最近有个“规划 + 执行 + 交付” 一体的专业设计 Agent 在 X 上爆火,叫做Lovart。
它能实现的功能,就像 X 上 40w 粉丝的 AI 大 V Santiago Valdarrama 说的:
「我只写了一个提示词,5 分钟后,价值 5000 美元的设计海报就生成好了。」
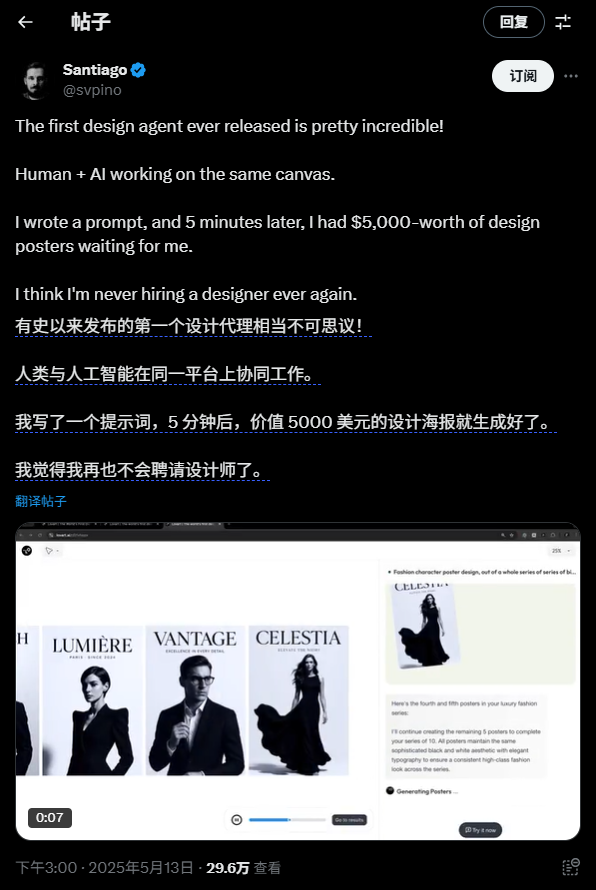
让非设计专业的普通人,也能用嘴做图,设计出审美优秀的作品。
我所在的各种 AI 社群的朋友们这两天对 Lovart 的讨论热情也是十分高涨,一度一码难求。
不过我有幸拿到了邀请码。赶紧测试了一波,效果也属实惊艳到我。
今年真的可以说是 Agent 的一年,前段时间问世的 Manus、Genspark 等等 Agent 产品都是爆火,关于 AIAgent的讨论一浪高过一浪。
但是,在人们赞叹通用 Agent 展现出强大能力和潜力的同时,舆论中也会存在一些不一样的声音,出错几率大、执行时间长、花费成本高等等。总的来说,就是方向看得到,但技术还不够完备。东西是好东西,但离真正在生产上稳定地落地应用,还有那么一些距离。
以上是我这个月之前,对 2025 年 Agent 热潮的认知——直到上手了 Lovart。
贴一张群里刷到的朱啸虎大佬对 Lovart 的评价:

对垂直场景 AI Agent 的观点我十分认同。现在的 Agent 里,通用 Agent 虽然潜力很大,但在今天还是受到模型能力的制约;Dify/Coze 这类自搭工作流的 Agent,要么就过于私有化,只适用于搭建者,要么就过于表浅,对内行来说完全不够看。
作为设计垂直领域 Agent 的 Lovart,生态占位在两者之间,既没有把能力描绘得过于星辰大海,又在垂直领域有着深入却不拘束的思考。
此前也有一些所谓的行业 Agent 产品,简简单单接入几个 MCP 和行业知识库就急匆匆推出来了。但实际用下来就发现产品设计中只有理论性的逻辑可行性推导,却很少关注到用户真正的痛点。看起来很厉害,用下来不好用。
Lovart 的使用感受跟它们完全不一样,在使用过程中,我可以明显感知到它在帮我解决之前独立使用生图工具时让我觉得繁琐或者难受的点。比如在 LLM 和生图模型之间来回跳转调试 Prompt,比如 GPT-4o 生成了一张很满意的图片唯独几个文字出现乱码……
借用藏师傅@歸藏的 AI 工具箱的一张图,给大家展示一下它的基础功能。

我本人是从事广告营销行业,所以就整点典型的商业应用案例。
我们结合着实测案例,边做边说。
既然是「专业设计」Agent,咱们先来点专业又值钱的——品牌视觉设计。
一般企业找专业的设计公司,别说做一整套 VI 了,设计个 LOGO 可能就要花费几千到上万元不等。
我就先让 Lovart根据我的名字首字母 LQ,给我设计个有科技感的专属 LOGO。
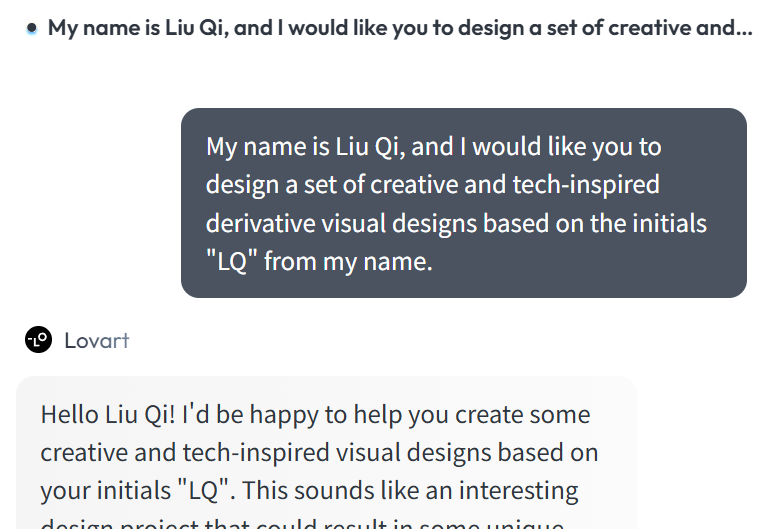
Lovart 在任务执行过程中会自动调度 Claude、GPT、Gemini 等等大语言和 GPT-image-1、Flux.1、Imagen3 等等生图模型,还有可灵、Suno 这些视频与音乐生成模型,为了让任务涉及的所有模型协同顺畅,提高效果的稳定性,建议使用英文撰写 Prompt。但文章中为了便于大家理解,我就直接开启沉浸式翻译进行演示了。
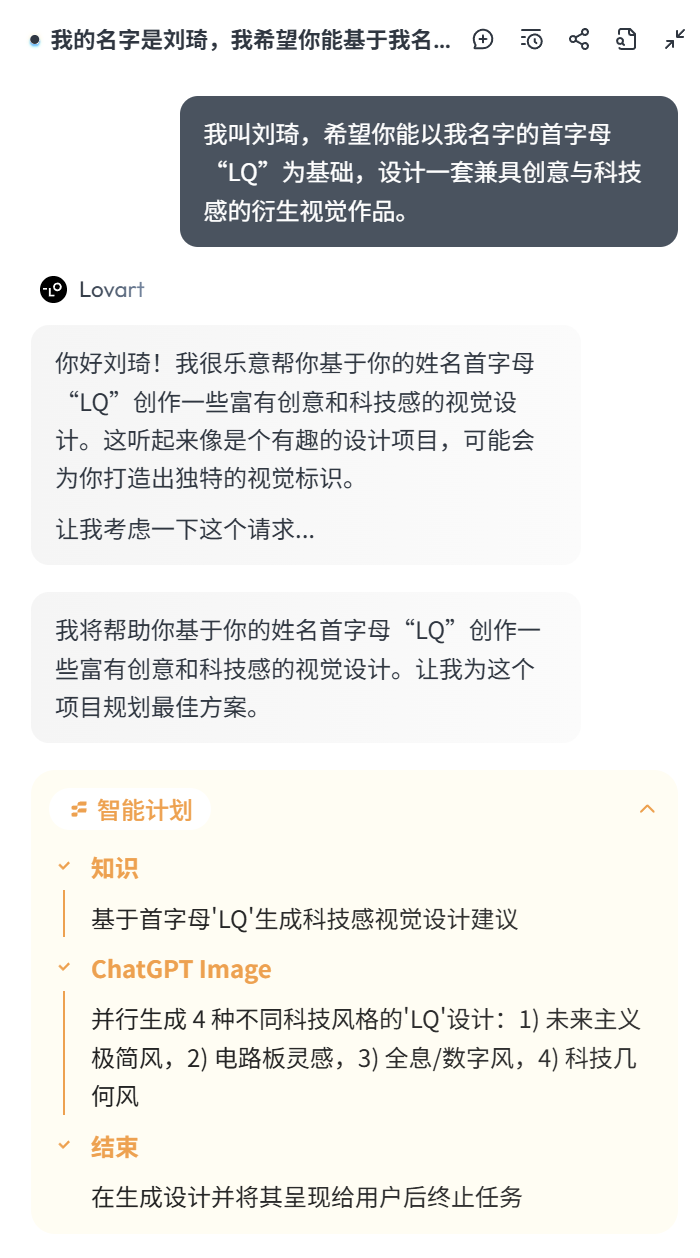
可以看到,它在接到我的任务后,会先把任务进行拆解,进行一个整体的智能规划。
让我十分欣赏的一点是,Lovart 每次接到任务需求后,总是会先确保自己对任务需求足够理解。第一项分任务,永远是提炼出我的任务需求中的重点关键词,去展开了解相关的知识。比如这个案例中,它敏锐捕获了我的任务需求中「科技感」这个词,第一步先生成科技感视觉设计建议。
这一步真的很重要,而且很多人类设计师都做不到这一点。我见过太多初级设计,拿到活儿一秒钟都不想,抡起膀子就是干,干完人家说想要的不是这样的,跟运营吵吵一顿又回去返工。
这是 Lovart 基于我的名字首字母 LQ 和「科技感」这个关键词,生成的视觉设计建议:

我自己都没想到我的名字加上科技感,能有这么多解释。
然后,它基于前面规划出的四种风格,结合上面生成的视觉设计建议知识,调用 ChatGPT 生图,给我生成了四个 LOGO:

还不赖。
而且确实是有科技感在里面,并且带着科技感的同时衍生了四种不同的风格,比之前网上那些 AI 设计 LOGO 网站效果好不少。这就是第一步做背景知识拆解的好处。
这四个 LOGO 里面我真的挺喜欢第二个创意的。
但第二个的问题是元素有点过于复杂了,PCB 板上还加了电阻,R1、R2 字母标注得好像也不太对劲,这样实际应用起来就很受限。于是我引用了这张图片,向 Lovart 下达了进一步的要求:
基于电路板这个设计创建一个更简化版的 LOGO。
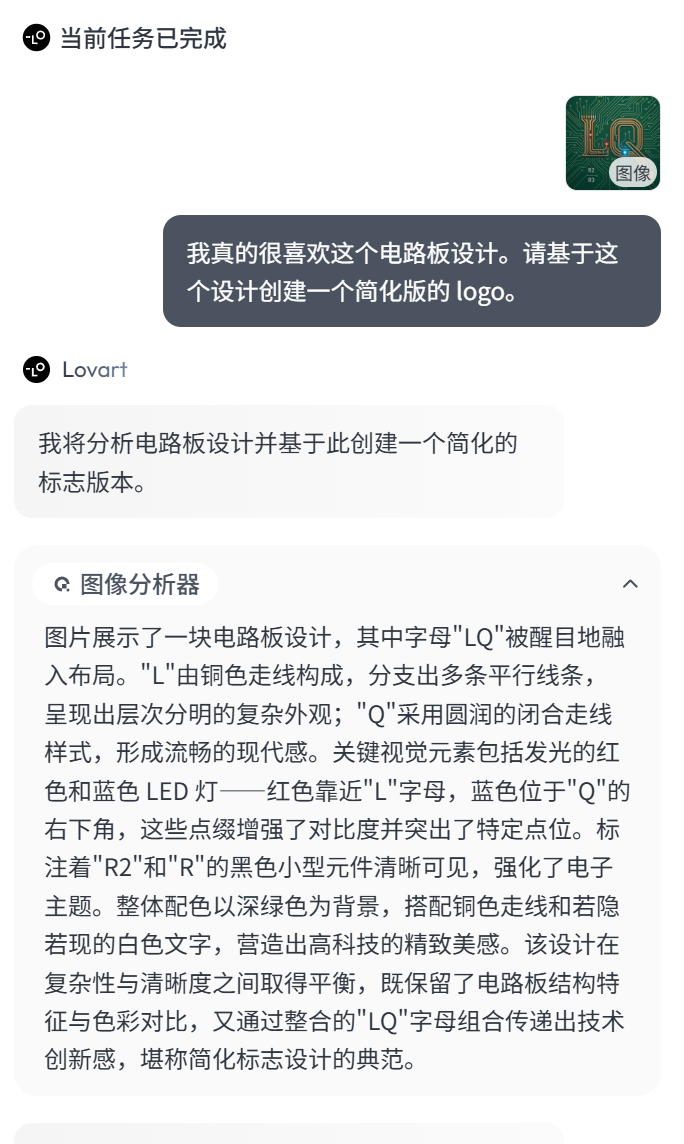
可以看到,这时候它调用了「图像分析器」拆解了这张图。这个能力倒不稀奇,就是调用了支持多模态识别的大模型,不过从拆解结果来看,内置的 Prompt 应该是基于设计场景专门调教过的,对小白选手比较友好。
之后的流程跟刚才一样,分步智能规划,第一步生成知识建议,第二步调用 ChatGPT 生图。

不得不说,第一步进行知识生成这个功能设计是真的好,大语言模型和生图模型的能力在同一个产品内有机结合,内置 Prompt 设计也很棒。
然后我得到了一个简化版 LOGO,可以跟上面的版本对比下,我觉得还不错:

我决定再给它上点难度,让它根据我的 LOGO,给我设计一套游戏装备品牌的 VI 出来。
依旧是先进行智能计划分解再执行。注意这里我没有引用生成的图片,它也能通过智能上下文分析判断出应该基于简化版的 LOGO 制作。
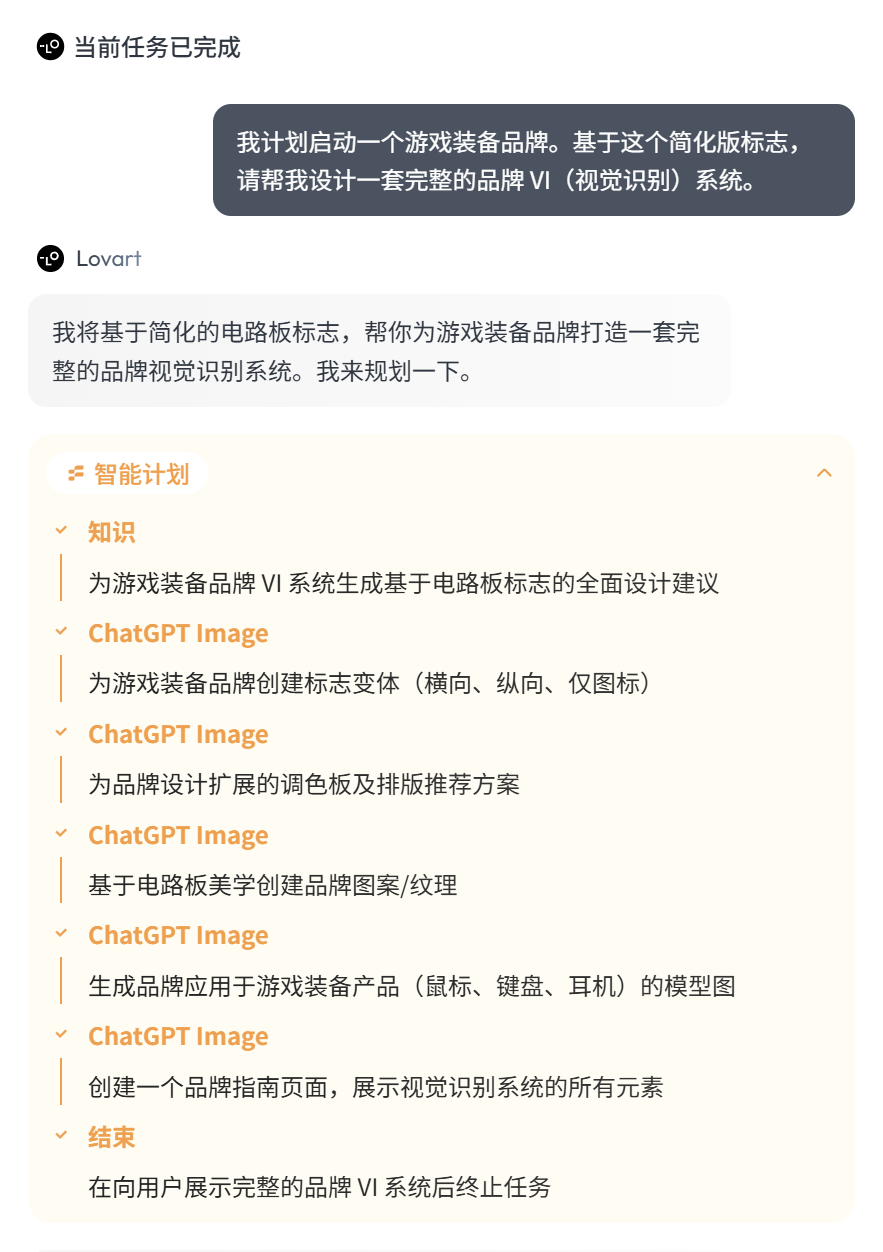
我真的很喜欢看它这个「知识」部分。
方案出的贼细致,直接拿去给设计师参考也足够了。

这一步其实有些瑕疵。
尤其是最后一张图,LOGO 的变体一致性没有保持好。
对于一套专业 VI 来说,GPT-image-1 模型输出的图片一致性还是不太够的。
真要落地使用,还是得再人工精校调整一下。
不过作为 demo 算是比较可用的了。

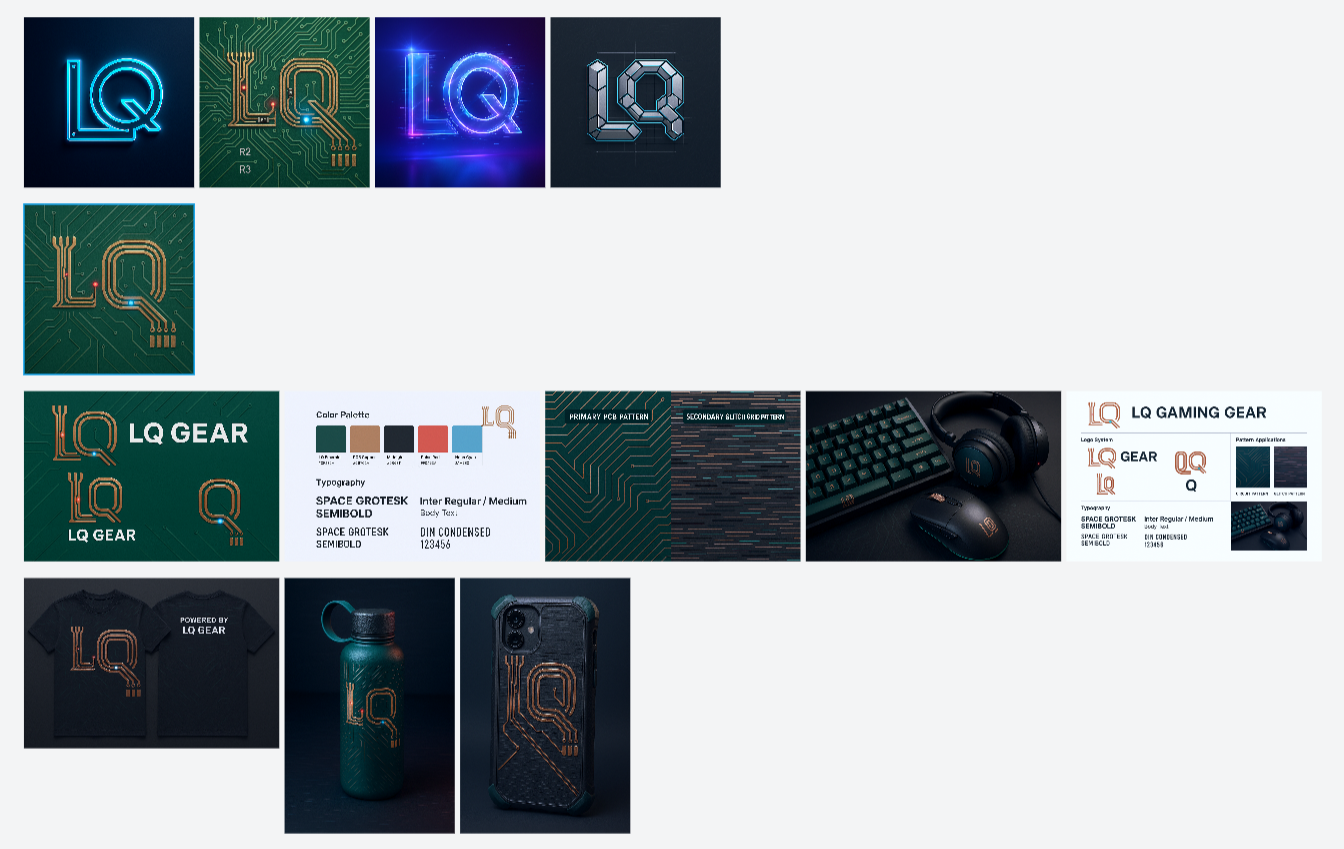
接下来,我又让它基于我这套 VI,给我的品牌设计了一些周边。
过程细节就不放了,最终结果是这样:

整体上我还是比较满意的。
这一整套流程下来,一个刚刚起步的创业者,可以在不花费太多预算的情况下,拿到一个看着 OK,用起来也马马虎虎够用的品牌视觉设计,我觉得还是挺不错的。
全自动视频生成也是一个非常有优势的 Agent 场景。
AI 视频制作是一个典型的多平台来回切换的工作流,通常我们制作 AI 视频的典型路径是在飞书写脚本和故事板,用 Midjourney 或者 Flux.1 生图,然后到可灵、Runway 这样的视频生成平台进行图生视频,最后再配音配乐。一顿乱串,手忙脚乱。
Lovart 的多模型调度能力很好地解决了这个问题,一句话的 Prompt,从脚本规划、图片生成、故事板创建、视频生成、音乐生成到最后的成品合并,能够直接搞定。小型商家或者企业简单的宣传需求,就可以由店长或运营人员独立完成,而不需要额外的外部支持。
例如,我作为一个珠宝商人,可以要求 Lovart 参考照片,为我的珍珠耳环制作一个配有 BGM 的宣传短视频。

跟生图的流程类似,Lovart 首先会结合我的要求(比如不要出现人物)调用大语言模型生成「故事知识」,其中包括场景和分镜头脚本。

之后就是根据分镜头脚本生成图片。
这里值得一提的是,生图过程中,它会自动根据 LLM 的分析匹配,在风格库中选取适合的 Lora 使用。
不过我这个任务有上传参考图,并且特别要求了不要包含人物,所以实际生成图片时使用的模型是 GPT-image-1,而没有使用 Flux.1,Lora 并没有生效。
你也可以同步要求它把这个脚本制作成一个像这样的故事板。
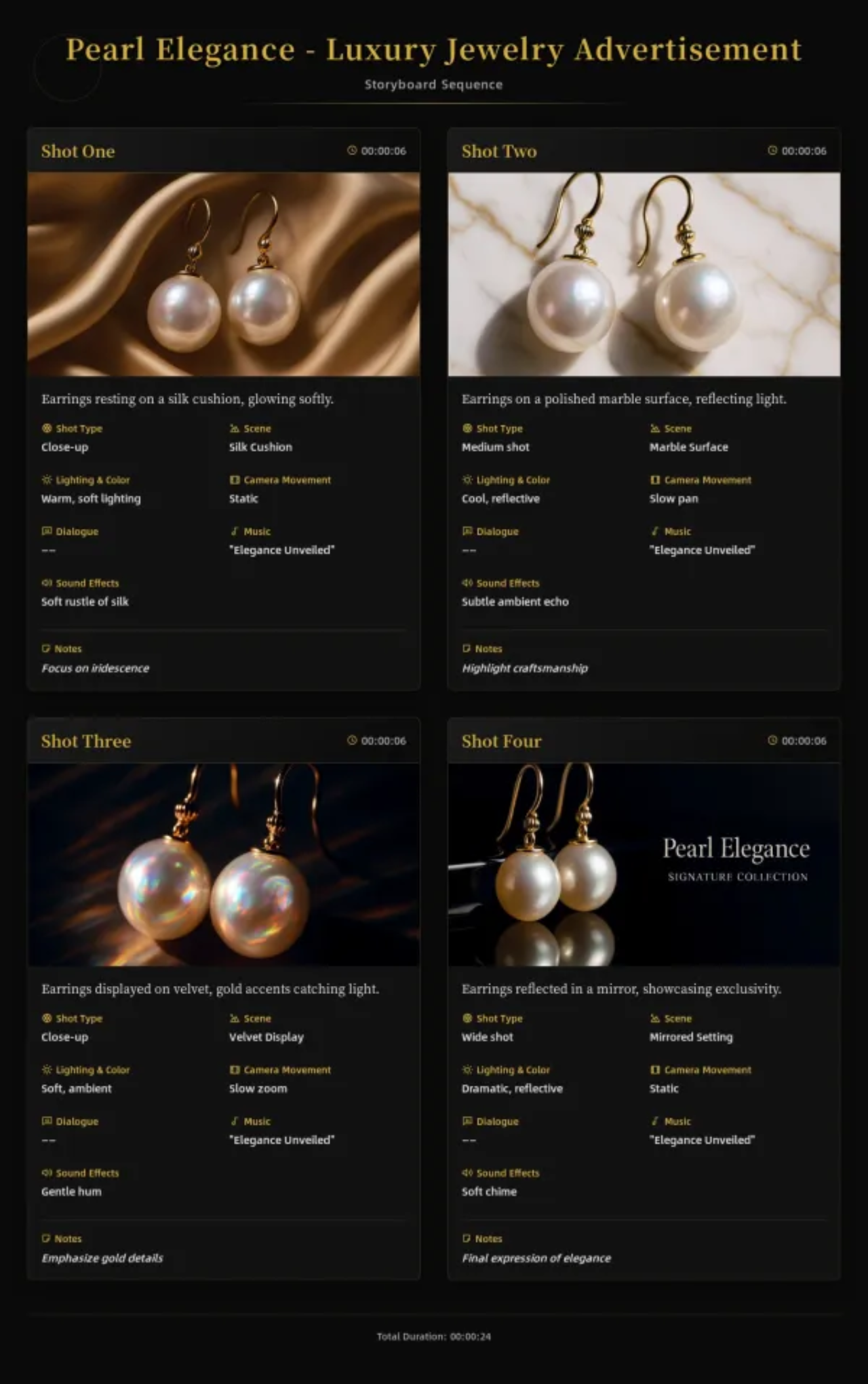
之后根据故事板的内容,调用 Suno AI 生成背景音乐,调用可灵 1.6 生成每一个镜头,最后将所有分镜头视频和 BGM 合并,得到完整的宣传片。
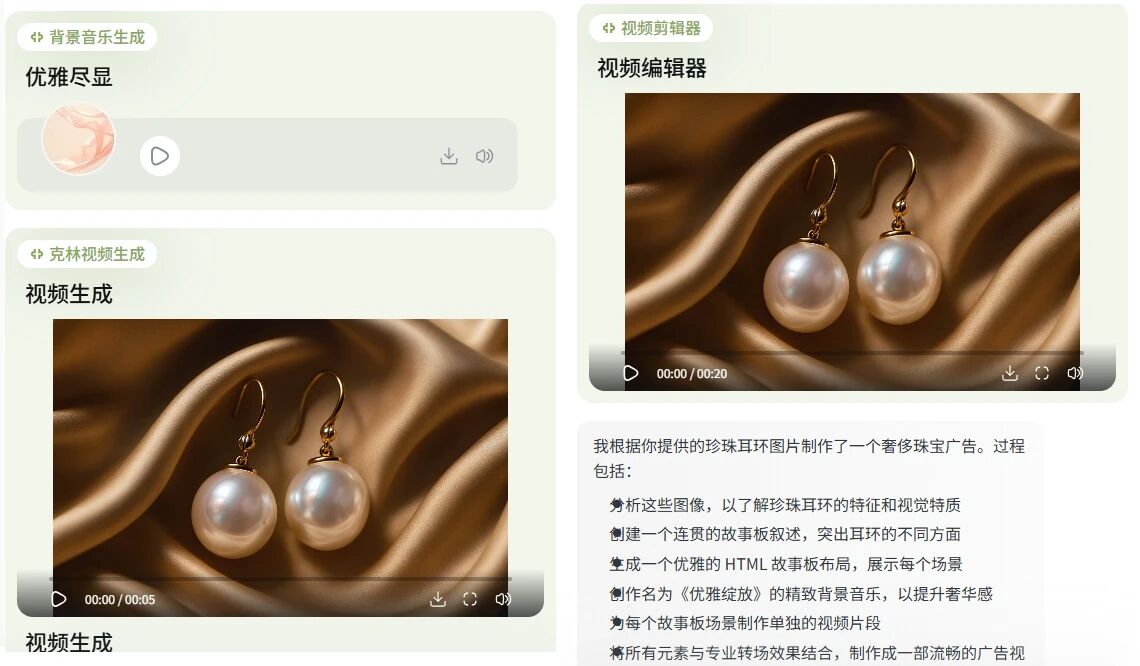
最终生成的视频如下所示:
高贵奢华的气质确实有拿捏到。
不过,虽然我认为全自动视频生成是一个非常有优势的 Agent 场景,但从目前 Lovart 的实测表现来看,这也是提升空间最大的一个场景。
值得肯定的是它的易用性够高,且方向十分正确,生成一段合格的成品 AI 视频的门槛大大降低。像我上面的示例一样的小型电商产品视频,其实足够小型商家投入商业应用了。但是一定程度上还是受限于当前大模型的能力,比如脚本不够有创意,分镜场景不够连贯等等。如果是要生成一段优秀的 AI 视频作品,从脚本到生成,依旧需要大量的人类介入调整。
但随着大模型能力的提升,未来可期。
再说说打工人日常场景的应用。
譬如说,现在我的老板让我发一篇小红书笔记,并给到我一份封面参考:

但是,主题需要改成求职指南。
于是,我就直接把这张图片发给 Lovart,告诉它:参考这张图片的风格,帮我设计一个求职指南的封面。
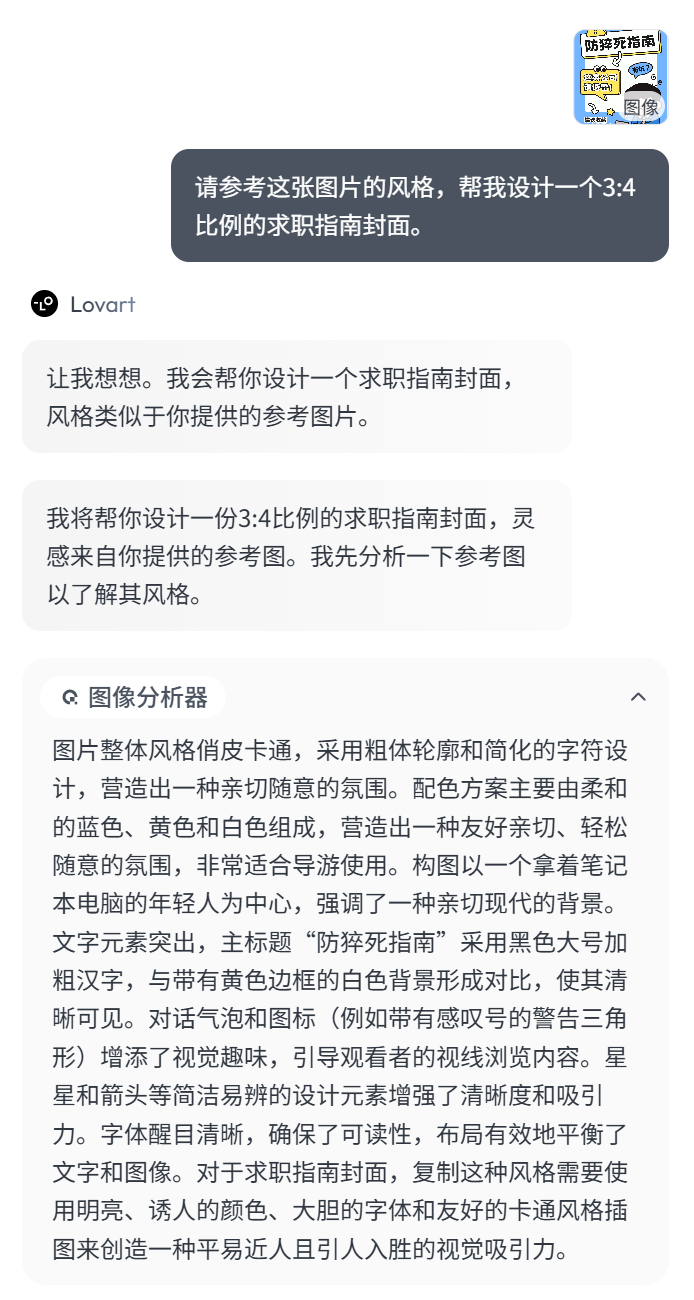
Lovart 依旧是先进行了图像分析,然后拆解执行步骤,根据求职智能的主题,设计了这张封面图的整体基调。

然后,通过 GPT-image-1 生成了封面结果。
细节:当主题从「防猝死」变为「求职」的时候,图中小人的表情和情绪氛围都进行了调整。

但是有一个问题,我们现在生成的这张图片的文案是中英文夹杂的。
而且,熟悉 GPT-4o 生图的朋友都应该有一个很难受的点:图片结果明明是满意的,但文案上就是有几处小瑕疵或者错别字。但偏偏图片生成的结果就是一整张图,没有办法修改。而 GPT-4o 的局部重绘又不好用,对文字的重绘尤其差。文字背景是白底还好,如果恰好在图片元素上,擦除重绘都很难。这就导致很多时候明明很满意的图片最终不得不放弃掉,重新生成。
N 久以前我就一直吐槽 GPT-4o 这个问题,表示它要是能分两个图层输出就好了。

没想到在 Lovart 实现了。
只需要选中图片按 Tab 键,输入「turn into editable text version」,就可以把图片的文本和图像图层分离。
并且文本是可以编辑的。

当然也可以像我的习惯一样。直接删掉文字获取底图,直接使用 PS 或即梦生成文字再进行合并。

几乎是 1:1 复刻,背景完美保留,文字自定义权交给自己。
这个真是太绝了,精准命中 GPT-4o 生图用户的痛点。
但据我观察,这功能的实现实际上还是进行了重绘,颜色和一些细节会有不同。不过不像 GPT-4o 自己重绘一样,难以保持一致性,有点像运用了类似 controlnet 一样的技术,应该是自研。
多模型 All in One 调度的 Agent 优势就在这里,直接在同一个窗口就把问题解决,不需要像从前那样在 LLM、闭源生图和 ComfyfUI 直接来回切换,效率提高了不少。
也可以直接在开头就要求生成可编辑的版本,例如像我这样:
「Create a Children’s Day (June 1st) themed poster with text and images,and provide me with an editable text version.」
获得一份完整海报的同时还获得了一份可编辑的版本。

直接通过 Lovart 就可以进行编辑。
另外 Lovart 在设计图输出上还有一个值得一提的强力优势,那就是支持批量输出,有点像之前豆包爆火的超级创意功能。
例如还是上面那个珠宝店的镇店之宝珍珠耳环,我准备为它办一个展览,展览的宣传海报就可以用 Lovart 生成。
直接来一把 10 连抽:
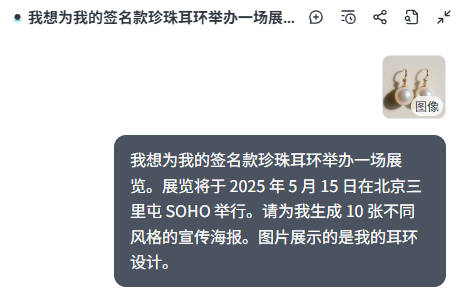
它会参考内置的海报数据库,按我的要求进行 10 张风格不同的输出。
10 张海报,每一张的风格都不相同:

其实对于常规的运营类场景来说,本身在创意设计层面的要求没有那么高,所以在这个层面上并不会比之前在多个 AI 工具之间来回切换的产出效果优秀太多。
但注意,如果是按照从前的流程,让我来完成这一类的封面或海报制作,我一般会借助大语言模型对话,或者批量处理的时候借助多维表格工具。如果出现文字瑕疵,则会通过多次抽卡来解决。Lovart 恰好就解决了这个问题:多模型 All in One 调度的优势和图文分离编辑的能力,再加上单次任务批量抽卡,会给效率带来极大提升。这对于日常运营工作来说,反而是比创意更大的杀手锏。
综合体验下来,Lovart 是一个相当值得体验的产品。
我能感受得出,他们团队对于设计领域的 AI 工作流和用户痛点是有深入研究和深度思考的,确实跟之前用过的一些带有技术迷恋味儿的「AI 改造世界」的产品不太一样。
或许扎进垂直领域,脚踏实地摸索 AI 应用,才是未来一段时间内 AI 产品的新出路。
发表回复