前几天阿里发布了Qwen3,这所有消息里,最吸引我的一条是:
Qwen3-4B可追平上代开源超大杯Qwen2.5-72B
没错,作为一个单纯的使用者,我对这次Qwen3的小模更感兴趣。
Qwen3-235B-A22B虽然说性能也强,登顶全球开源榜首,瑞思拜,但我本地部署不了呀。要说直接线上用,对最近集齐了GPT、Claude、Gemini御三家+Cursor会员的我来说,吸引力也不大。
而小模性能的提升,意味着个人本地部署可行性的提升。能本地部署就意味着数据离线私有化和无限量的tokens,成功勾起了本4090用户的兴趣。
但这得有个前提:Qwen3小模的性能真的够看。
老读者应该记得,之前DeepSeek个人本地部署成风的时候,我是唱反调的:
因为首先DeepSeek蒸馏的那几个模型它确实不是DeepSeek,其次能部署到消费级显卡上的几个模型表现是真的挺一般,相比之下还不如用API呢。
所以,进入今天的主题,咱们看看Qwen3的小模到底咋样。
首先声明:我这次的测试场景比较主观,并不是严肃测评。相关的评分是由AI(Doubao-1.5-thinking-pro)给出,娱乐一下。
场景方面,我基于自己的使用场景选了三个,我觉得应该不小比例的普通工作党跟我的场景近似:
- 对于带有一定目的性的文案的审查和修改。
测试题目是用了10条存在问题的淘宝好评文案。
2. 对内容的总结和理解。
测试题目是在网上随机选取的10篇文章。
3. 基本问答下的逻辑和计算能力。
测试题目是在弱智吧训练集中随机选取的10个问题(带答案)。
参与测试的大模型一共10个:
- 6个是我通过Ollama在本机部署的,分别是:
qwen3:8b、qwen3:14b、qwen3:32b、qwen3:30b-a3b、deepseek-r1:8b、deepseek-r1:32b
– 4个是线上API接入,分别是:
QwQ-32B、GLM-4-Flash、DeepSeek-V3、Grok-3
裁判是Doubao-1.5-thinking-pro:
- 前两个场景,它会站在上帝视角,浏览所有选手回答后进行打分
- 弱智吧测试题,会根据标准答案进行打分
测试环境,本来准备使用CherryStudio,但后来发现回答同一个问题时模型之间会相互抄作业,所以最后还是使用了多维表格。


正好最后的完整测试题目和选手回答也方便放出来。
下面是正式的测试结果。
各10题,平均分就是求和分值除以10。
第一卷 文案分析和修改:
得分:
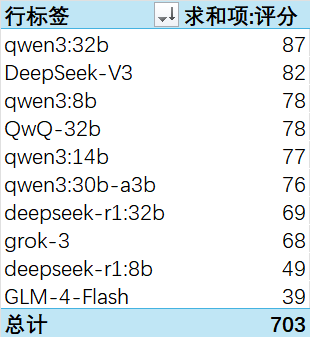
Qwen3确实表现不俗,第一卷就被32B拿了榜首。
之前DeepSeek蒸馏的两个模型——我说的也没骗人吧——排名比较靠后。
免费调用的GLM-4-Flash遗憾垫底。但为它说句公道话,你很难找到跟它一样免费不限量且高并发的API了。
第二卷文章总结和感悟:

得分:
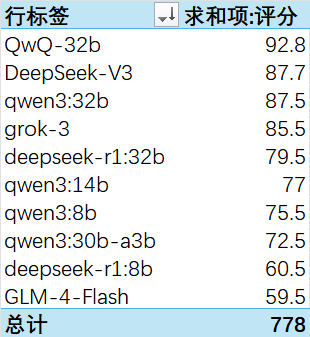
QWQ-32B拔得头筹。
DeepSeek-V3稳居第二。
上一场第一名Qwen3:32B本次名列第三。
DeepSeek蒸馏的32B(其实蒸馏的也是千问),上升到第四,8B仍然落后。
GLM-4-Flash依旧陪跑。
第三卷 弱智吧答题考试:

得分:
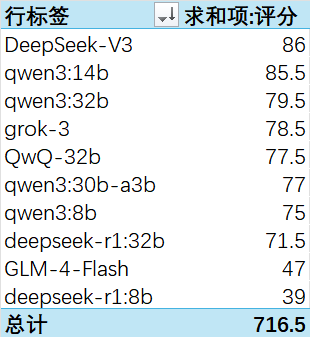
DeepSeek-V3依旧强悍(本次使用的是0324版本)。
Qwen3:14B这次怒拿第二名,32B第三,也是优等生。
DeepSeek蒸馏8B遗憾垫底,32B倒数第三。
GLM-4-Flash在弱智吧上扳回一城,保住了颜面。
最终测试结果:
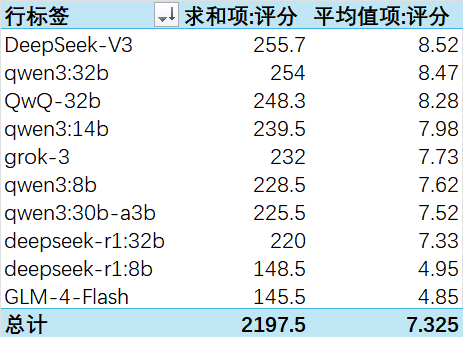
DeepSeek-V3第一名。
Qwen3:32B第二名。
QWQ-32B出乎我的意料拿到第三名。
Qwen3:30B-A3B本来我寄予厚望,不过在这几项测试上意外爆冷。
如果根据这个结果,90及以上显卡的朋友本地部署建议选择Qwen3:32B,稍差一些的14B也是不错的选择,8B也会强过之前的DeepSeek蒸馏版本。
以上完整测试问题和结果可查看链接:
https://ilovezhiwai.feishu.cn/wiki/HThDwnX0FiyTIakyDe9c2z99nef?from=from_copylink
再次重申:本测试既不科学也不严谨,仅供逗乐。请不要在严肃领域使用本次测试结论。
祝大家五一假期愉快!