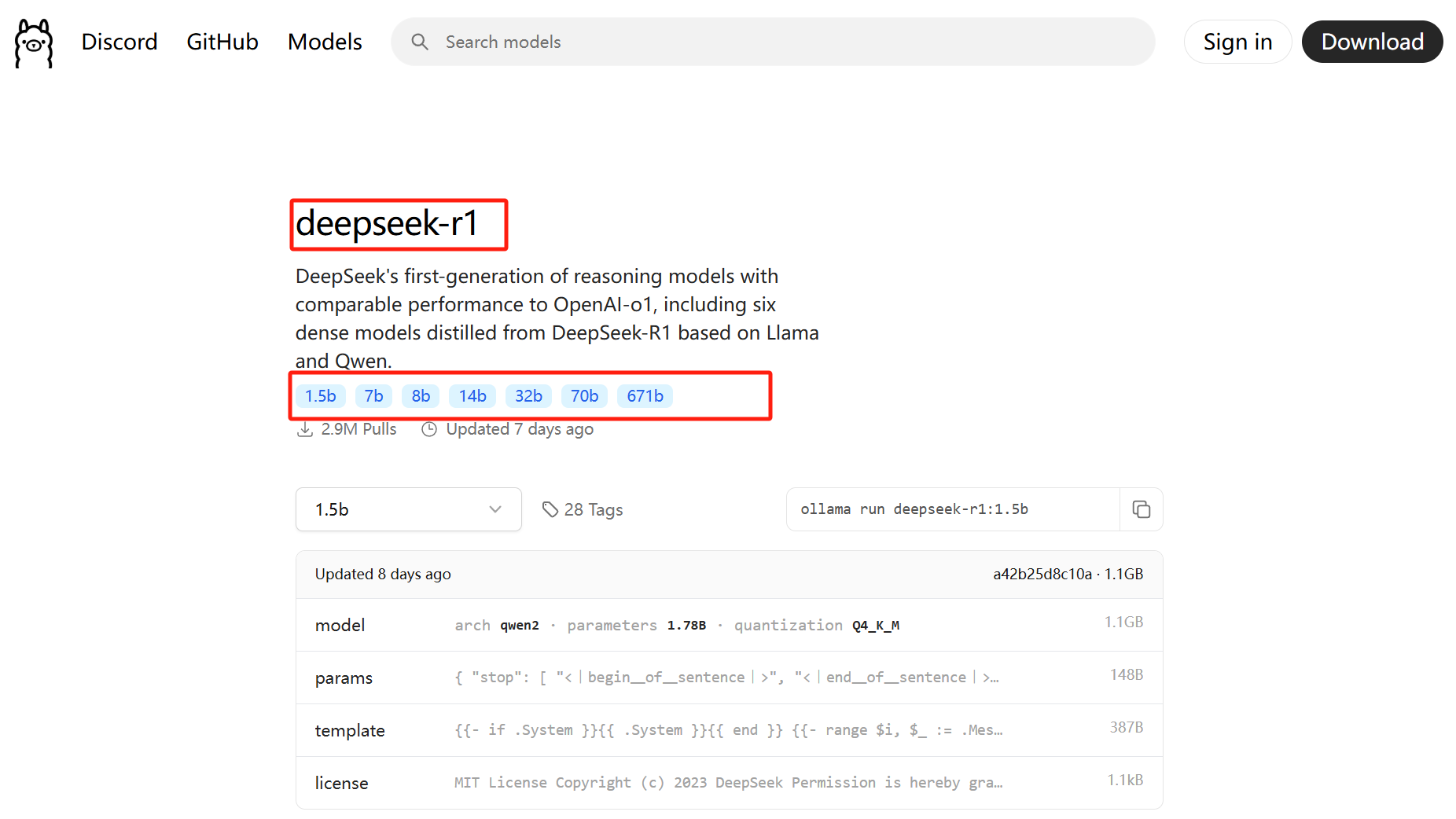
上面写着deepseek-r1,下面标了1.5b/7b/8b/14b/32b/70b/671b。
但是,朋友们,如果你打开翻译再往下划。
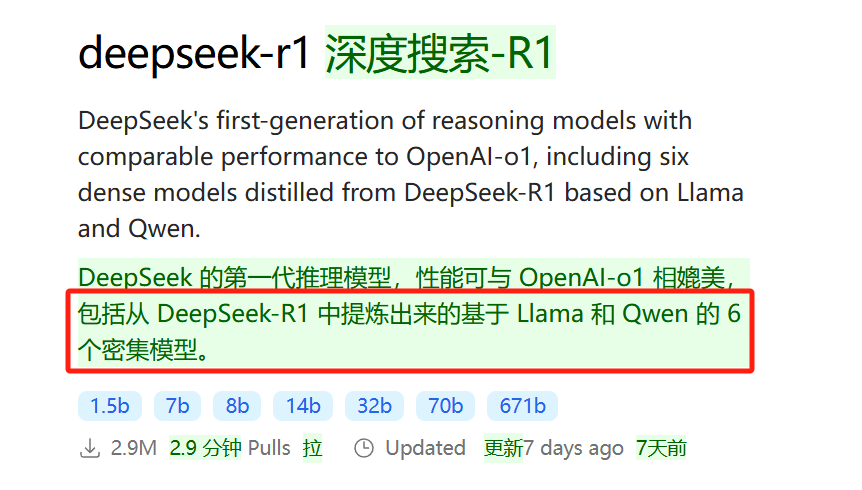
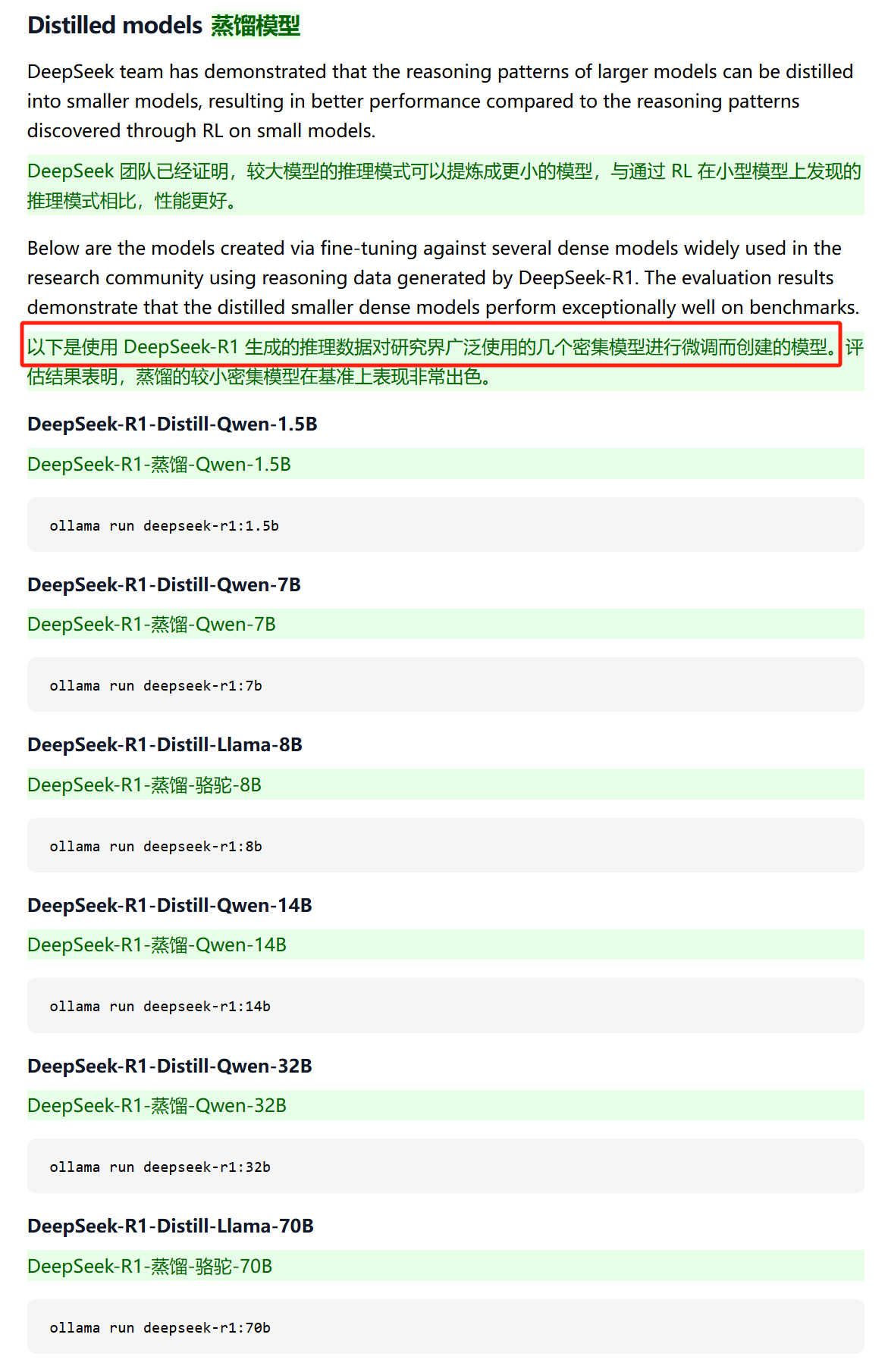
这几个是使用 DeepSeek-R1 生成的推理数据对研究界广泛使用的几个密集模型进行微调而创建的模型呀。
GitHub页面上同样有相关说明:


DeepSeek-R1-Distill 模型基于开源模型使用 DeepSeek-R1 生成的样本进行微调。 我们稍微更改了他们的配置和分词器。请使用我们的设置来运行这些模型。
所以,DeepSeek-R1-Distill-Qwen-1.5B模型,它本质上还是Qwen2.5-Math-1.5B;DeepSeek-R1-Distill-Llama-8B模型,本质上也还是Llama-3.1-8B。
DeepSeek放出这几个蒸馏模型,是为了说明「较大模型的推理模式可以提炼成较小的模型,与通过 RL 在小型模型上发现的推理模式相比,性能更好。」
而官方发布的真正的R1模型,只有DeepSeek-R1和DeepSeek-R1-Zero这两个,基于DeepSeek-V3-Base训练而来,参数规模671B:
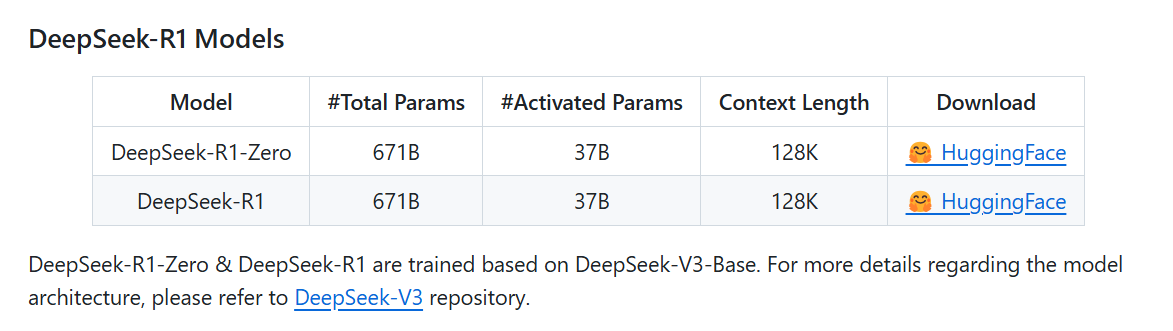
如果你非得要本地部署真正的R1,可能只能去尝试一下社区发布的1.58bit精度量化版本的DeepSeek-R1-GGUF,使用RTX4090这样的24G显存GPU,可以实现每秒钟高达1-3个token的输出速度。
所以,别折腾了。
网页版免费,API也不贵,折腾毛啊。