【提示:接下来是聊天内容,直接开始本地部署教程,请前往文章中间部分。】
这几个蒸馏模型并非真正的DeepSeek-R1,之前已经发文说过:醒醒!你本地部署的DeepSeek-R1,它不是R1。
但这并不代表这些模型不行,或者说我不建议大家部署和使用这些模型。
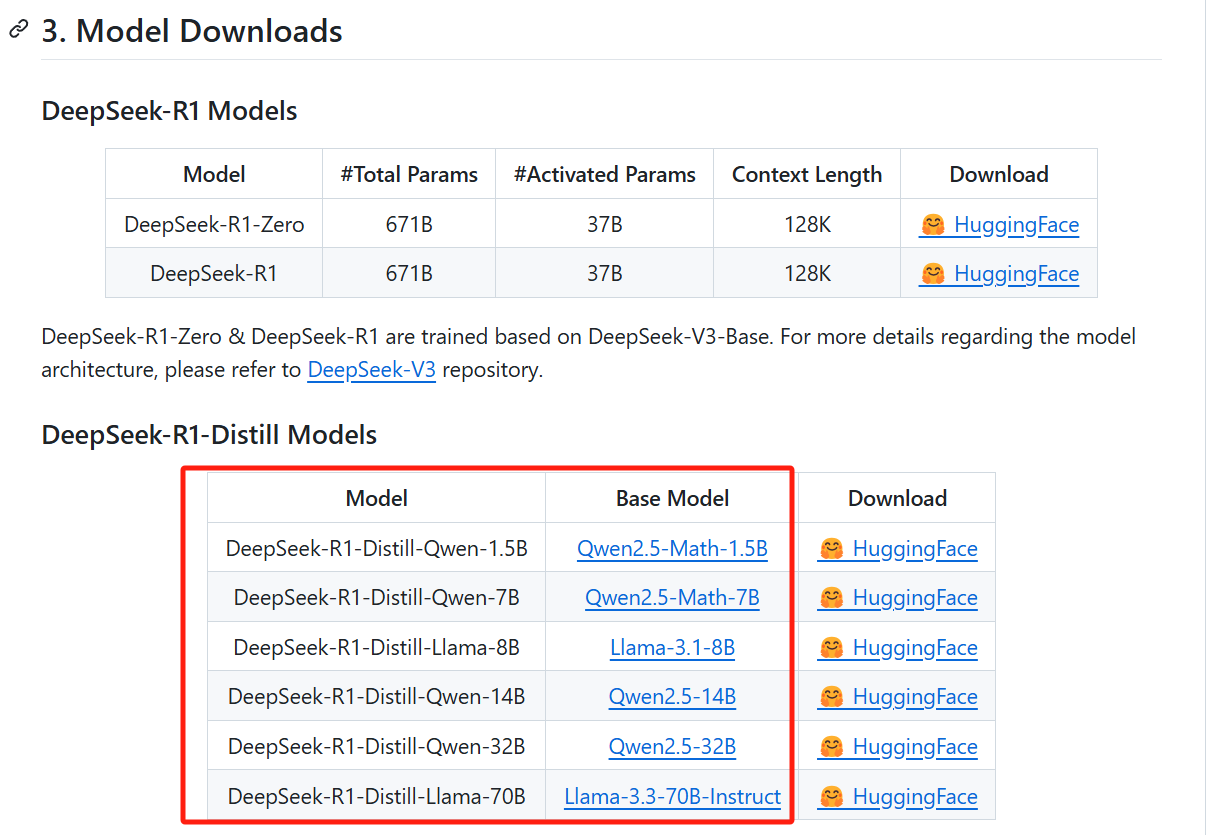
相反,这几个蒸馏模型的基础模型,本身就是被广泛用于本地部署的几个优秀的开源模型。而且经过DeepSeek蒸馏以后,它们的性能变得更好。
这就不得不从DeepSeek团队训练DeepSeek-R1的过程中取得的几项技术成果说起。
①直接在基础模型上应用强化学习(RL),跳过了监督微调(SFT)。
监督微调(SFT)是训练大语言模型的常规步骤,即在预训练的基础模型上,使用高质量的标注数据(如人类编写的问答对、任务示例等),通过监督学习的方式对模型进行微调。相当于老师(人工)对学生(模型,准确说是DeepSeek-V3)说:这些题目和答案我检查过了,都是对的,你拿去学吧。
这个学的过程,就是强化学习(RL)。而强化学习依赖于奖励机制。套回刚才的例子,就是,学生把老师给的题目和答案拿回去,开始自己解题。当解出了跟正确答案一致的答案,老师就奖励给他一朵小红花。
DeepSeek的第一个重要研究成果,就是跳过了监督微调的步骤,直接进行强化学习。调整了奖励模型,从传统的解出了正确答案就给奖励,改成了针对逻辑连贯的解题过程给予奖励,最终大幅激发了模型的推理能力。
而以此方法训练出来的模型,就是DeepSeek-R1-Zero。
②基于在R1-Zero上验证的创新方法,重新设计了结合监督微调的训练方法,训练出了DeepSeek-R1。
为什么我们公众最终用到的模型是R1,而不是R1-Zero?因为R1-Zero虽然探索了推理极限,但它没有经过监督微调,就导致了它的通用语言能力比较弱并且安全性上可能存在问题。
于是,在R1-Zero研究成果的基础上,DeepSeek重新设计了训练R1的方法并训练出了R1。(注意:R1不是在R1-Zero基础上训练而来的,而是平行训练,两者共享了强化学习方法论。)
③验证了蒸馏大体量模型的推理模式可以用于提升小体量模型的性能。
这里也可以说DeepSeek设计了一种新型的蒸馏方式,而这个新蒸馏方式的产物,就是本文说的几个DeepSeek蒸馏的小体量模型。
传统的蒸馏侧重于让小模型学习大模型的输出结果(概率分布),例如让一个小体量模型学习GPT的输出,最终使得自己的输出接近于GPT;而DeepSeek的这种蒸馏则是不仅学习输出结果,还要让小模型学习大模型的思考过程,例如让Llama-3.1-8B学习DeepSeek-R1(671B)的推理数据。
简单说就是一个是只学习答案,一个是学习解题过程+答案。
而最终DeepSeek团队验证的结论就是,通过学习解题过程,基础模型本身的推理能力获得了大幅提升。
就像那个故事:有个小baby的妈妈炫耀自己的孩子已经会10以内的加减法了,并且过年的时候当众表演赢得一片叫好。这时候有个耿直的初中生追问:为什么?小baby就不会了,因为它只是把答案背了下来,但没有学会真正的计算。
并且还要好于直接通过①的方法让小模型自己通过强化学习发现推理过程。这点也不难理解,DeepSeek-R1-Zero的训练基础模型是671B的DeepSeek-V3,规模够大,所以允许推理能力的涌现。而小模型,比如Qwen-2.5-Math-1.5B,受限于自身掌握的知识量,很难通过强化学习自主探索出复杂的推理路径。
这个蒸馏方法对小模型性能提升具有很大的意义,尤其是一些部署在移动设备的端侧小模型。
但需要注意的是,即便小模型通过推理模式蒸馏学习了更大模型的思考方式,它本身掌握的知识量依旧是它原本掌握的知识。这也是为什么说伴随DeepSeek-R1发布的那几个蒸馏的小模型不是DeepSeek-R1,因为他们虽然学习了DeepSeek-R1的解题方法,但自身的知识储备仍然是原本的Qwen和Llama。
所以说,如果你寄希望于通过本地部署的方式获得跟直接使用DeepSeek-R1线上服务一样的体验,那我依旧劝你别折腾了。不仅模型规模不同,本身的数据集也不一样。API的性价比很高,对你来说绝对是更好的选择。
但如果你本身就有本地部署的应用场景,例如进行一些有安全规定的研究,或者说翻译大量的文本等等,那你可以尝试本地部署这些模型,因为他们在很多方面的性能要比原来的底模型要更好。
【好了。下面就是本地部署教程了,以Windows讲解,Mac大同小异。】
首先下载Ollama并安装。
https://ollama.com/
然后运行。运行之后没有任何界面窗口,这个是正常的。
在右下角系统托盘会显示一个Ollama图标,有这个图标即说明启动成功了。

然后右击开始菜单图标,打开终端。
直接输入
ollama run [你想要部署的模型:模型规模]
这个命令可以在直接在Ollama的网站上找,例如这是DeepSeek-R1的主页面:
https://ollama.com/library/deepseek-r1
在这个页面向下翻,对应的命令都在这里。

如果你想部署DeepSeek-R1以外的其他模型,也是一样,可以到这个页面查找:
https://ollama.com/search
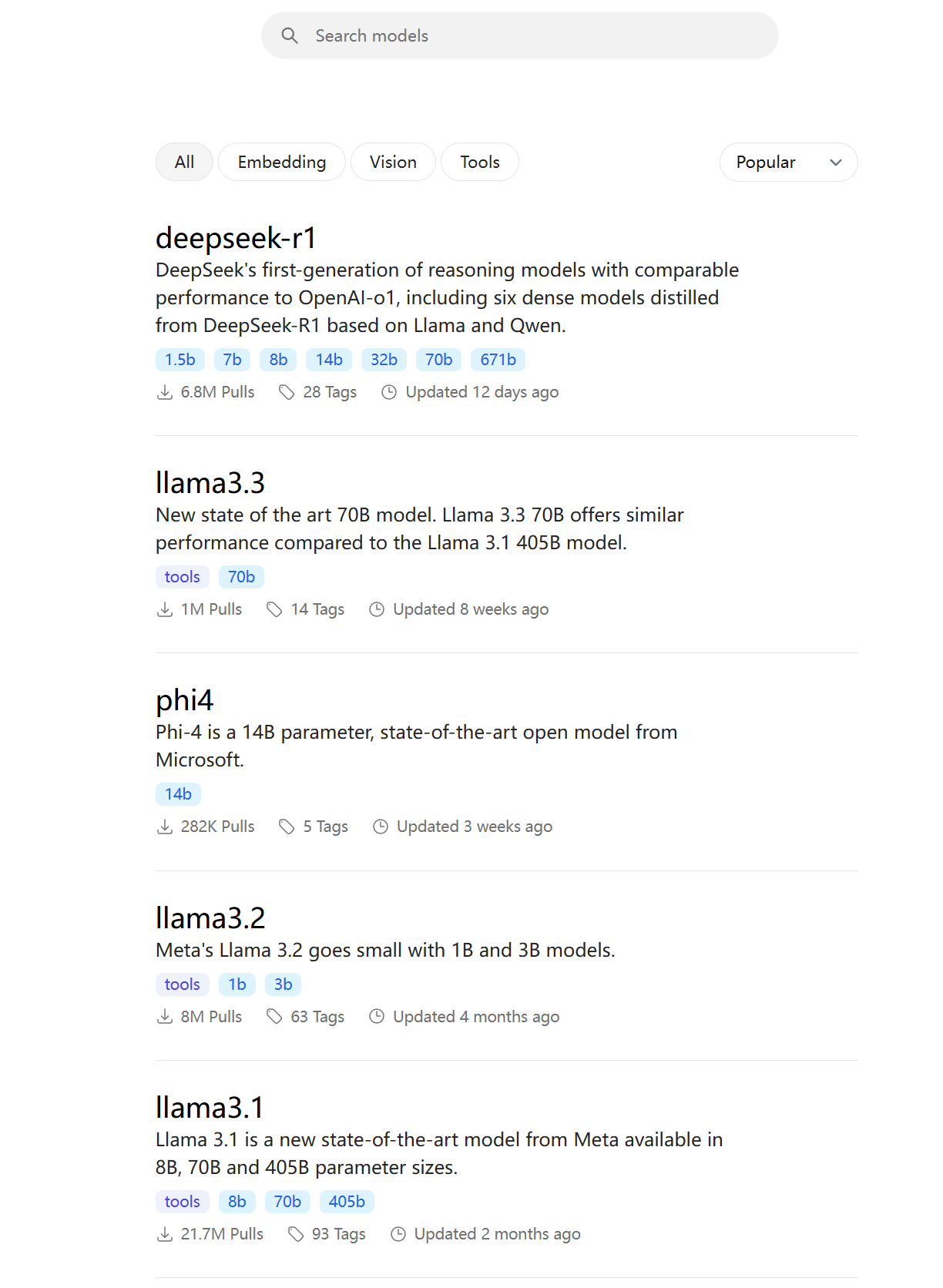
ollama run [你想要部署的模型:模型规模]
前面的你想要部署的模型的名字,就是这个页面上显示的名字,后面的模型规模,就是下面蓝色标签显示的多少b。
比如,我想部署一个llama3.2的3b模型。
那我就输入:
ollama run llama3.2:1b
它就会开始自动下载。
下载完成后,就可以马上在这个命令行窗口使用了。
像这样,直接就可以对话了。
如果需要退出,就输入
/bye
然后就退出了。
如果你要再次使用,还是输入一样的语句。比如:
ollama run deepseek-r1:32b
我们先拆解一下它便于记忆。
ollama,是这个软件的名字,llama这个单词美洲驼的意思。
run就是运行。
deepseek-r1是模型名称,32b是模型规模。
合起来:
ollama run deepseek-r1:32b
因为之前已经下载好了,所以不会有下载过程,会直接打开。
但这个样子用起来多少有些不优雅,如果有个界面就好多了。
所以,我们为了让它优雅起来,可以安装一下Open-WebUI。这个Open-WebUI前身就叫做Ollama-WebUI,可见它和Ollama的匹配度之高。
https://github.com/open-webui/open-webui/pkgs/container/open-webui
安装Open-WebUI之前需要先配置Ollama的端口和安装Docker。
直接在开始菜单搜索框里搜索“环境变量”,点击“编辑账户的环境变量”。
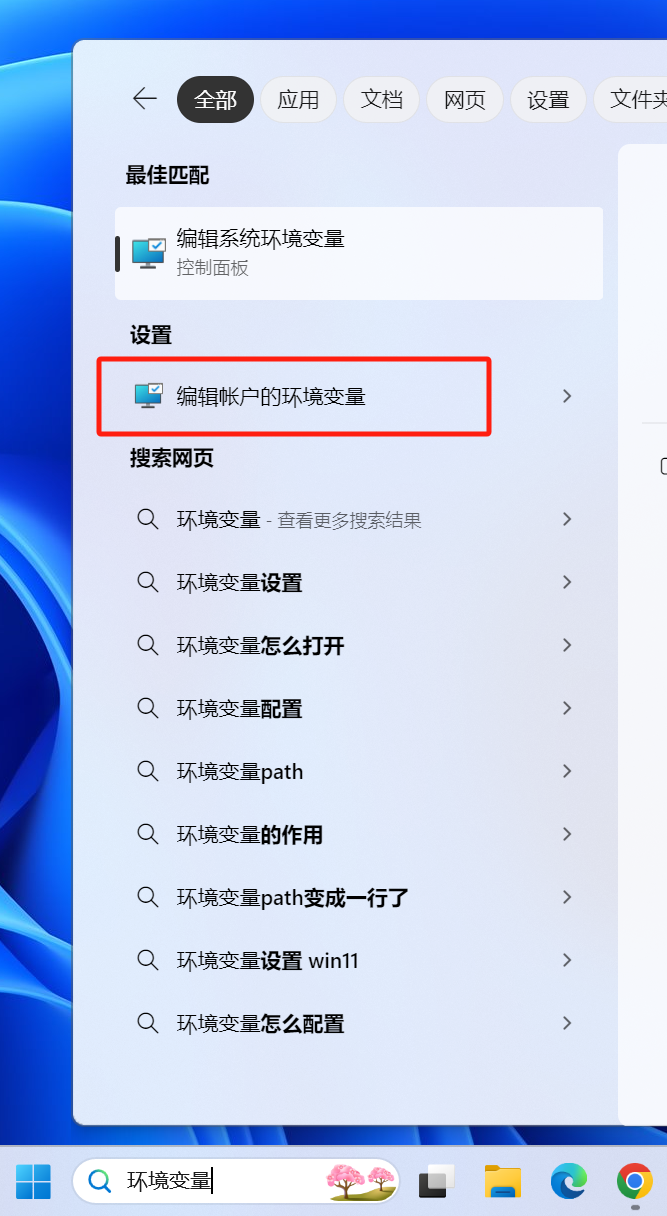
新建两个环境变量。
一个OLLAMA_ORIGINS,值为*;
一个OLLAMA_HOST,值为0.0.0.0:11434。
端口号官方默认给的是11434,我自己改成我喜欢的端口了,如果你之后还准备按照其他教程部署别的东西,比如浏览器插件、翻译插件、SillyTavern啥的,觉得到那时候会记不住在这自己设置了端口号,那你就直接用11434。
安装Docker的过程很简单,而且网上太多教程,为了节约篇幅我就不说了。
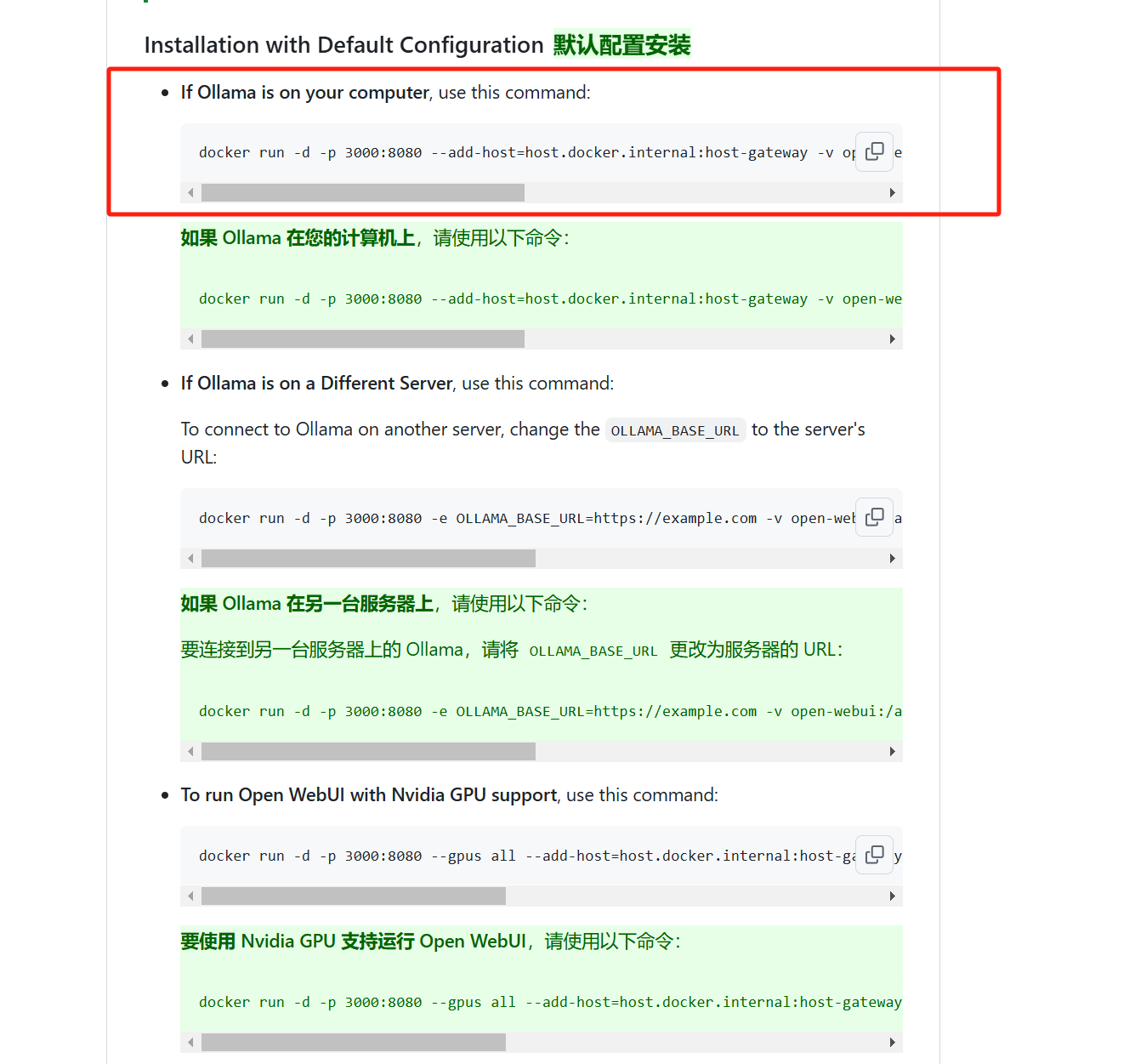
如果你是本机安装,就在Docker里面运行这个这个命令。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
这里面的-p 3000:8080,前面的3000代表你使用的本地端口是3000端口,这个端口号是可以改的。
因为挺多应用喜欢把默认端口设置成3000的,所以保不齐有端口冲突。如果你的3000端口已经被占用了,那就改个别的数,比如3001。后面访问WebUI的时候把URL里面的端口号数字改成3001就行。
然后我自己是习惯把Docker全部部署在NAS上,这样反代出去也方便,所以也说一下非本机的方法。
如果你是直接把WebUI也部署在本机的,可以直接跳过下面这段。
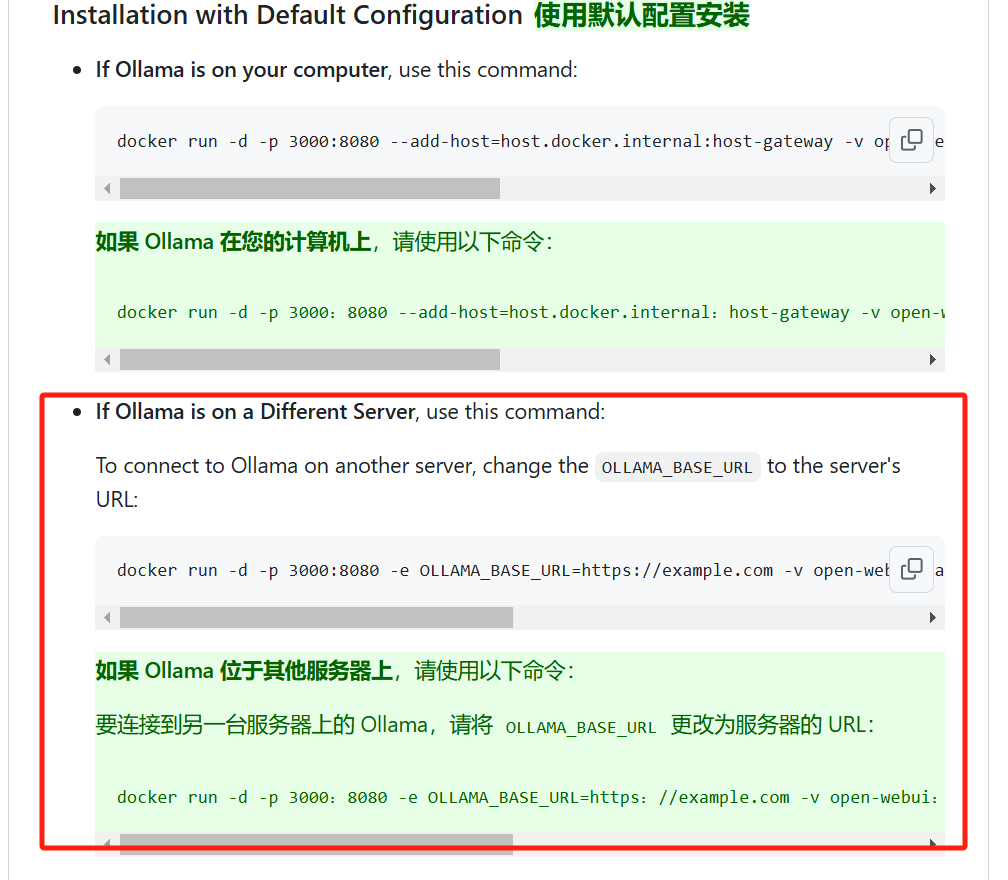
其实就是下面的第二条:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
需要多增加一个环境变量OLLAMA_BASE_URL。
什么意思呢?我们知道,在局域网下的两台设备是会被路由器分配两个不同的内网IP地址的,不然路由器就不知道哪个数据包发给哪个设备了。
假设我的PC内网IP是192.168.1.101,NAS的内网IP是192.168.1.102。按前面本机部署WebUI的方法呢,WebUI和Ollama都在192.168.1.101这台设备上,所以WebUI能直接找到11434端口跟Ollama进行数据交换。
但是,如果WebUI在192.168.1.102,Ollama却在192.168.1.101,你就得告诉它,去192.168.1.101:11434找才行,否则它傻傻地还在192.168.1.102找呢,永远找不到。
于是操作方法就是把上面的命令中
OLLAMA_BASE_URL=https://example.com
里面的https://example.com,改成对应实际的地址,比如
http://192.168.1.101:11434
这样就可以找得到了。
又如果,你使用的是极空间这种不支持SSH的NAS设备,又应该怎么办呢?别急,活用AI。
直接把命令发给AI让它解释就好。

甚至截图直接丢给AI,让它告诉你怎么操作。
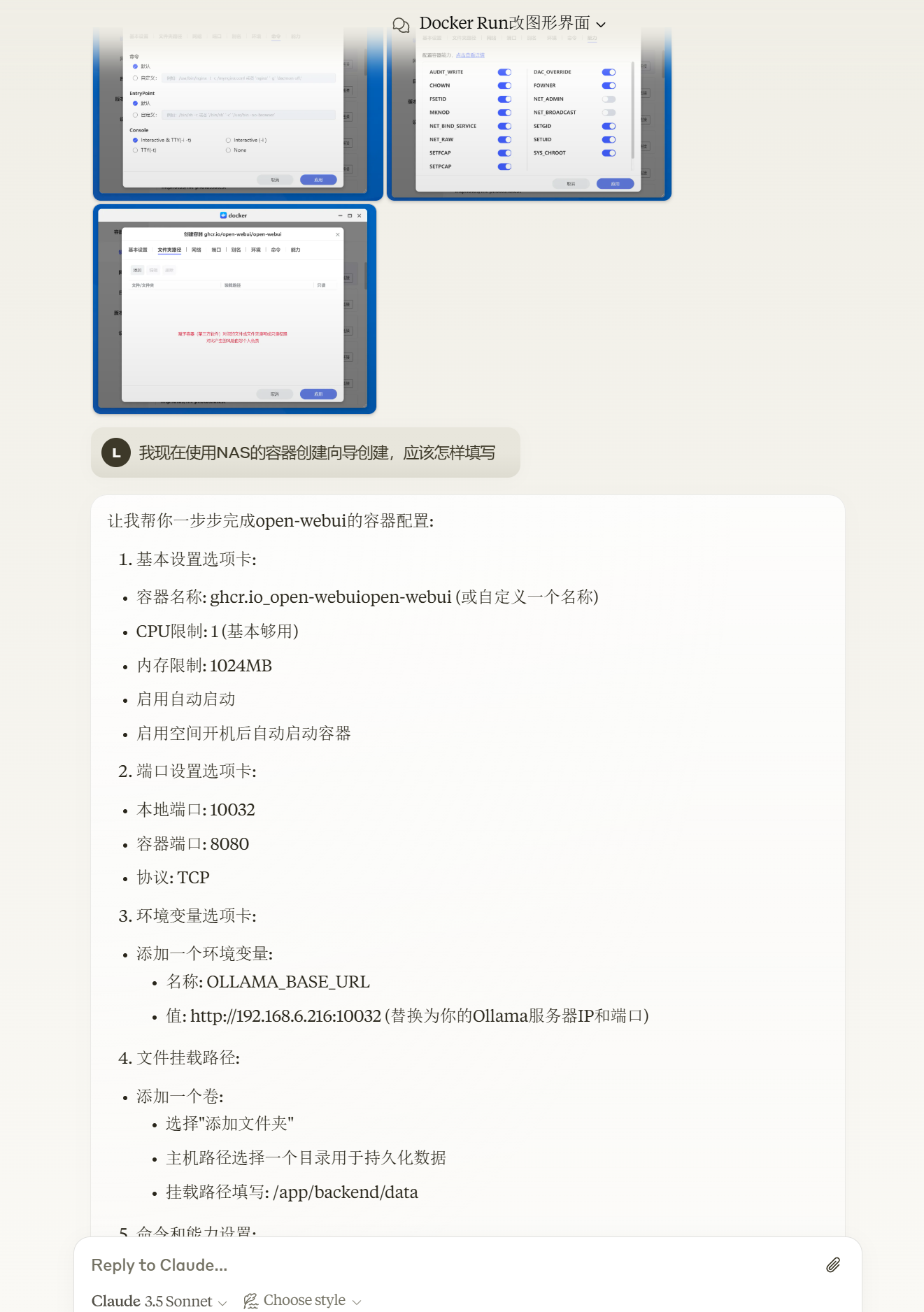
每一个选项卡,每一个空格,AI都会直接告诉你怎么填。
极空间从GitHub拉取镜像是在这里:
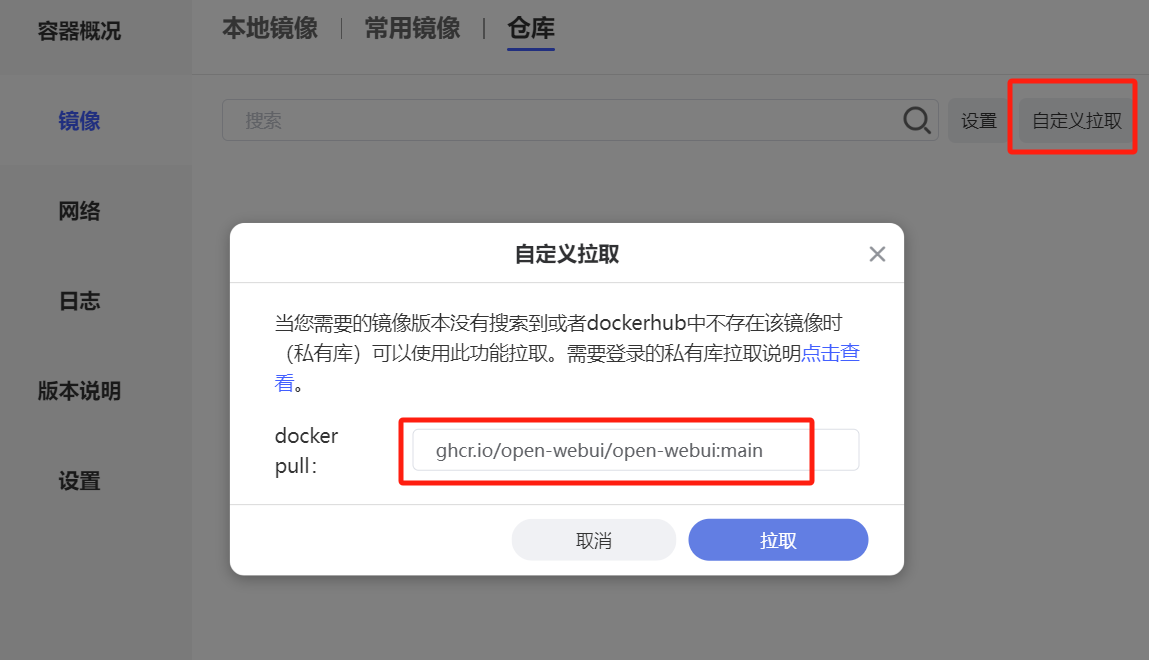
其他的如AI对话截图所示。
【好了,如果你是从上面本机部署部分跳过来的,可以降落在这里了。】
Open-WebUI的Docker启动完成后(启动可能需要一段时间),在浏览器地址栏里直接输入IP地址+端口号(如果Docker装在本机就是本机的,如果装在NAS就填NAS的),就能访问Open-WebUI了。
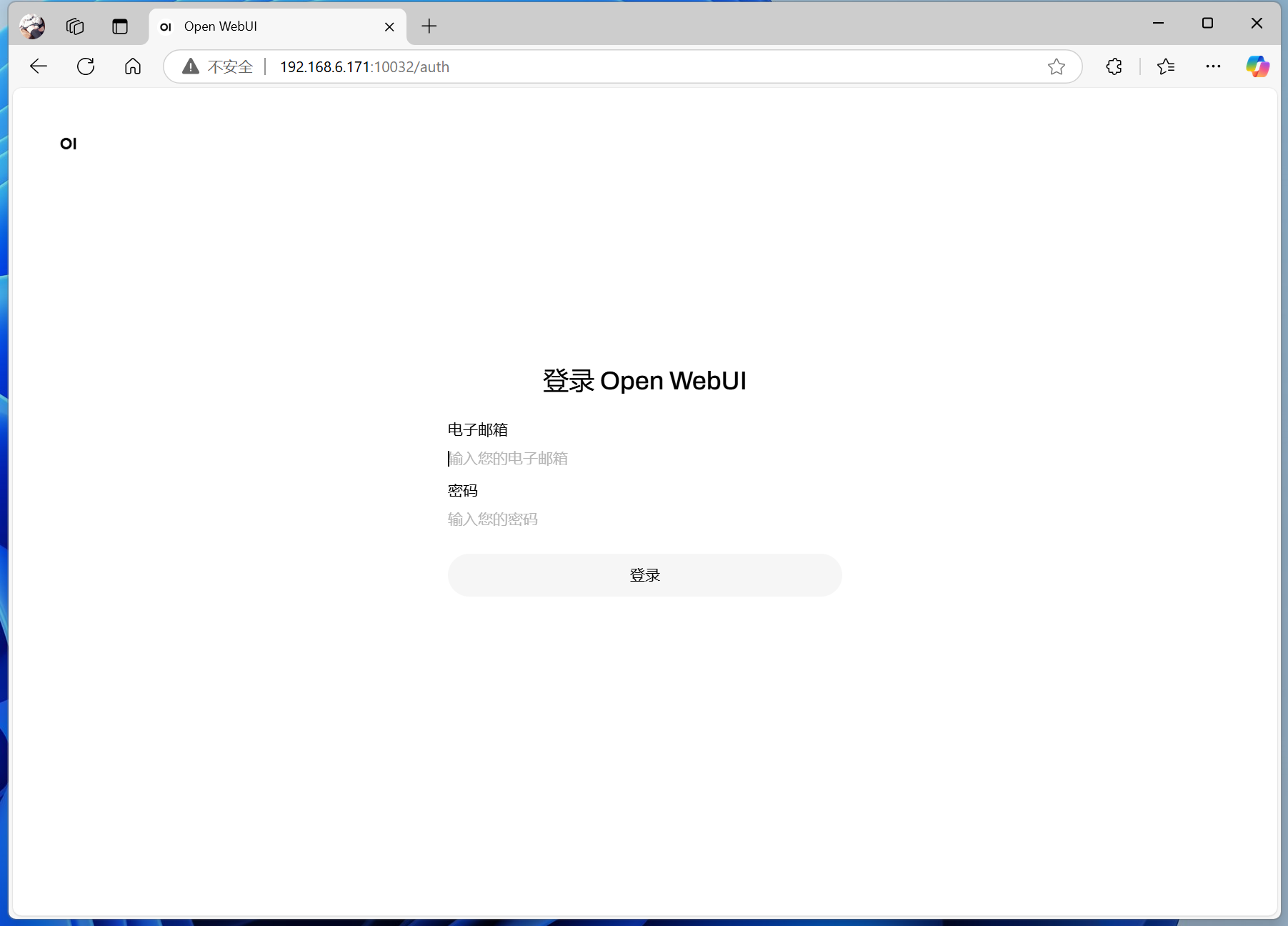
如果是第一次安装,需要先进行注册。
注意这个注册,注册的并不是Ollama账号,而是你这个本地的Open-WebUI内置的账号管理系统。你可以自己注册一个账号,老婆注册一个账号,孩子注册一个账号,三个人在家庭局域网中访问,账号的数据相互独立。
登录之后就可以进入到聊天界面了。
像我这里,显示的就是刚才下载的那个中文不是很利索的llama:1b。
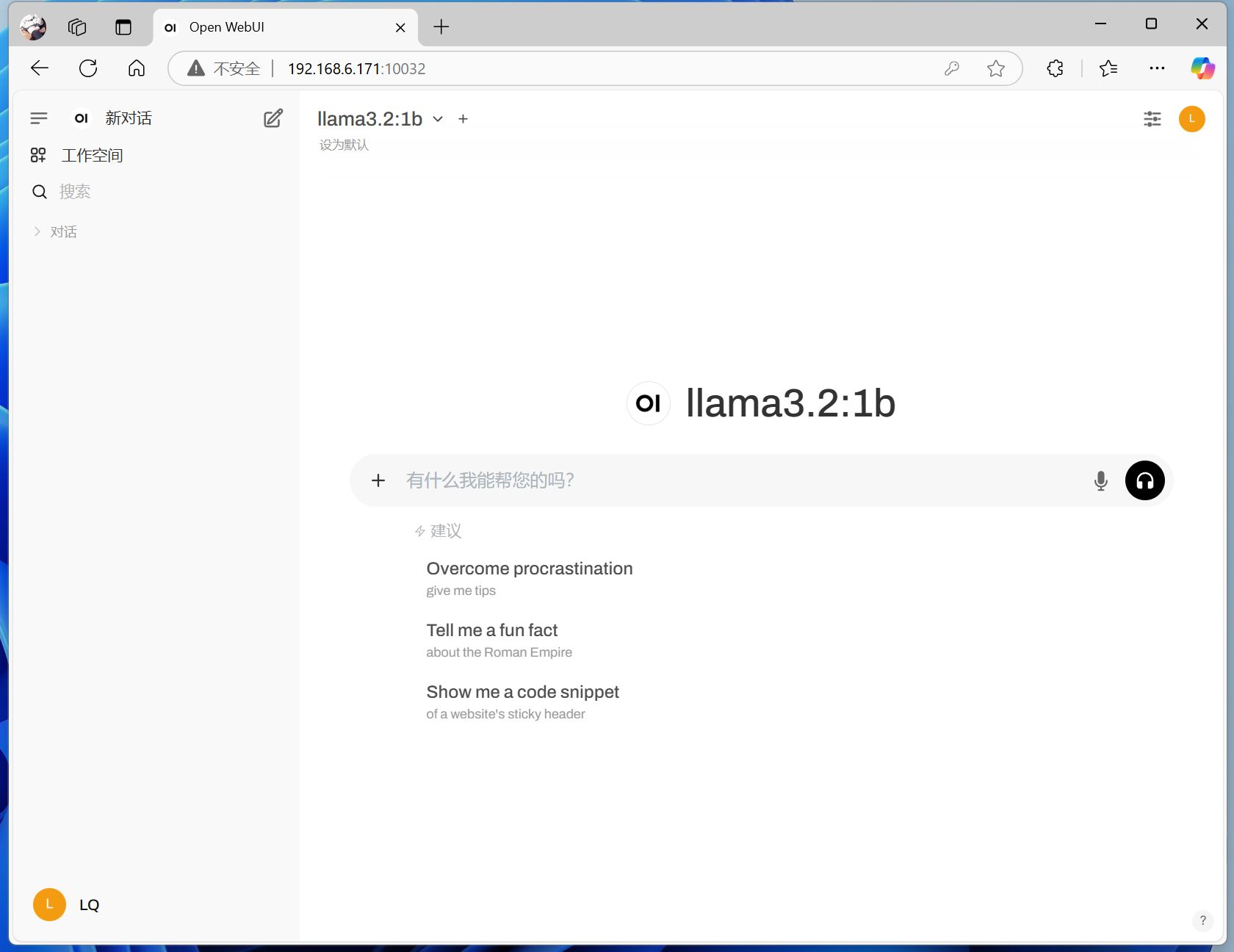
如果能够登录,但是登录之类页面一片空白。
别急,多半是忘了打开Ollama,或者是打开了Ollama但忘了run一个模型。
有了Open-WebUI,跟不同的AI模型聊天也不用每次在命令行窗口先bye再run一个新的了。可以直接通过菜单进行切换。
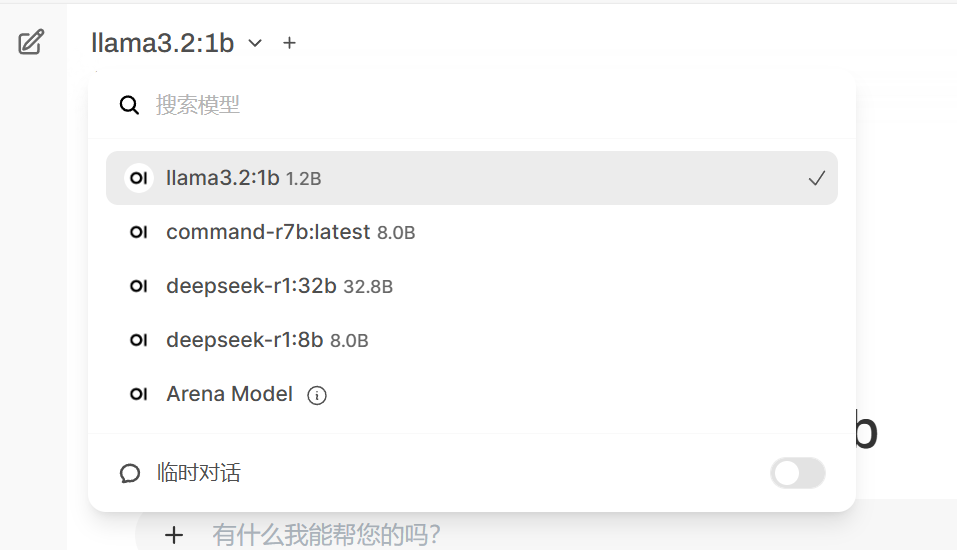
你的对话记录,也会像线上使用的AI助手一样,保存在Open-WebUI中。
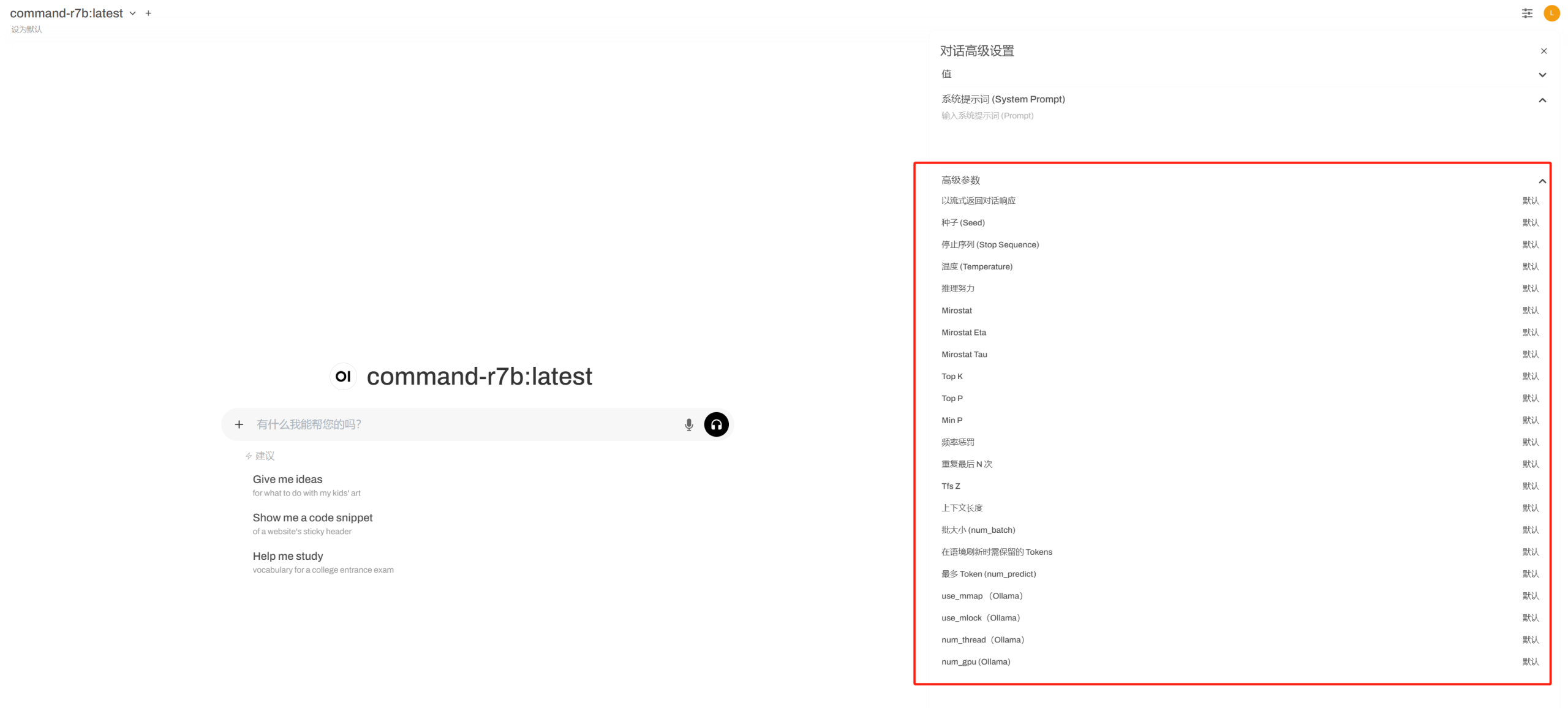
同时,你可以通过界面,对系统提示词和详细参数进行设置。
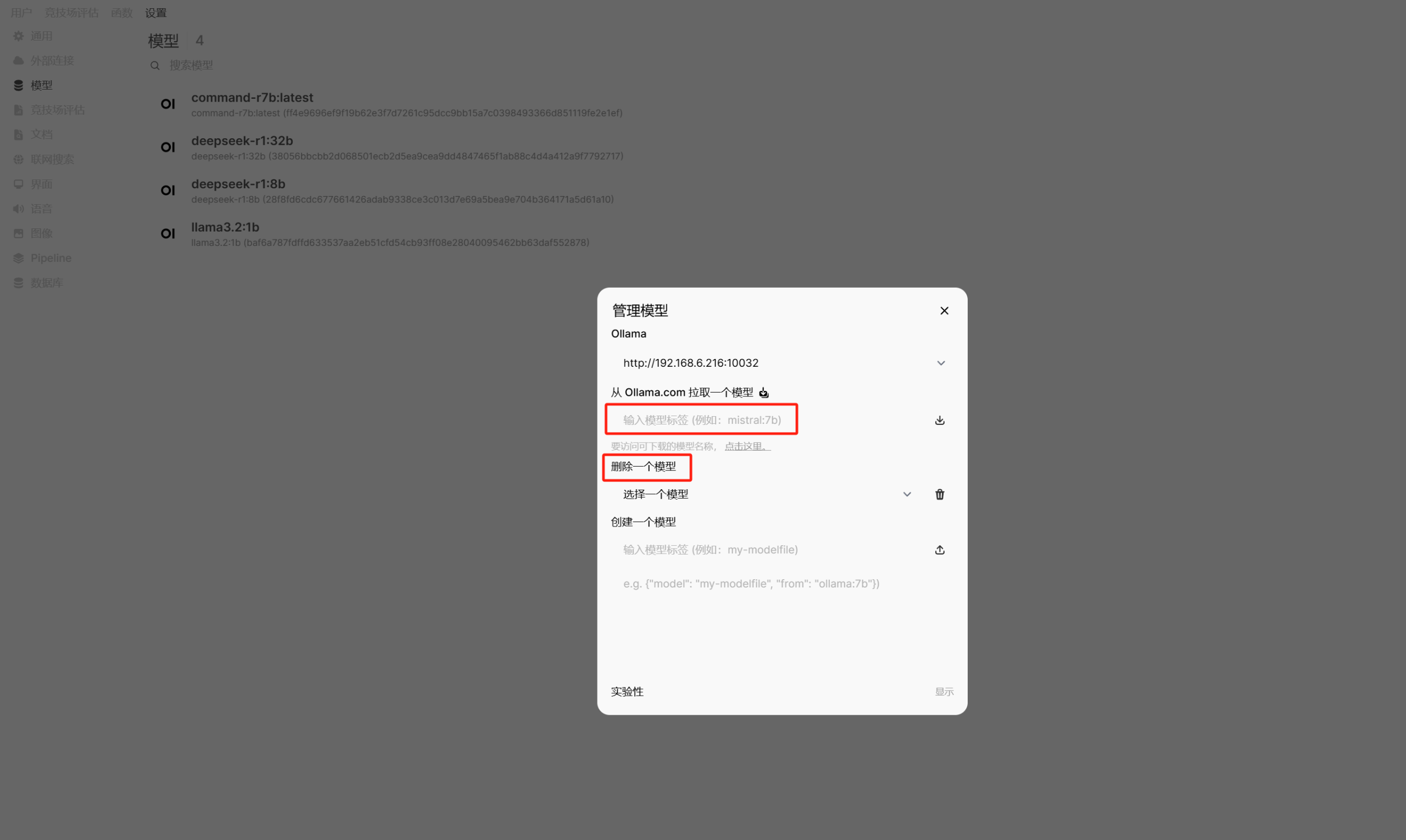
以及,你也可以在管理员面板中进行新模型的拉取和删除不想用的模型。
还有更多的细节功能我就不在这里多说了,你可以自己慢慢探索。
如果你使用24h本地主机(比如Mac Mini Pro)+NAS部署,或者说整个Ollama+Open WebUI都部署在高性能云主机上,你也可以通过反向代理绑定域名,实现随时随地的外网访问。
Enjoy!