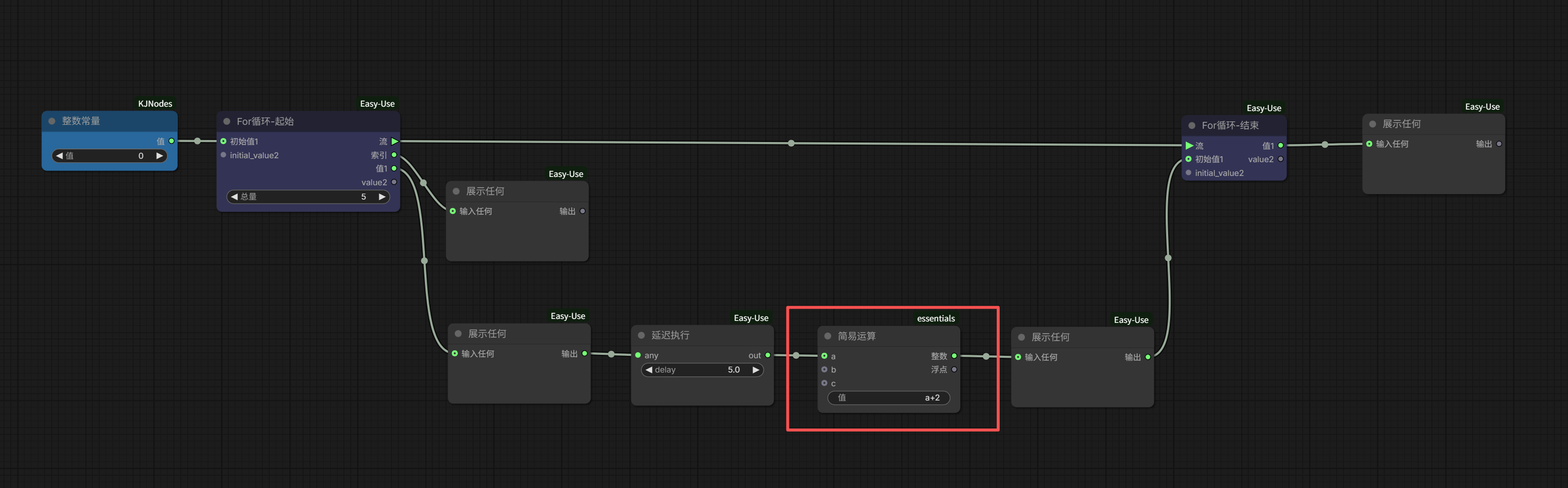
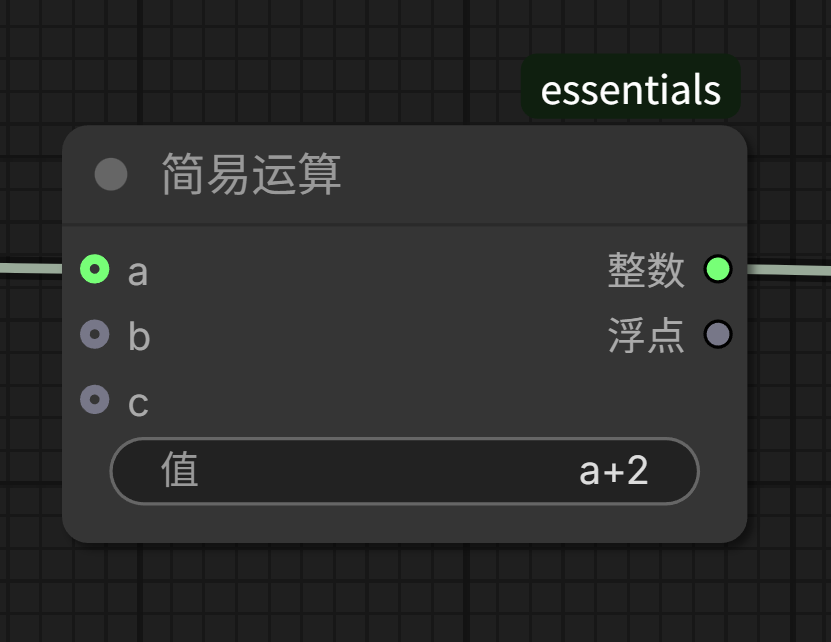
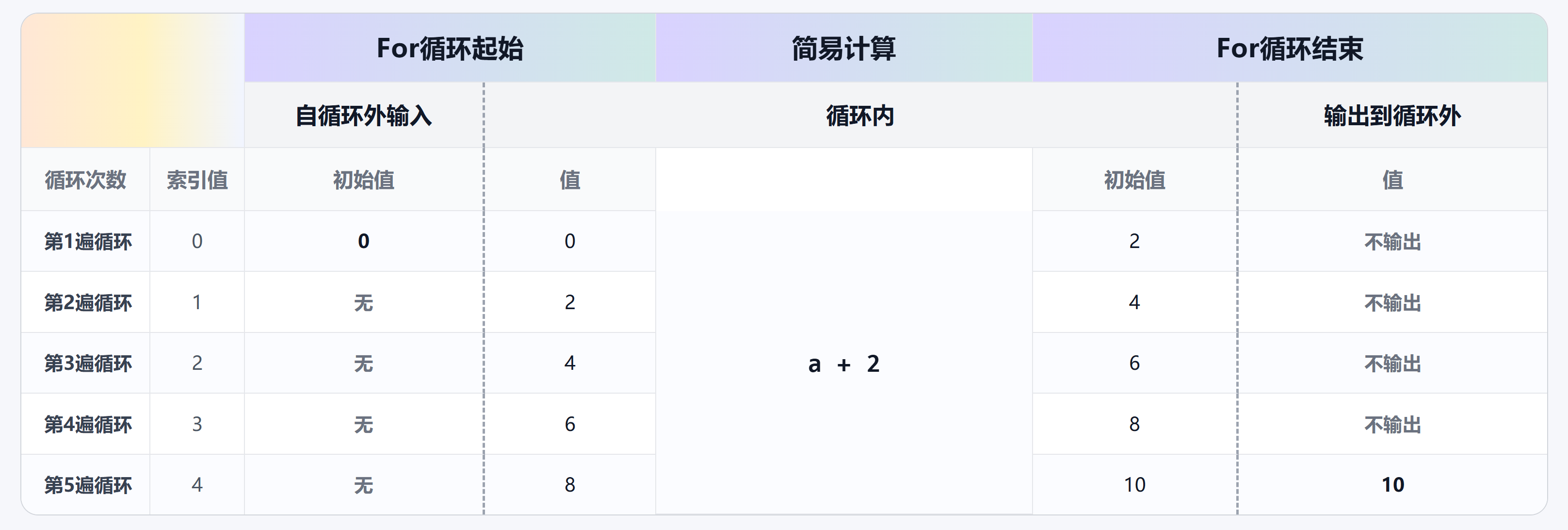
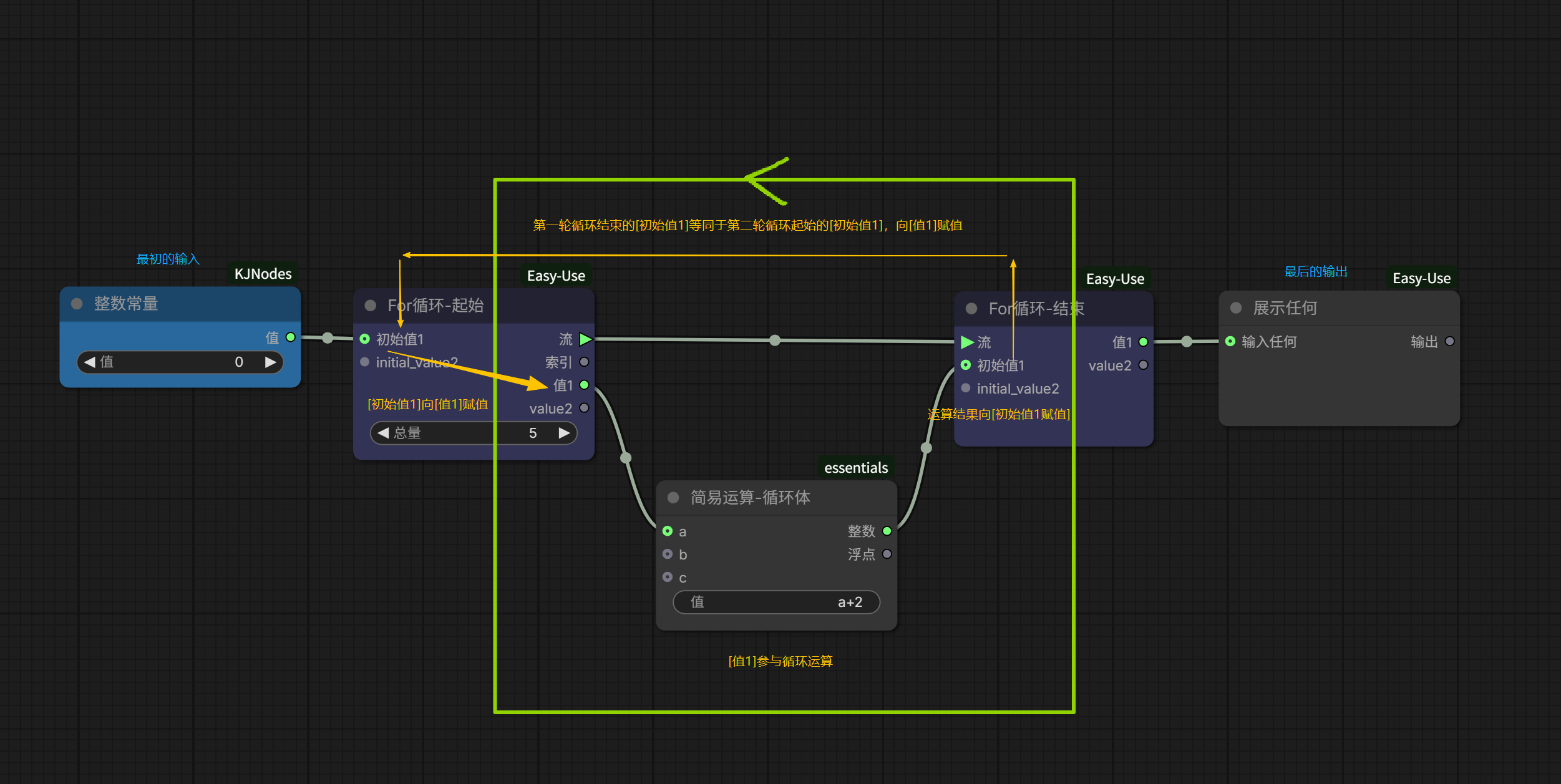
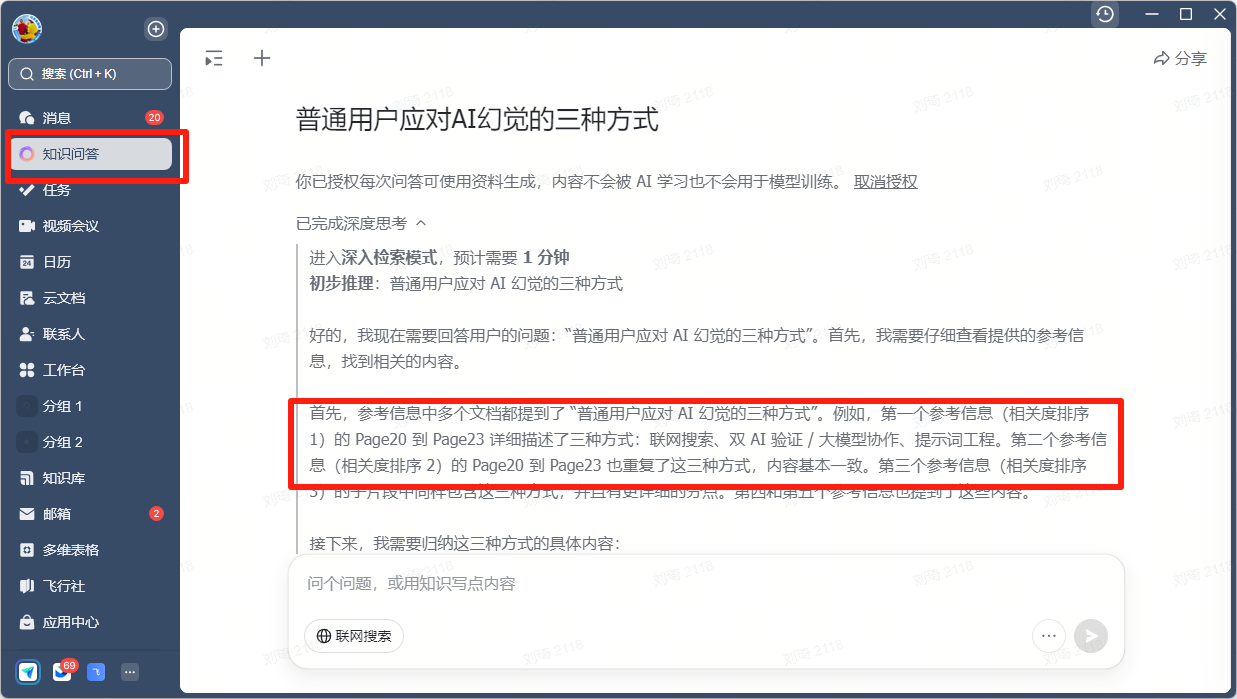
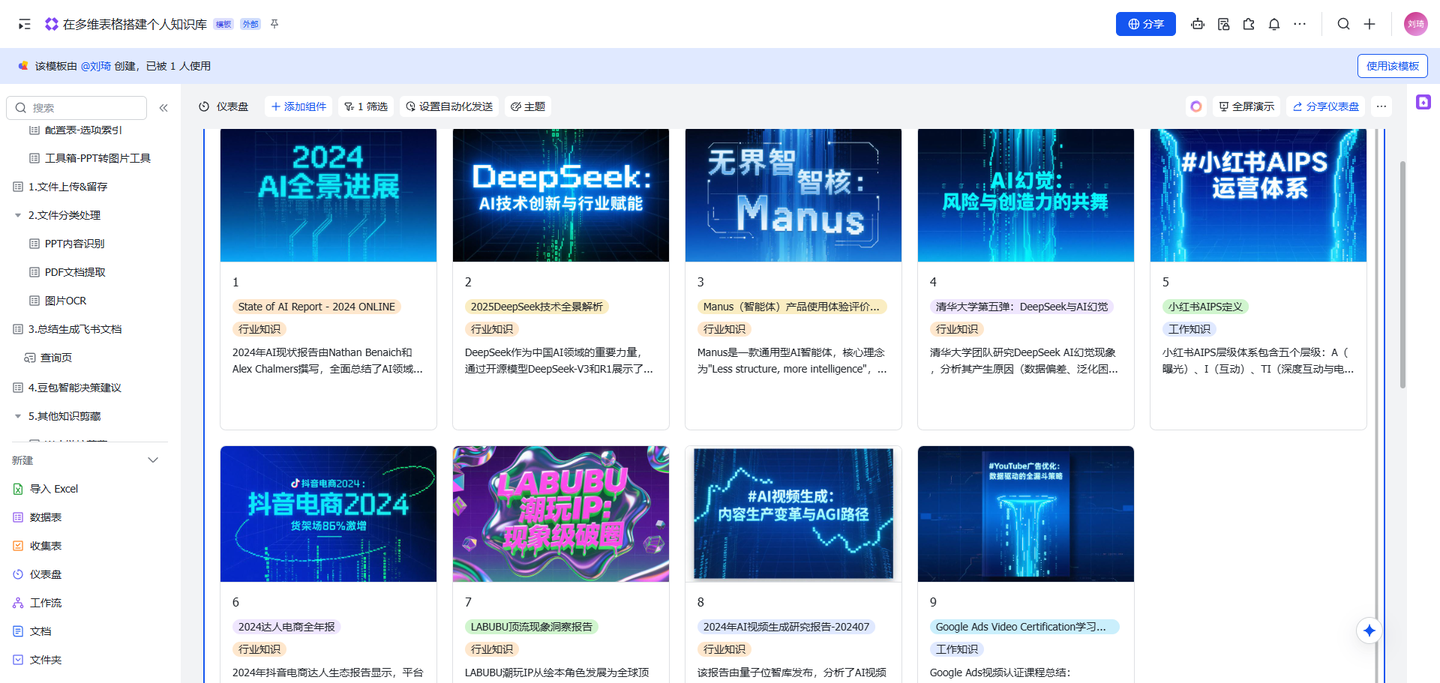
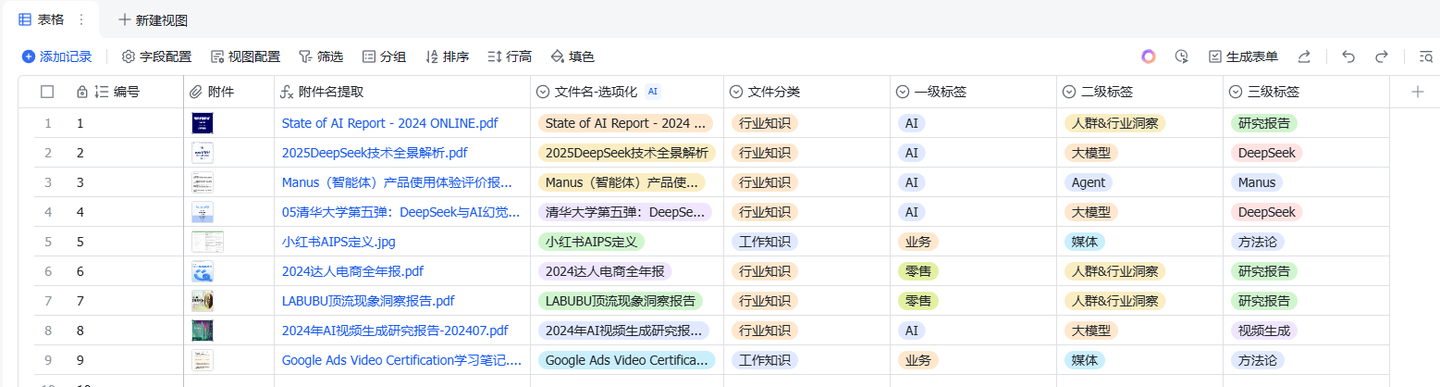
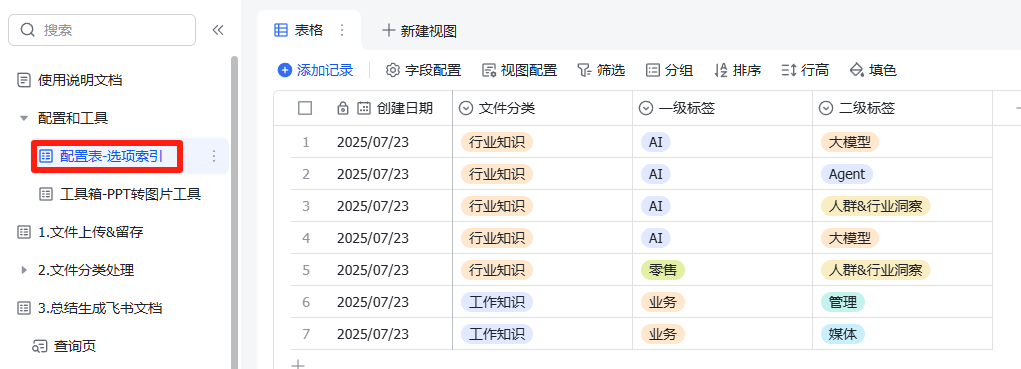
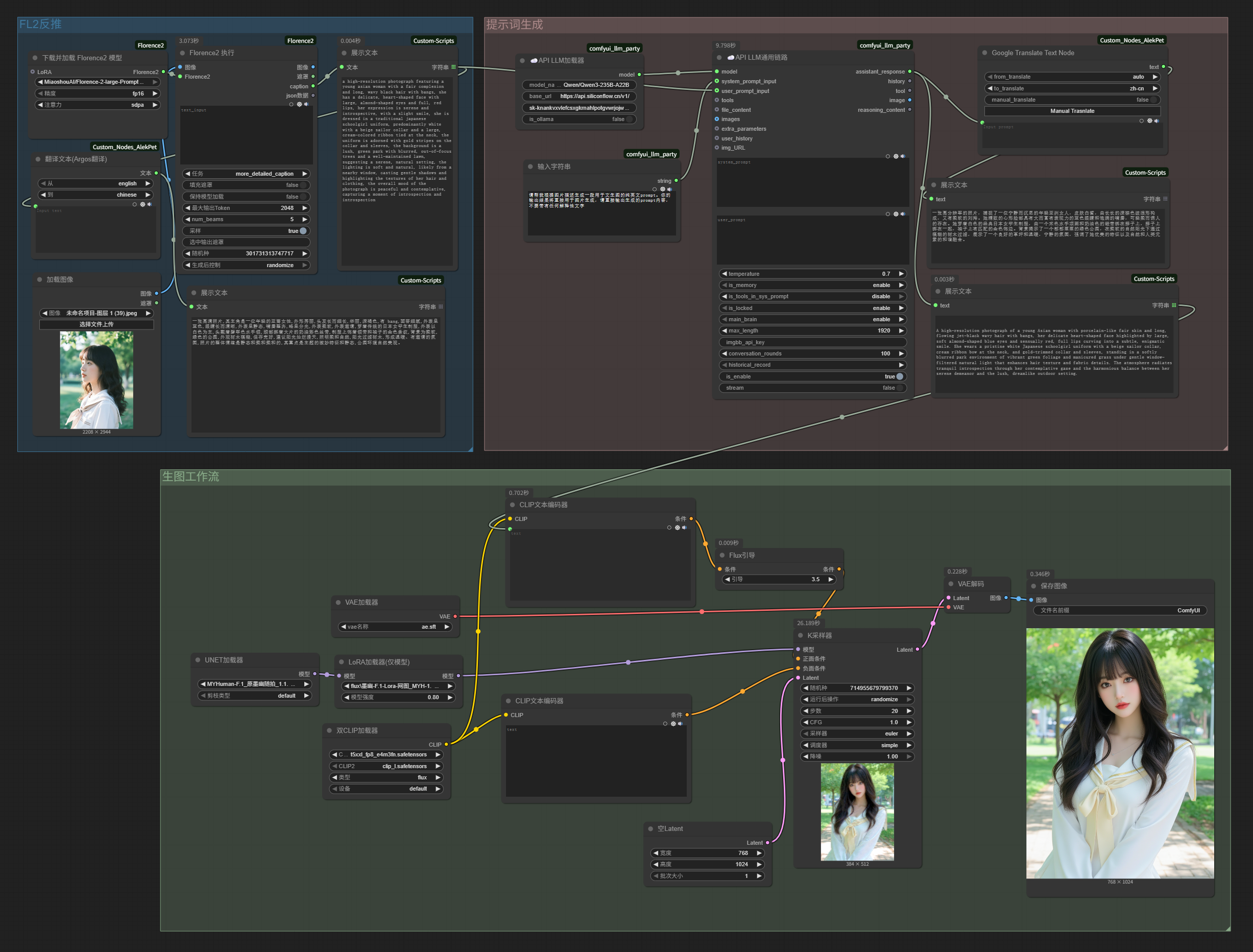
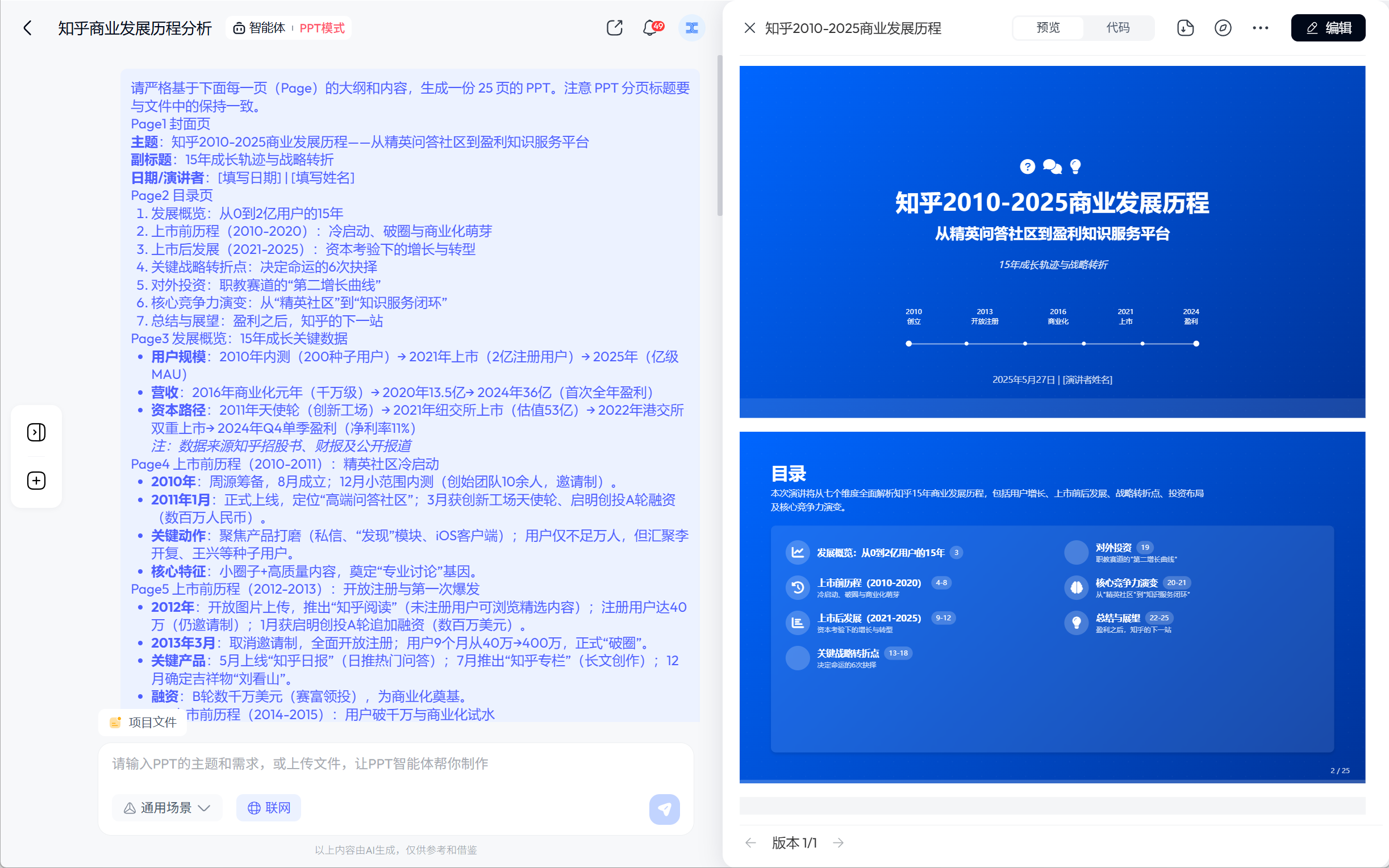
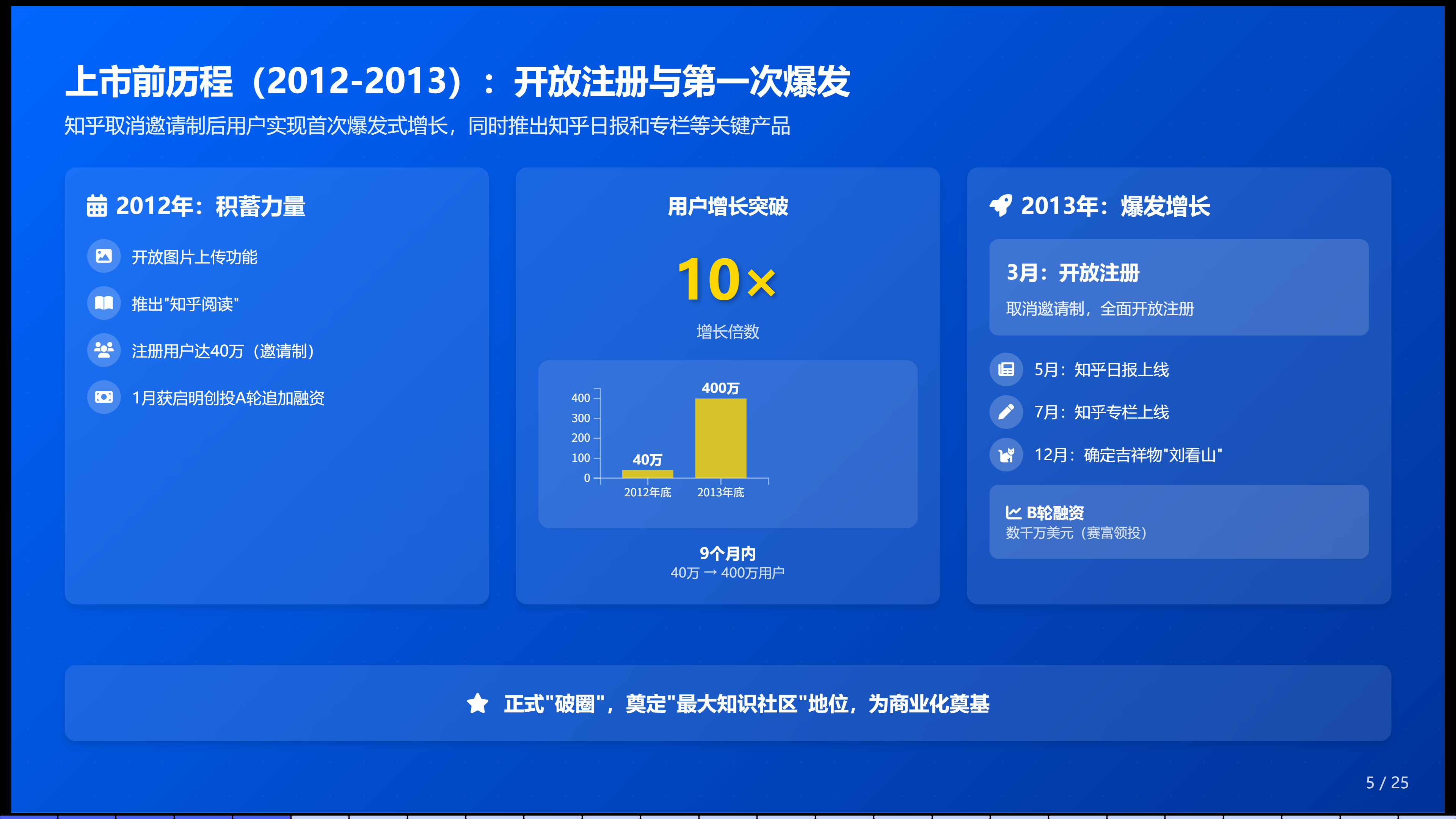
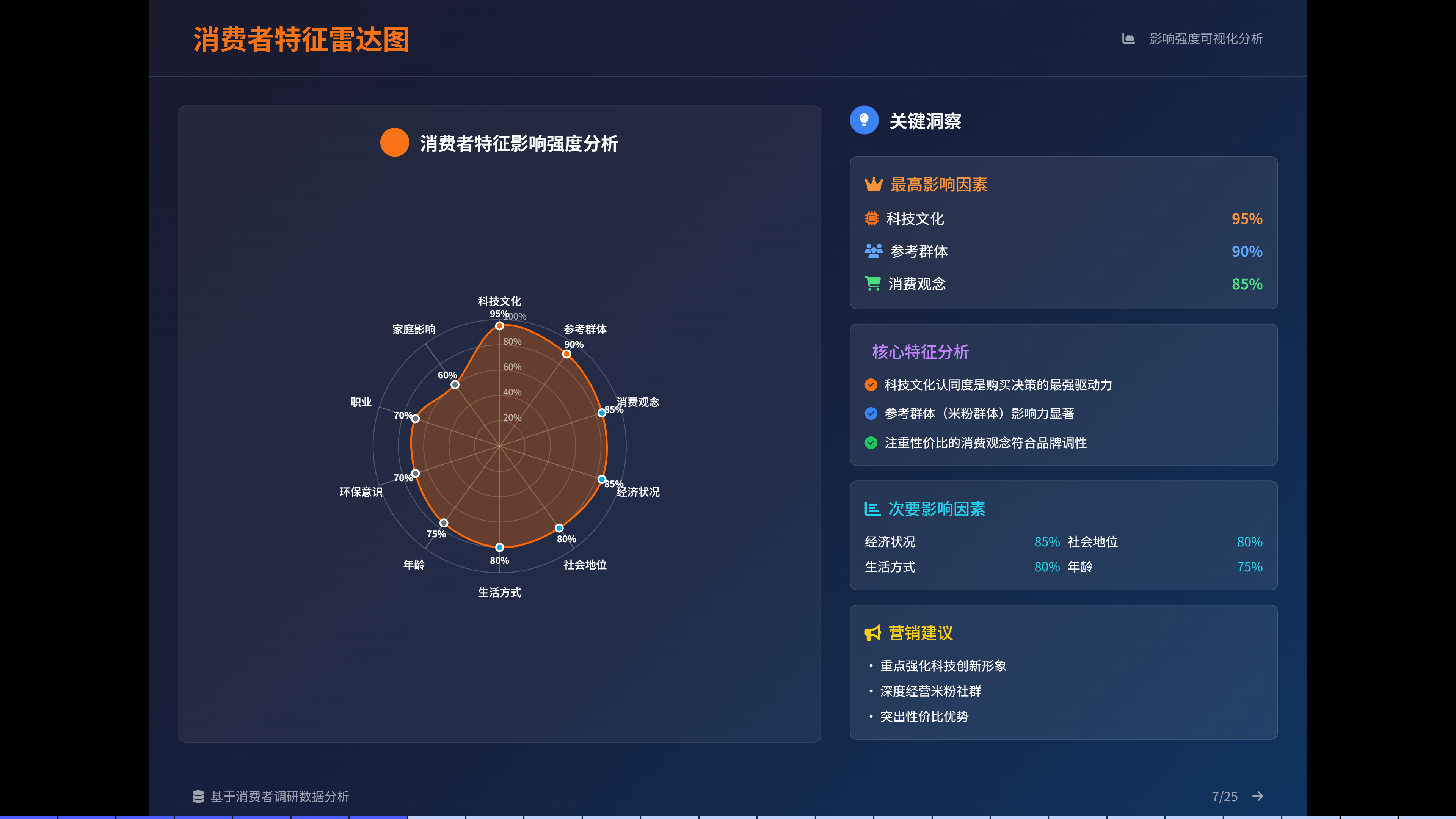
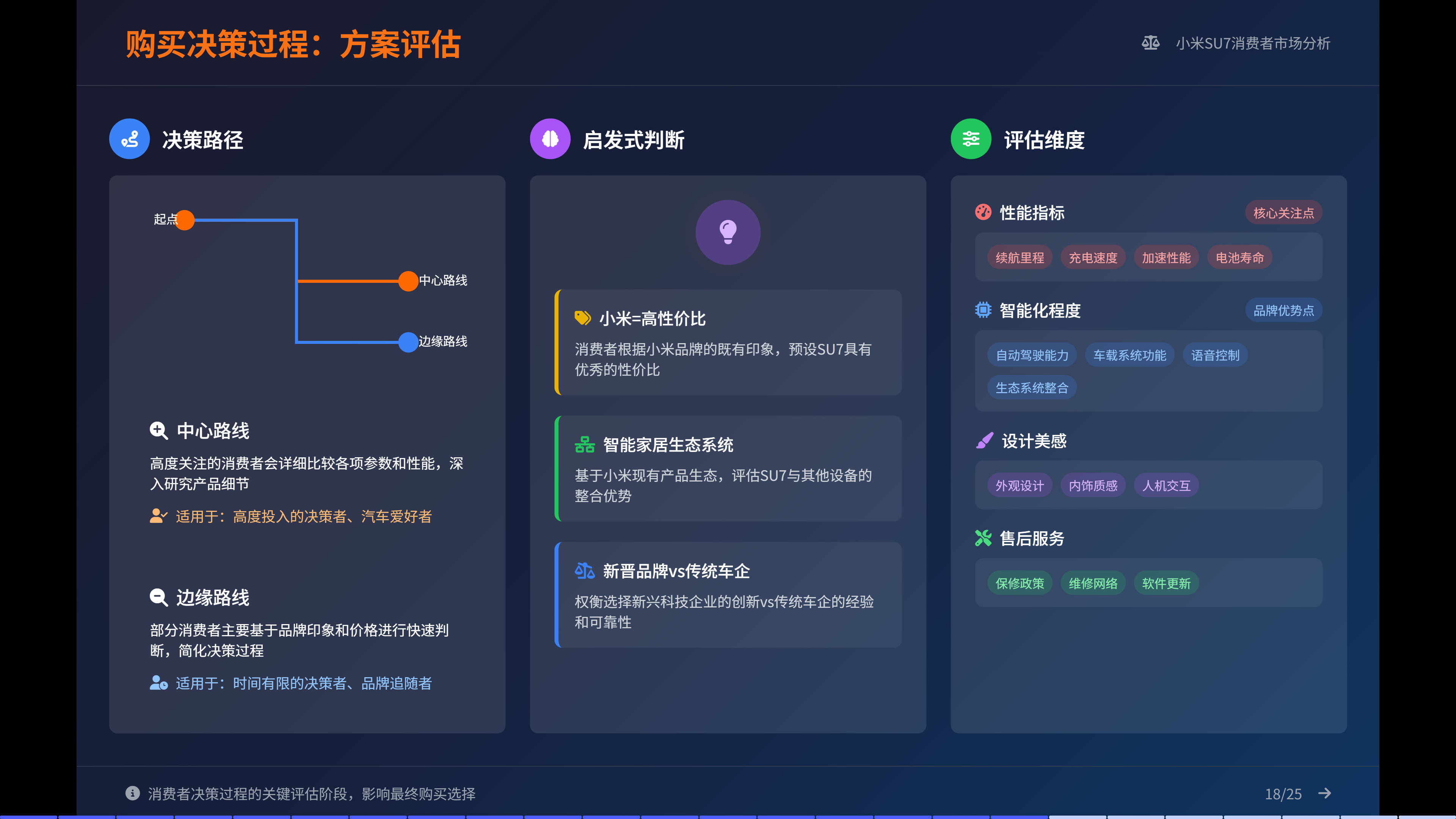
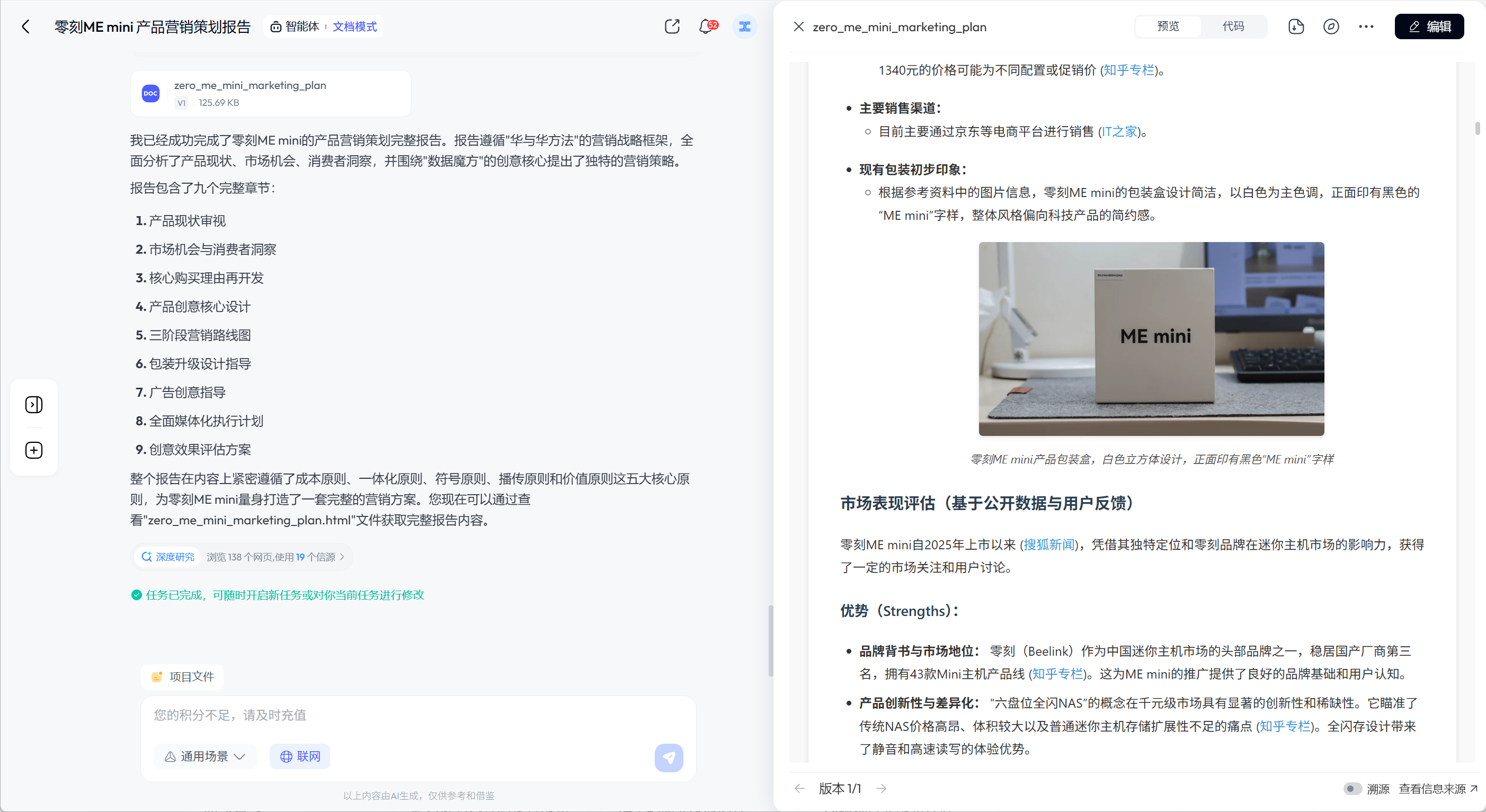
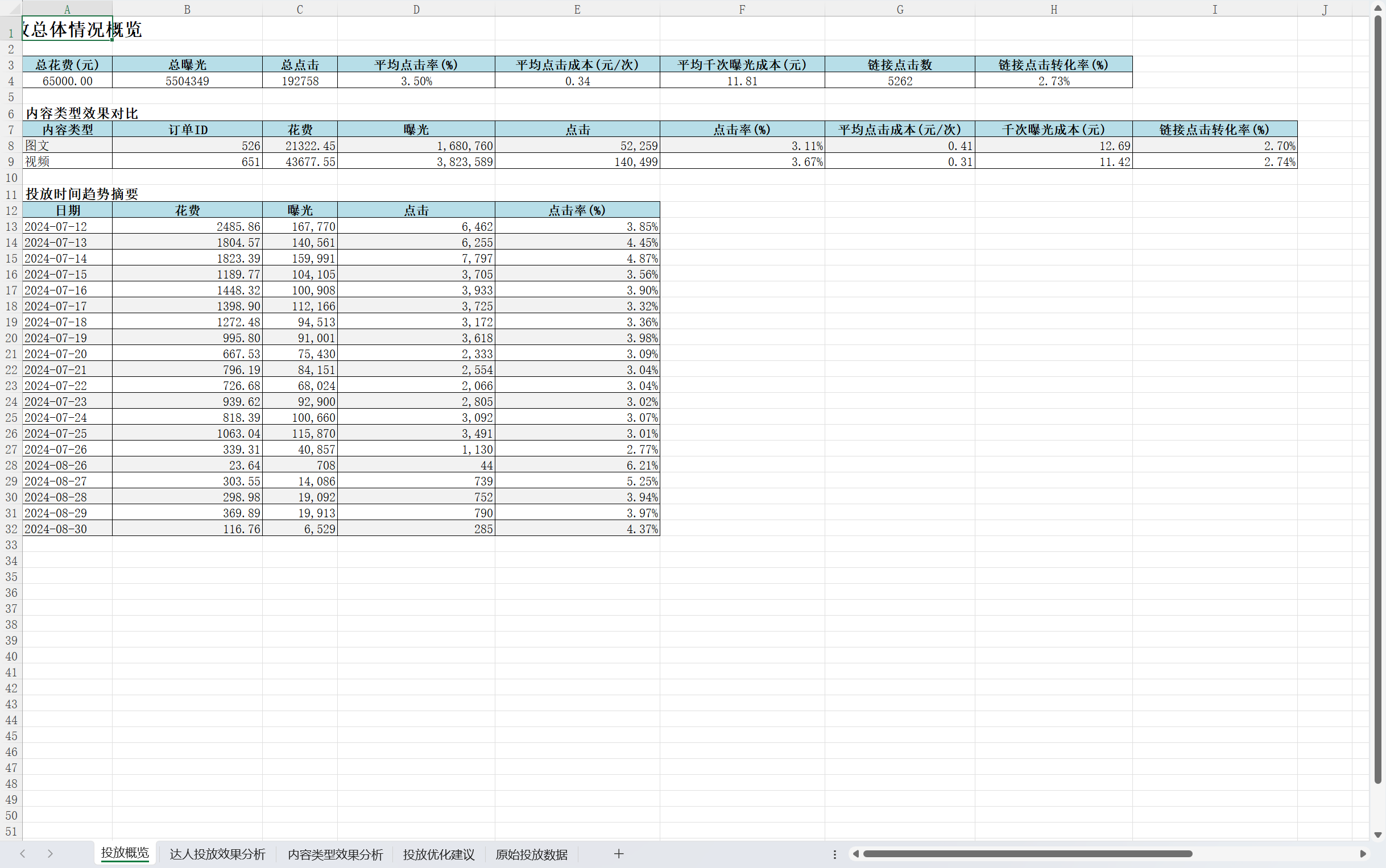
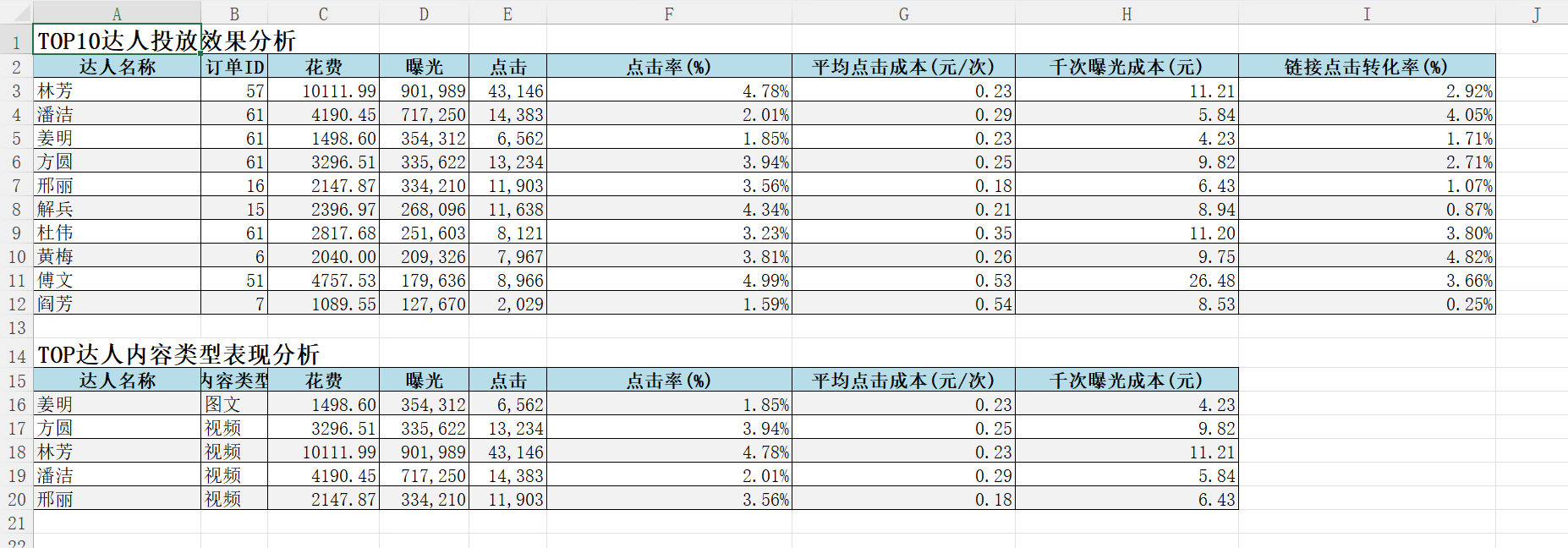
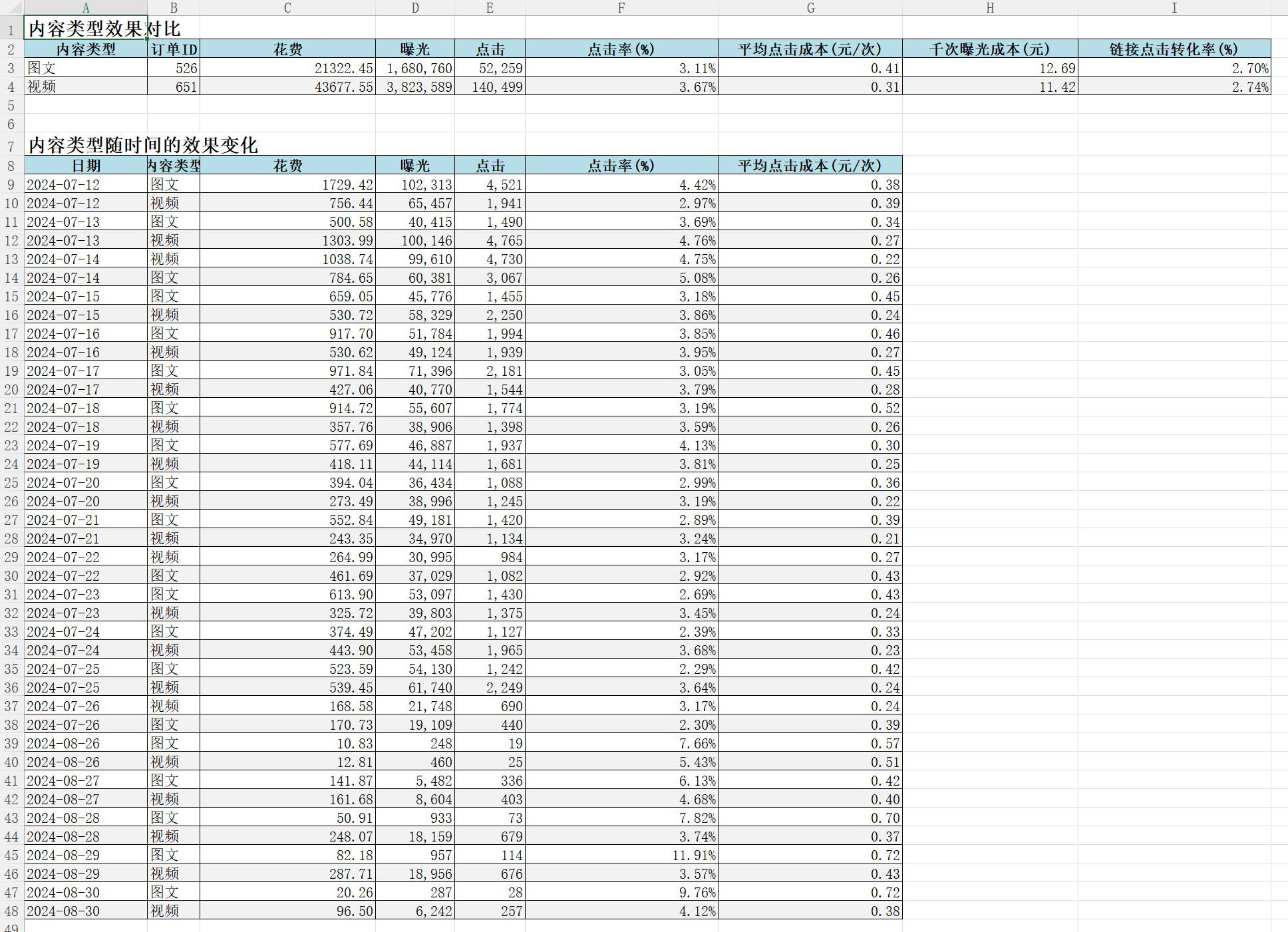
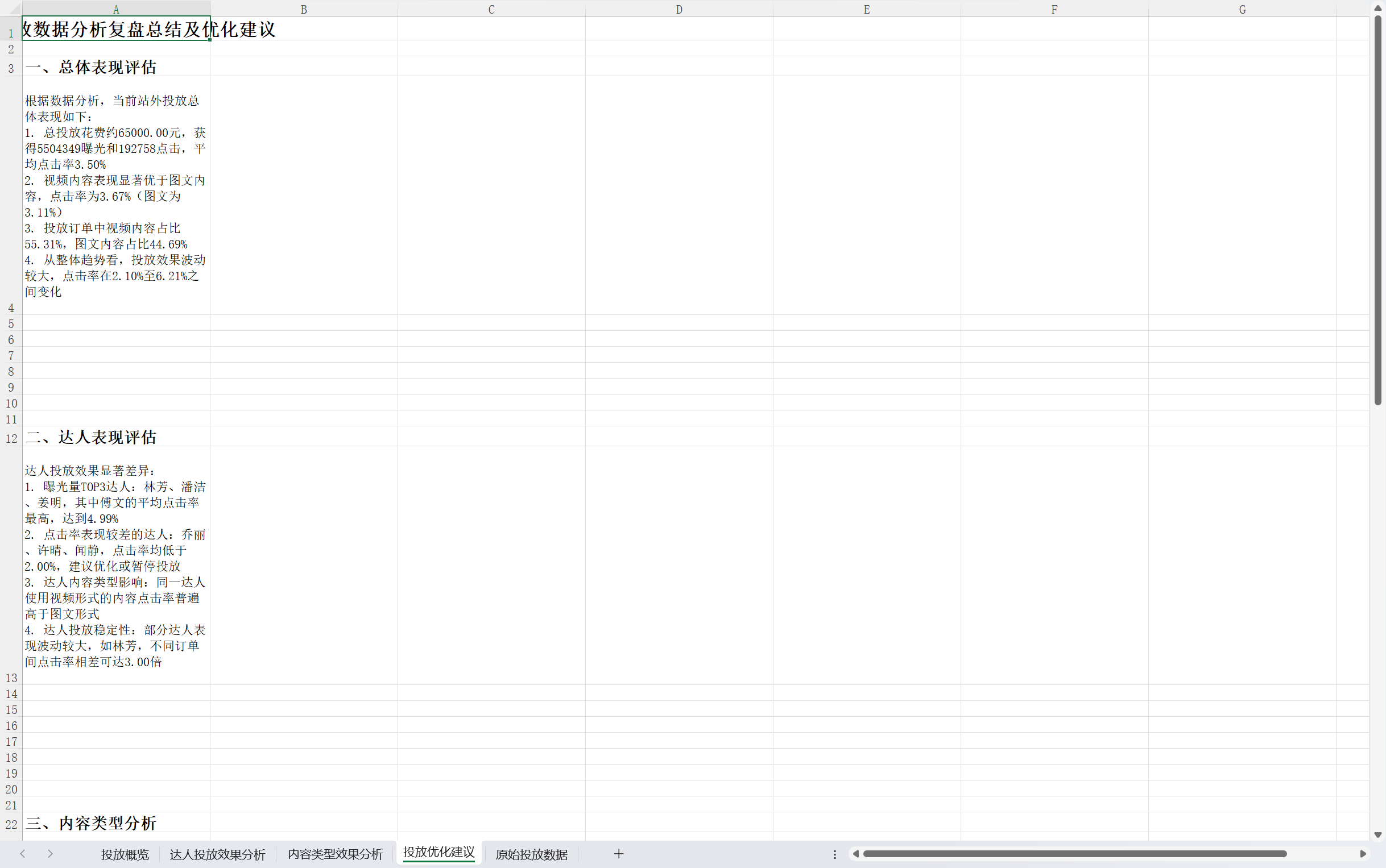
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>录音转文字</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
min-height: 100vh;
display: flex;
align-items: center;
justify-content: center;
padding: 20px;
}
.container {
background: rgba(255, 255, 255, 0.95);
backdrop-filter: blur(10px);
border-radius: 20px;
padding: 40px;
box-shadow: 0 20px 40px rgba(0, 0, 0, 0.1);
max-width: 700px;
width: 100%;
}
h1 {
text-align: center;
color: #333;
margin-bottom: 30px;
font-size: 2.5em;
background: linear-gradient(45deg, #667eea, #764ba2);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.config-section {
margin-bottom: 30px;
padding: 20px;
background: rgba(102, 126, 234, 0.1);
border-radius: 15px;
border-left: 4px solid #667eea;
}
.config-section h3 {
color: #333;
margin-bottom: 15px;
}
.input-group {
margin-bottom: 15px;
}
label {
display: block;
color: #555;
margin-bottom: 5px;
font-weight: 500;
}
input, select {
width: 100%;
padding: 12px;
border: 2px solid #ddd;
border-radius: 10px;
font-size: 16px;
transition: all 0.3s ease;
}
input:focus, select:focus {
outline: none;
border-color: #667eea;
box-shadow: 0 0 0 3px rgba(102, 126, 234, 0.1);
}
small {
display: block;
margin-top: 5px;
color: #666;
font-size: 12px;
}
.record-section {
text-align: center;
margin: 30px 0;
}
.record-btn {
background: linear-gradient(45deg, #667eea, #764ba2);
color: white;
border: none;
padding: 20px 40px;
border-radius: 50px;
font-size: 18px;
font-weight: bold;
cursor: pointer;
transition: all 0.3s ease;
margin: 10px;
box-shadow: 0 10px 30px rgba(102, 126, 234, 0.3);
}
.record-btn:hover {
transform: translateY(-3px);
box-shadow: 0 15px 35px rgba(102, 126, 234, 0.4);
}
.record-btn:active {
transform: translateY(0);
}
.record-btn.recording {
background: linear-gradient(45deg, #ff6b6b, #ee5a52);
animation: pulse 2s infinite;
}
@keyframes pulse {
0% { transform: scale(1); }
50% { transform: scale(1.05); }
100% { transform: scale(1); }
}
.status {
margin: 20px 0;
padding: 15px;
border-radius: 10px;
text-align: center;
font-weight: 500;
}
.status.info {
background: rgba(52, 152, 219, 0.1);
color: #2980b9;
border: 1px solid rgba(52, 152, 219, 0.3);
}
.status.success {
background: rgba(46, 204, 113, 0.1);
color: #27ae60;
border: 1px solid rgba(46, 204, 113, 0.3);
}
.status.error {
background: rgba(231, 76, 60, 0.1);
color: #c0392b;
border: 1px solid rgba(231, 76, 60, 0.3);
}
.result-section {
margin-top: 30px;
}
.result-text {
background: #f8f9fa;
border: 2px solid #e9ecef;
border-radius: 15px;
padding: 20px;
min-height: 120px;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
word-wrap: break-word;
}
.audio-player {
margin: 20px 0;
width: 100%;
}
.file-upload {
margin: 20px 0;
text-align: center;
}
.file-upload input[type="file"] {
display: none;
}
.file-upload label {
display: inline-block;
padding: 15px 30px;
background: linear-gradient(45deg, #28a745, #20c997);
color: white;
border-radius: 25px;
cursor: pointer;
transition: all 0.3s ease;
font-weight: bold;
}
.file-upload label:hover {
transform: translateY(-2px);
box-shadow: 0 10px 25px rgba(40, 167, 69, 0.3);
}
.speaker-timeline {
margin: 20px 0;
padding: 15px;
background: #f8f9fa;
border-radius: 10px;
border-left: 4px solid #667eea;
}
.speaker-segment {
margin: 8px 0;
padding: 10px;
border-radius: 8px;
position: relative;
}
.speaker-1 {
background: rgba(102, 126, 234, 0.1);
border-left: 3px solid #667eea;
}
.speaker-2 {
background: rgba(255, 107, 107, 0.1);
border-left: 3px solid #ff6b6b;
}
.speaker-3 {
background: rgba(46, 204, 113, 0.1);
border-left: 3px solid #2ecc71;
}
.speaker-4 {
background: rgba(241, 196, 15, 0.1);
border-left: 3px solid #f1c40f;
}
.speaker-label {
font-weight: bold;
color: #555;
margin-bottom: 5px;
font-size: 14px;
}
.speaker-time {
font-size: 12px;
color: #888;
margin-left: 10px;
}
.speaker-text {
margin-top: 5px;
line-height: 1.4;
}
.analysis-section {
margin: 20px 0;
padding: 15px;
background: rgba(52, 152, 219, 0.1);
border-radius: 10px;
border-left: 4px solid #3498db;
}
.toggle-section {
margin: 10px 0;
}
.toggle-btn {
background: #3498db;
color: white;
border: none;
padding: 8px 16px;
border-radius: 5px;
cursor: pointer;
font-size: 14px;
}
.toggle-btn:hover {
background: #2980b9;
}
</style>
</head>
<body>
<div class="container">
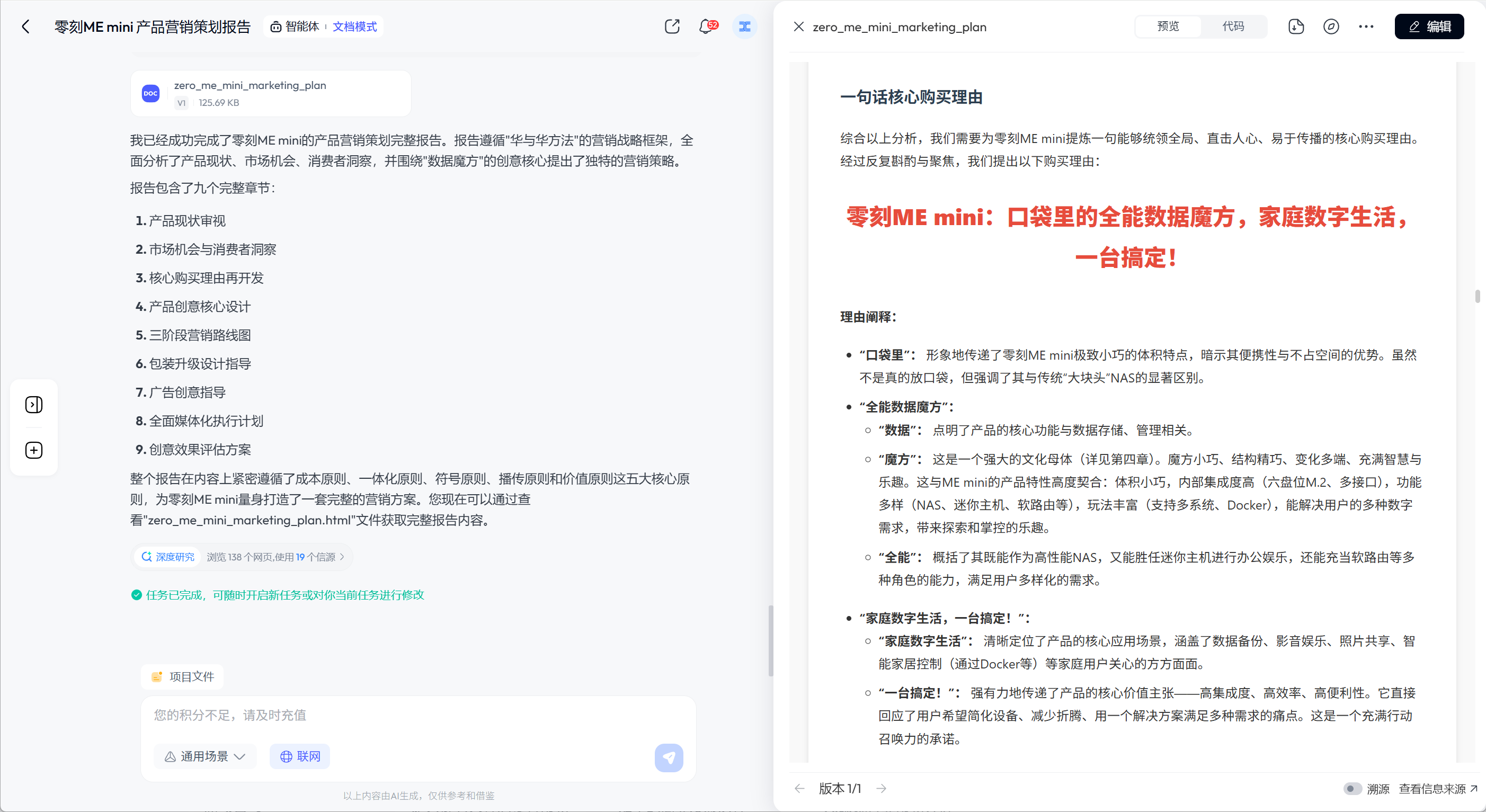
<h1>🎙️ 录音转文字</h1>
<!-- API配置区域 -->
<div class="config-section">
<h3>⚙️ API配置</h3>
<div class="input-group">
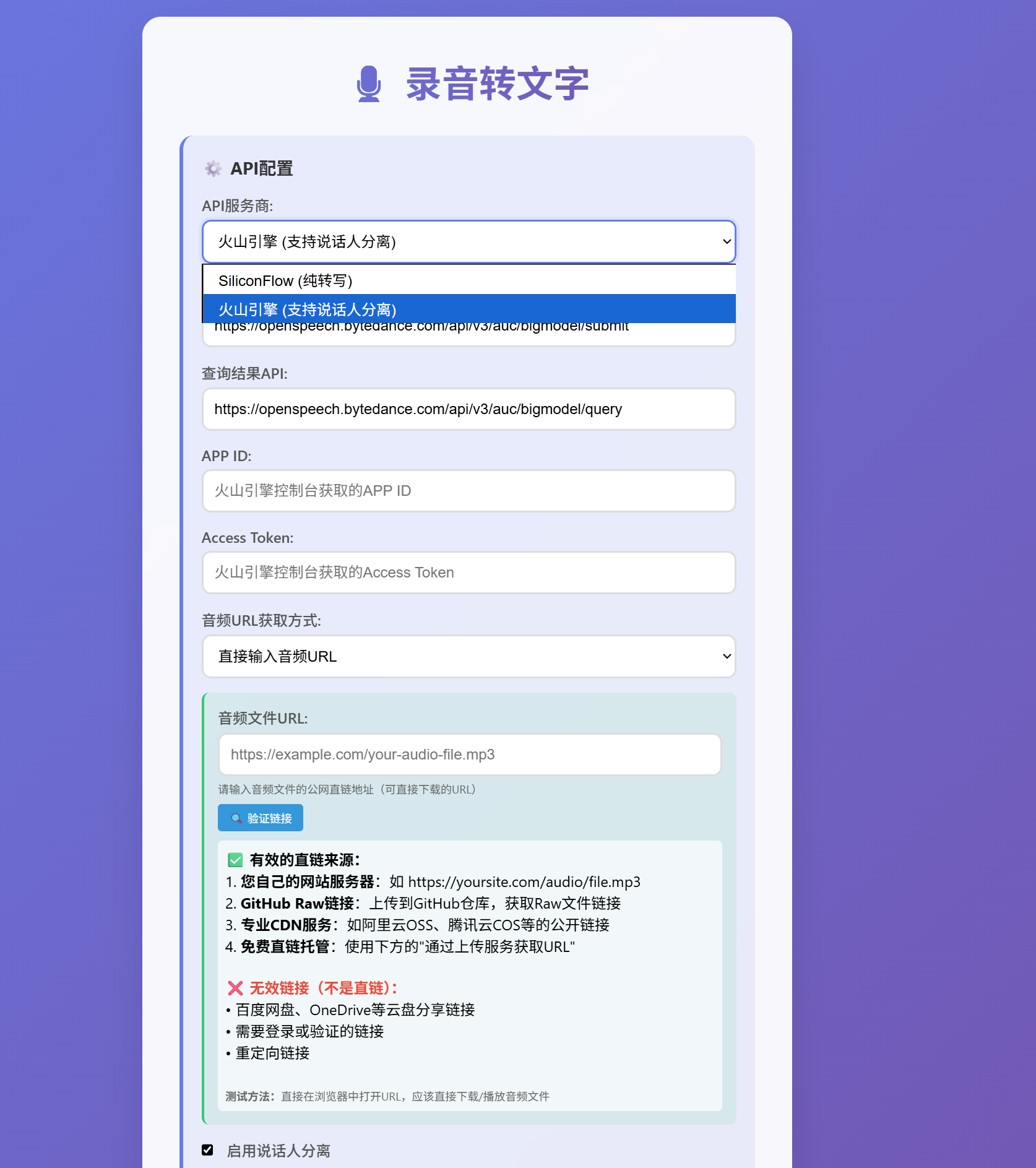
<label for="apiProvider">API服务商:</label>
<select id="apiProvider">
<option value="siliconflow">SiliconFlow (纯转写)</option>
<option value="volcengine">火山引擎 (支持说话人分离)</option>
</select>
</div>
<!-- SiliconFlow配置 -->
<div id="siliconflowConfig">
<div class="input-group">
<label for="apiUrl">API地址:</label>
<input type="text" id="apiUrl" value="https://api.siliconflow.cn/v1/audio/transcriptions">
</div>
<div class="input-group">
<label for="apiKey">API密钥:</label>
<input type="password" id="apiKey" placeholder="请输入您的SiliconFlow API密钥">
</div>
<div class="input-group">
<label for="model">模型:</label>
<input type="text" id="model" value="FunAudioLLM/SenseVoiceSmall">
</div>
</div>
<!-- 火山引擎配置 -->
<div id="volcengineConfig" style="display: none;">
<div class="input-group">
<label for="volcSubmitUrl">提交任务API:</label>
<input type="text" id="volcSubmitUrl" value="https://openspeech.bytedance.com/api/v3/auc/bigmodel/submit">
</div>
<div class="input-group">
<label for="volcQueryUrl">查询结果API:</label>
<input type="text" id="volcQueryUrl" value="https://openspeech.bytedance.com/api/v3/auc/bigmodel/query">
</div>
<div class="input-group">
<label for="volcAppKey">APP ID:</label>
<input type="text" id="volcAppKey" placeholder="火山引擎控制台获取的APP ID">
</div>
<div class="input-group">
<label for="volcAccessKey">Access Token:</label>
<input type="password" id="volcAccessKey" placeholder="火山引擎控制台获取的Access Token">
</div>
<!-- 音频URL获取方式选择 -->
<div class="input-group">
<label for="audioUrlMethod">音频URL获取方式:</label>
<select id="audioUrlMethod">
<option value="direct">直接输入音频URL</option>
<option value="upload">通过上传服务获取URL</option>
</select>
</div>
<!-- 直接输入URL选项 -->
<div id="directUrlConfig">
<div class="input-group" style="background: rgba(46, 204, 113, 0.1); padding: 15px; border-radius: 8px; border-left: 3px solid #2ecc71;">
<label for="directAudioUrl">音频文件URL:</label>
<input type="url" id="directAudioUrl" placeholder="https://example.com/your-audio-file.mp3">
<small>请输入音频文件的公网直链地址(可直接下载的URL)</small>
<button type="button" id="validateUrlBtn" style="margin-top: 8px; padding: 6px 12px; background: #3498db; color: white; border: none; border-radius: 4px; cursor: pointer; font-size: 12px;">🔍 验证链接</button>
<div id="urlValidationResult" style="margin-top: 8px; display: none;"></div>
<div style="margin-top: 10px; padding: 8px; background: rgba(255, 255, 255, 0.7); border-radius: 5px;">
<strong>✅ 有效的直链来源:</strong><br>
1. <strong>您自己的网站服务器</strong>:如 https://yoursite.com/audio/file.mp3<br>
2. <strong>GitHub Raw链接</strong>:上传到GitHub仓库,获取Raw文件链接<br>
3. <strong>专业CDN服务</strong>:如阿里云OSS、腾讯云COS等的公开链接<br>
4. <strong>免费直链托管</strong>:使用下方的"通过上传服务获取URL"<br>
<br>
<strong style="color: #e74c3c;">❌ 无效链接(不是直链):</strong><br>
• 百度网盘、OneDrive等云盘分享链接<br>
• 需要登录或验证的链接<br>
• 重定向链接<br>
<br>
<small style="color: #666;"><strong>测试方法:</strong>直接在浏览器中打开URL,应该直接下载/播放音频文件</small>
</div>
</div>
</div>
<!-- 上传服务选项 -->
<div id="uploadServiceConfig" style="display: none;">
<div class="input-group" style="background: rgba(40, 167, 69, 0.1); padding: 15px; border-radius: 8px; border-left: 3px solid #28a745;">
<label>✅ 免费直链托管服务:</label>
<p style="margin: 5px 0; color: #155724; font-size: 14px;">
<strong>自动上传并获取直链</strong><br>
• 支持 catbox.moe、file.io 等服务<br>
• 自动生成可用于火山引擎API的直链<br>
• 如果遇到网络问题,请尝试几次或使用自定义服务<br>
</p>
</div>
<div class="input-group">
<label for="customUploadUrl">自定义上传服务API (可选):</label>
<input type="text" id="customUploadUrl" placeholder="http://your-server.com/upload">
<small>如果您有自己的文件上传API,请填入。API应返回 JSON: {"url": "直链地址"}</small>
</div>
</div>
<div class="input-group">
<label>
<input type="checkbox" id="enableSpeakerDetection" style="width: auto; margin-right: 10px;" checked>
启用说话人分离
</label>
</div>
</div>
</div>
<!-- 文件上传区域 -->
<div class="file-upload">
<div id="fileUploadSection">
<label for="audioFile">📁 选择音频文件</label>
<input type="file" id="audioFile" accept="audio/*">
</div>
<div id="directUrlSection" style="display: none;">
<div style="text-align: center; padding: 20px; background: rgba(46, 204, 113, 0.1); border-radius: 15px; border: 2px dashed #2ecc71;">
<p style="margin: 0; color: #27ae60; font-weight: bold;">🔗 使用直接URL模式</p>
<p style="margin: 5px 0 0 0; color: #666; font-size: 14px;">请在上方火山引擎配置中输入音频文件URL</p>
</div>
</div>
</div>
<!-- 开始转换区域 -->
<div class="record-section">
<button id="convertBtn" class="record-btn" style="display: none; background: linear-gradient(45deg, #28a745, #20c997);">🚀 开始转换</button>
</div>
<!-- 状态显示 -->
<div id="status" class="status" style="display: none;"></div>
<!-- 音频播放器 -->
<audio id="audioPlayer" class="audio-player" controls style="display: none;"></audio>
<!-- 结果显示区域 -->
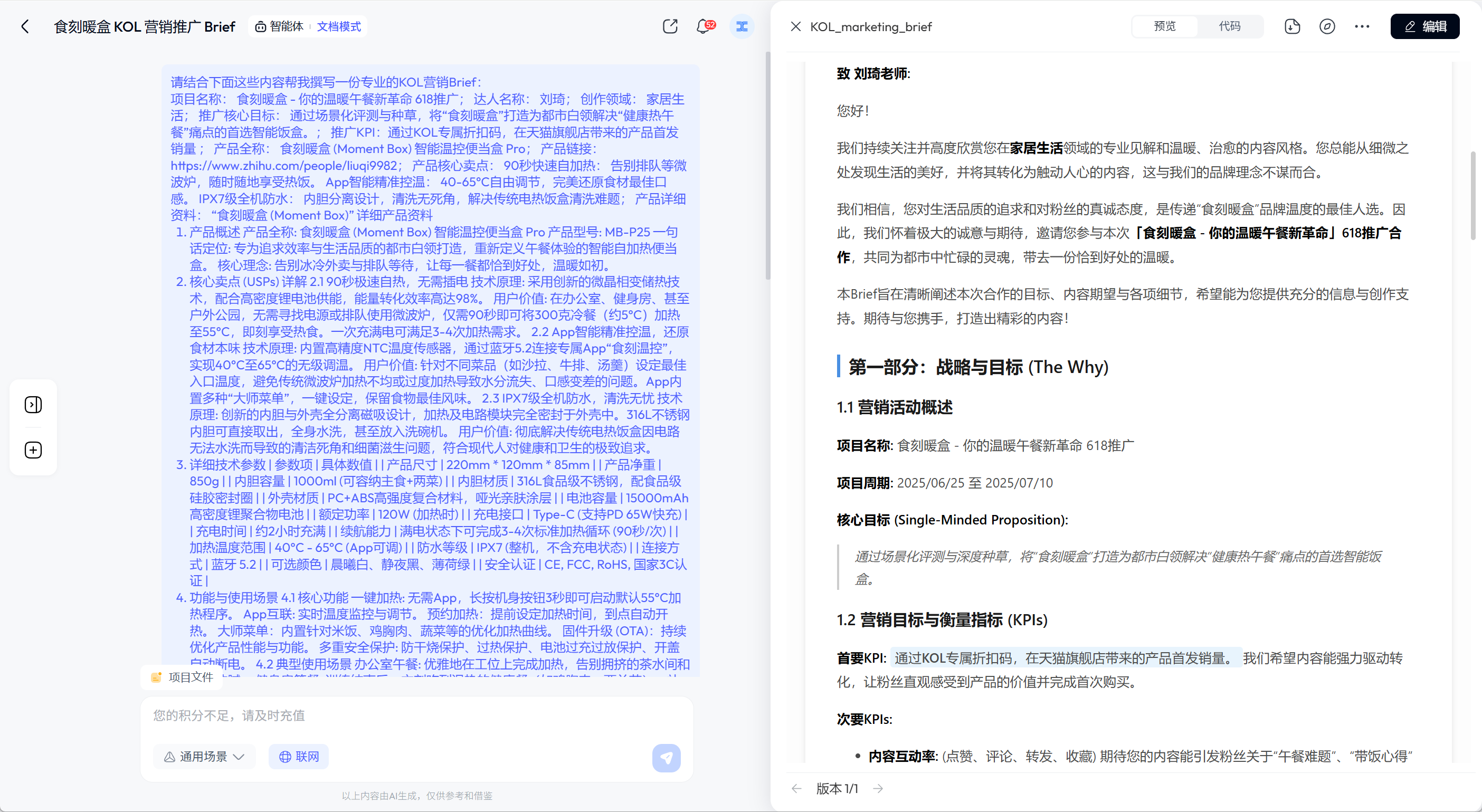
<div class="result-section">
<div style="display: flex; justify-content: space-between; align-items: center; margin-bottom: 15px;">
<h3>📝 转换结果:</h3>
<button id="exportBtn" class="toggle-btn" style="display: none; background: #28a745;">📄 导出TXT</button>
</div>
<!-- 转换结果文本 -->
<div id="resultText" class="result-text">在这里将显示语音转文字的结果...</div>
<!-- 音频分析信息 -->
<div id="audioAnalysis" class="analysis-section" style="display: none;">
<h4>🔍 音频分析:</h4>
<div id="analysisInfo"></div>
</div>
</div>
</div>
<script>
let currentAudioBlob;
let currentTranscription = ''; // 保存当前转换结果
let currentSpeakerSegments = []; // 保存当前说话人分离结果
const convertBtn = document.getElementById('convertBtn');
const exportBtn = document.getElementById('exportBtn');
const status = document.getElementById('status');
const resultText = document.getElementById('resultText');
const audioPlayer = document.getElementById('audioPlayer');
const audioFileInput = document.getElementById('audioFile');
const audioAnalysis = document.getElementById('audioAnalysis');
const analysisInfo = document.getElementById('analysisInfo');
const apiProvider = document.getElementById('apiProvider');
const siliconflowConfig = document.getElementById('siliconflowConfig');
const volcengineConfig = document.getElementById('volcengineConfig');
const audioUrlMethod = document.getElementById('audioUrlMethod');
const directUrlConfig = document.getElementById('directUrlConfig');
const uploadServiceConfig = document.getElementById('uploadServiceConfig');
const directAudioUrlInput = document.getElementById('directAudioUrl');
const customUploadUrlInput = document.getElementById('customUploadUrl');
const fileUploadSection = document.getElementById('fileUploadSection');
const directUrlSection = document.getElementById('directUrlSection');
const validateUrlBtn = document.getElementById('validateUrlBtn');
const urlValidationResult = document.getElementById('urlValidationResult');
// API提供商切换
function switchApiProvider() {
const provider = apiProvider.value;
if (provider === 'siliconflow') {
siliconflowConfig.style.display = 'block';
volcengineConfig.style.display = 'none';
// 硅基流动只支持文件上传
fileUploadSection.style.display = 'block';
directUrlSection.style.display = 'none';
// 重置火山引擎配置
directUrlConfig.style.display = 'none';
uploadServiceConfig.style.display = 'none';
customUploadUrlInput.value = '';
directAudioUrlInput.value = '';
audioUrlMethod.value = 'direct';
} else if (provider === 'volcengine') {
siliconflowConfig.style.display = 'none';
volcengineConfig.style.display = 'block';
// 重置硅流配置
document.getElementById('apiUrl').value = 'https://api.siliconflow.cn/v1/audio/transcriptions';
document.getElementById('apiKey').value = '';
document.getElementById('model').value = 'FunAudioLLM/SenseVoiceSmall';
// 根据音频URL获取方式显示配置
switchAudioUrlMethod();
}
// 重置结果显示
resetResults();
// 重置转换按钮状态
updateConvertButtonState();
}
// 音频URL获取方式切换
function switchAudioUrlMethod() {
if (apiProvider.value !== 'volcengine') return;
if (audioUrlMethod.value === 'direct') {
directUrlConfig.style.display = 'block';
uploadServiceConfig.style.display = 'none';
fileUploadSection.style.display = 'none';
directUrlSection.style.display = 'block';
customUploadUrlInput.value = '';
} else {
directUrlConfig.style.display = 'none';
uploadServiceConfig.style.display = 'block';
fileUploadSection.style.display = 'block';
directUrlSection.style.display = 'none';
directAudioUrlInput.value = '';
}
updateConvertButtonState();
}
// 更新转换按钮状态
function updateConvertButtonState() {
const provider = apiProvider.value;
let canConvert = false;
if (provider === 'siliconflow') {
// 硅基流动需要文件
canConvert = currentAudioBlob !== null;
} else if (provider === 'volcengine') {
if (audioUrlMethod.value === 'direct') {
// 直接URL模式,检查URL是否已填写
const url = directAudioUrlInput.value.trim();
canConvert = url && (url.startsWith('http://') || url.startsWith('https://'));
} else {
// 上传服务模式,需要文件
canConvert = currentAudioBlob !== null;
}
}
if (canConvert) {
convertBtn.style.display = 'inline-block';
if (provider === 'volcengine' && audioUrlMethod.value === 'direct') {
showStatus(`🔗 已配置直接URL,点击"开始转换"进行语音识别`, 'success');
}
} else {
convertBtn.style.display = 'none';
}
}
// 重置结果显示
function resetResults() {
// speakerResults.style.display = 'none'; // 移除说话人结果显示
// originalResults.style.display = 'block'; // 移除完整文本显示
audioAnalysis.style.display = 'none';
// toggleView.style.display = 'none'; // 移除视图切换按钮
exportBtn.style.display = 'none';
// currentViewMode = 'original'; // 移除视图模式变量
currentTranscription = '';
currentSpeakerSegments = [];
resultText.textContent = '在这里将显示语音转文字的结果...';
}
// 显示状态消息
function showStatus(message, type = 'info') {
status.textContent = message;
status.className = `status ${type}`;
status.style.display = 'block';
console.log(`[${type.toUpperCase()}] ${message}`); // 添加控制台日志
}
// 隐藏状态消息
function hideStatus() {
status.style.display = 'none';
}
// 导出为TXT文件
function exportToTxt() {
let content = '';
const filename = `语音转文字_${new Date().toISOString().slice(0, 19).replace(/:/g, '-')}.txt`;
if (currentSpeakerSegments.length > 0) {
// 有说话人分离结果,导出分离结果+完整文本
content = '=== 说话人分离结果 ===\n\n';
currentSpeakerSegments.forEach((segment) => {
content += `[说话人 ${segment.speaker}] (${formatTime(segment.startTime)} - ${formatTime(segment.endTime)})\n`;
content += `${segment.text}\n\n`;
});
content += `\n=== 完整文本 ===\n\n${currentTranscription}`;
} else {
// 没有说话人分离结果,导出完整文本
content = currentTranscription;
}
if (!content.trim()) {
showStatus('⚠️ 没有可导出的内容', 'error');
return;
}
// 创建下载链接
const blob = new Blob([content], { type: 'text/plain;charset=utf-8' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = filename;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
showStatus('📄 文件已导出!', 'success');
}
// 上传文件到托管服务(改进版)
async function uploadToCatbox(file) {
showStatus('📤 正在尝试免费托管服务...', 'info');
// 可用的托管服务列表
const uploadServices = [
{
name: 'catbox.moe',
upload: async (file) => {
const formData = new FormData();
formData.append('reqtype', 'fileupload');
formData.append('fileToUpload', file);
const response = await fetch('https://catbox.moe/user/api.php', {
method: 'POST',
body: formData
});
if (response.ok) {
const result = await response.text();
if (result.startsWith('https://files.catbox.moe/')) {
return result.trim();
}
}
throw new Error('catbox.moe 上传失败');
}
},
{
name: 'file.io',
upload: async (file) => {
const formData = new FormData();
formData.append('file', file);
const response = await fetch('https://file.io', {
method: 'POST',
body: formData
});
if (response.ok) {
const result = await response.json();
if (result.success && result.link) {
return result.link;
}
}
throw new Error('file.io 上传失败');
}
}
];
let lastError = null;
// 尝试各个服务
for (let i = 0; i < uploadServices.length; i++) {
const service = uploadServices[i];
try {
showStatus(`📤 正在尝试 ${service.name}... (${i + 1}/${uploadServices.length})`, 'info');
console.log(`尝试上传到: ${service.name}`);
const url = await service.upload(file);
console.log(`${service.name} 上传成功:`, url);
showStatus(`✅ 文件上传成功!使用服务: ${service.name}`, 'success');
return url;
} catch (error) {
console.warn(`${service.name} 上传失败:`, error.message);
lastError = error;
if (i < uploadServices.length - 1) {
showStatus(`⚠️ ${service.name} 失败,尝试下一个服务...`, 'info');
await new Promise(resolve => setTimeout(resolve, 1000));
}
}
}
// 所有服务都失败了
console.error('所有免费托管服务都失败了');
showStatus(`❌ 免费托管服务暂时不可用`, 'error');
// 提供详细的解决方案
const errorMessage = `
免费托管服务暂时不可用,请尝试以下方案:
✅ 推荐方案:
1. 使用您自己的服务器上传音频文件
2. 上传到GitHub仓库,获取Raw链接
3. 使用专业CDN服务(阿里云OSS、腾讯云COS等)
🔧 GitHub直链教程:
1. 登录GitHub,创建新仓库
2. 上传音频文件到仓库
3. 点击文件 → Raw 按钮
4. 复制Raw链接地址
💡 自定义上传服务:
如果您有自己的文件上传API,请在上方填写自定义上传服务地址
`;
throw new Error(errorMessage);
}
// 生成UUID
function generateUUID() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
const r = Math.random() * 16 | 0;
const v = c == 'x' ? r : (r & 0x3 | 0x8);
return v.toString(16);
});
}
// 创建音频URL
async function createAudioUrl(audioBlob) {
const customUploadUrl = customUploadUrlInput.value.trim();
// 如果用户提供了自定义上传服务,优先使用
if (customUploadUrl) {
try {
showStatus('📤 正在使用自定义上传服务...', 'info');
console.log('尝试自定义上传服务:', customUploadUrl);
const formData = new FormData();
formData.append('file', audioBlob);
formData.append('audio', audioBlob); // 兼容不同的字段名
const response = await fetch(customUploadUrl, {
method: 'POST',
body: formData
});
if (!response.ok) {
throw new Error(`自定义服务响应失败: ${response.status}`);
}
const result = await response.json();
const url = result.url || result.file_url || result.link;
if (url) {
console.log('自定义服务上传成功:', url);
showStatus('✅ 自定义服务上传成功!', 'success');
return url;
} else {
throw new Error('自定义服务返回数据格式不正确');
}
} catch (error) {
console.warn('自定义上传服务失败,转用免费服务:', error.message);
showStatus('⚠️ 自定义服务失败,转用免费托管服务...', 'info');
}
}
// 使用免费托管服务
return await uploadToCatbox(audioBlob);
}
// 将音频转换为文字
async function convertToText() {
const provider = apiProvider.value;
// 检查是否需要文件
if (provider === 'siliconflow' || (provider === 'volcengine' && audioUrlMethod.value === 'upload')) {
if (!currentAudioBlob) {
showStatus('⚠️ 请先选择音频文件', 'error');
return;
}
}
console.log('开始转换,提供商:', provider, '文件大小:', currentAudioBlob ? currentAudioBlob.size : '使用URL');
try {
if (provider === 'siliconflow') {
await convertWithSiliconFlow(currentAudioBlob);
} else if (provider === 'volcengine') {
await convertWithVolcEngine(currentAudioBlob);
}
} catch (error) {
console.error('转换失败:', error);
showStatus(`❌ 转换失败: ${error.message}`, 'error');
displayErrorInfo(provider, error);
}
}
// SiliconFlow转换(纯转写)
async function convertWithSiliconFlow(audioBlob) {
const apiUrl = document.getElementById('apiUrl').value.trim();
const apiKey = document.getElementById('apiKey').value.trim();
const model = document.getElementById('model').value.trim();
if (!apiKey) {
throw new Error('请填入SiliconFlow的API密钥');
}
showStatus('🔄 正在转换为文字...', 'info');
const formData = new FormData();
formData.append('file', audioBlob, 'recording.webm');
formData.append('model', model);
console.log('发送SiliconFlow请求:', { apiUrl, model, fileSize: audioBlob.size });
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Authorization': `Bearer ${apiKey}` },
body: formData
});
console.log('SiliconFlow响应状态:', response.status);
if (!response.ok) {
let errorMessage = `API请求失败: ${response.status} ${response.statusText}`;
try {
const errorData = await response.json();
console.log('SiliconFlow错误响应:', errorData);
if (errorData.error && errorData.error.message) {
errorMessage += ` - ${errorData.error.message}`;
}
} catch (e) {
console.log('无法解析错误响应');
}
throw new Error(errorMessage);
}
const result = await response.json();
console.log('SiliconFlow成功响应:', result);
const transcription = result.text;
if (!transcription) {
throw new Error('转换结果为空');
}
// 先重置界面
resetResults();
// 再保存和显示结果
currentTranscription = transcription;
currentSpeakerSegments = [];
resultText.textContent = transcription;
// 启用导出按钮
exportBtn.style.display = 'inline-block';
showStatus('✅ 转换完成!', 'success');
console.log('SiliconFlow转换完成,结果长度:', transcription.length);
console.log('保存的结果:', currentTranscription.substring(0, 100) + '...');
}
// 火山引擎提交任务
async function submitVolcEngineTask(audioUrl) {
const appKey = document.getElementById('volcAppKey').value.trim();
const accessKey = document.getElementById('volcAccessKey').value.trim();
const enableSpeakerDetection = document.getElementById('enableSpeakerDetection').checked;
if (!appKey || !accessKey) {
throw new Error('请填入火山引擎的APP ID和Access Token');
}
const taskId = generateUUID();
const requestBody = {
user: {
uid: "web-user-" + Date.now()
},
audio: {
format: "mp3",
url: audioUrl
},
request: {
model_name: "bigmodel",
enable_itn: true,
enable_punc: true,
enable_speaker_info: enableSpeakerDetection,
show_utterances: true
}
};
console.log('提交的请求参数:', JSON.stringify(requestBody, null, 2)); // 添加请求参数日志
console.log('说话人分离是否启用:', enableSpeakerDetection); // 明确显示参数状态
const response = await fetch('https://openspeech.bytedance.com/api/v3/auc/bigmodel/submit', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-App-Key': appKey,
'X-Api-Access-Key': accessKey,
'X-Api-Resource-Id': 'volc.bigasr.auc',
'X-Api-Request-Id': taskId,
'X-Api-Sequence': '-1'
},
body: JSON.stringify(requestBody)
});
console.log('提交任务响应状态:', response.status); // 添加响应状态日志
console.log('提交任务响应头:', Object.fromEntries(response.headers.entries())); // 添加响应头日志
if (!response.ok) {
const statusCode = response.headers.get('X-Api-Status-Code');
const message = response.headers.get('X-Api-Message');
throw new Error(`任务提交失败: ${statusCode} - ${message}`);
}
return taskId;
}
// 火山引擎查询结果
async function queryVolcEngineResult(taskId) {
const appKey = document.getElementById('volcAppKey').value.trim();
const accessKey = document.getElementById('volcAccessKey').value.trim();
console.log('查询任务ID:', taskId); // 添加任务ID日志
const response = await fetch('https://openspeech.bytedance.com/api/v3/auc/bigmodel/query', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-App-Key': appKey,
'X-Api-Access-Key': accessKey,
'X-Api-Resource-Id': 'volc.bigasr.auc',
'X-Api-Request-Id': taskId,
'X-Api-Sequence': '-1'
},
body: '{}'
});
const statusCode = response.headers.get('X-Api-Status-Code');
console.log('查询响应状态码:', statusCode); // 添加状态码日志
console.log('查询响应头:', Object.fromEntries(response.headers.entries())); // 添加响应头日志
if (statusCode === '20000000') {
// 成功
const result = await response.json();
console.log('查询成功,完整返回结果:', JSON.stringify(result, null, 2)); // 添加完整结果日志
return { status: 'completed', data: result };
} else if (statusCode === '40000001') {
// 处理中
console.log('任务仍在处理中...'); // 添加处理中日志
return { status: 'processing' };
} else {
// 失败
const message = response.headers.get('X-Api-Message');
console.error('查询失败:', statusCode, message); // 添加失败日志
throw new Error(`查询失败: ${statusCode} - ${message}`);
}
}
// 火山引擎轮询结果
async function pollVolcEngineResult(taskId, maxAttempts = 30) {
for (let i = 0; i < maxAttempts; i++) {
try {
const result = await queryVolcEngineResult(taskId);
if (result.status === 'completed') {
return result.data;
} else if (result.status === 'processing') {
showStatus(`🔄 处理中... (${i + 1}/${maxAttempts})`, 'info');
await new Promise(resolve => setTimeout(resolve, 2000)); // 等待2秒
continue;
}
} catch (error) {
if (i === maxAttempts - 1) throw error;
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
throw new Error('处理超时,请稍后重试');
}
// 火山引擎转换
async function convertWithVolcEngine(audioBlob) {
showStatus('🔄 准备进行语音识别...', 'info');
// 获取音频URL
let audioUrl;
if (audioUrlMethod.value === 'direct') {
audioUrl = directAudioUrlInput.value.trim();
if (!audioUrl) {
throw new Error('请先输入音频文件URL');
}
if (!audioUrl.startsWith('http://') && !audioUrl.startsWith('https://')) {
throw new Error('音频URL必须以 http:// 或 https:// 开头');
}
showStatus(`📁 使用直接URL: ${audioUrl}`, 'info');
console.log('使用直接URL:', audioUrl);
} else {
showStatus('🔄 正在上传音频文件...', 'info');
audioUrl = await createAudioUrl(audioBlob);
console.log('音频上传完成,URL:', audioUrl);
}
showStatus('🔄 正在提交识别任务...', 'info');
// 提交任务
const taskId = await submitVolcEngineTask(audioUrl);
console.log('任务提交成功,ID:', taskId);
showStatus('🔄 正在处理音频,请稍候...', 'info');
// 轮询结果
const volcResult = await pollVolcEngineResult(taskId);
console.log('火山引擎处理完成:', volcResult);
// 解析结果
const transcription = volcResult.result.text;
if (!transcription) {
throw new Error('转换结果为空');
}
// 先重置界面
resetResults();
// 保存基本结果
currentTranscription = transcription;
currentSpeakerSegments = [];
// 显示基本结果
resultText.textContent = transcription;
// 启用导出按钮
exportBtn.style.display = 'inline-block';
// 检查是否启用了说话人分离且有结果
const enableSpeakerDetection = document.getElementById('enableSpeakerDetection').checked;
if (enableSpeakerDetection && volcResult.result.utterances && volcResult.result.utterances.length > 0) {
const speakerSegments = parseVolcEngineSpeakerResult(volcResult);
console.log('解析的说话人片段:', speakerSegments); // 添加调试日志
if (speakerSegments.length > 0) {
// 保存说话人分离结果
currentSpeakerSegments = speakerSegments;
// 生成带说话人标记的文本格式
let speakerText = '';
speakerSegments.forEach((segment) => {
speakerText += `[说话人 ${segment.speaker}] (${formatTime(segment.startTime)} - ${formatTime(segment.endTime)})\n`;
speakerText += `${segment.text}\n\n`;
});
// 显示带说话人标记的文本
resultText.textContent = speakerText.trim();
// 显示分析信息
if (volcResult.audio_info) {
audioAnalysis.style.display = 'block';
const urlMethod = audioUrlMethod.value === 'direct' ? '直接URL' : '免费托管服务';
const speakerCount = Math.max(...speakerSegments.map(s => s.speaker));
analysisInfo.innerHTML = `
<p><strong>音频时长:</strong> ${(volcResult.audio_info.duration / 1000).toFixed(2)} 秒</p>
<p><strong>检测到说话人数量:</strong> ${speakerCount} 人</p>
<p><strong>音频片段数量:</strong> ${speakerSegments.length} 个</p>
<p><strong>API提供商:</strong> 火山引擎 (专业级)</p>
<p><strong>音频获取方式:</strong> ${urlMethod}</p>
`;
}
showStatus(`✅ 转换完成!已检测到 ${Math.max(...speakerSegments.map(s => s.speaker))} 个说话人`, 'success');
} else {
// 没有说话人分离结果,显示完整文本
resultText.textContent = transcription;
showStatus('✅ 转换完成!未检测到多个说话人', 'success');
}
} else {
// 未启用说话人分离或没有utterances,显示完整文本
resultText.textContent = transcription;
showStatus('✅ 转换完成!', 'success');
}
console.log('火山引擎转换完成,结果长度:', transcription.length);
console.log('保存的结果:', currentTranscription.substring(0, 100) + '...');
}
// 解析火山引擎说话人结果
function parseVolcEngineSpeakerResult(volcResult) {
console.log('完整的火山引擎返回结果:', volcResult); // 添加完整调试日志
if (!volcResult.result || !volcResult.result.utterances) {
console.log('没有找到utterances数据');
return [];
}
const utterances = volcResult.result.utterances;
console.log('utterances数据:', utterances); // 添加utterances调试日志
console.log('utterances数组长度:', utterances.length);
const segments = [];
utterances.forEach((utterance, index) => {
console.log(`utterance ${index} 完整结构:`, JSON.stringify(utterance, null, 2)); // 添加详细的utterance结构日志
// 尝试多种可能的说话人ID字段
let speakerId = 1; // 默认值
// 按优先级尝试不同的字段名
if (utterance.additions && utterance.additions.speaker !== undefined) {
speakerId = parseInt(utterance.additions.speaker); // 火山引擎的说话人ID在additions.speaker中
console.log(`找到additions.speaker: ${speakerId}`);
} else if (utterance.speaker_id !== undefined) {
speakerId = utterance.speaker_id;
console.log(`找到speaker_id: ${speakerId}`);
} else if (utterance.spk_id !== undefined) {
speakerId = utterance.spk_id;
console.log(`找到spk_id: ${speakerId}`);
} else if (utterance.speaker !== undefined) {
speakerId = utterance.speaker;
console.log(`找到speaker: ${speakerId}`);
} else if (utterance.channel_id !== undefined) {
speakerId = utterance.channel_id;
console.log(`找到channel_id: ${speakerId}`);
} else if (utterance.spk !== undefined) {
speakerId = utterance.spk;
console.log(`找到spk: ${speakerId}`);
} else {
console.log(`utterance ${index} 没有找到说话人ID字段,使用默认值1`);
}
segments.push({
speaker: speakerId,
startTime: utterance.start_time / 1000, // 转换为秒
endTime: utterance.end_time / 1000,
text: utterance.text
});
console.log(`解析结果 ${index}: speaker=${speakerId}, text="${utterance.text.substring(0, 20)}..."`);
});
console.log('解析后的segments:', segments); // 添加解析结果调试日志
// 统计说话人数量
const speakers = [...new Set(segments.map(s => s.speaker))];
console.log('检测到的说话人ID列表:', speakers);
console.log('说话人数量:', speakers.length);
return segments;
}
// 显示火山引擎说话人结果
function displayVolcEngineSpeakerResults(segments) {
// 这个函数已经不再需要,因为我们直接在resultText中显示带说话人标记的文本
console.log('displayVolcEngineSpeakerResults函数已废弃');
}
// 格式化时间
function formatTime(seconds) {
const mins = Math.floor(seconds / 60);
const secs = Math.floor(seconds % 60);
return `${mins}:${secs.toString().padStart(2, '0')}`;
}
// 切换视图(已废弃)
function toggleViewMode() {
// 这个函数已经不再需要,因为我们移除了视图切换功能
console.log('toggleViewMode函数已废弃');
}
// 显示错误信息
function displayErrorInfo(provider, error) {
if (provider === 'siliconflow') {
resultText.innerHTML = `转换失败。请检查:
1. API密钥是否正确
2. 网络连接是否正常
3. 音频文件格式是否支持
错误详情:${error.message}`;
} else if (provider === 'volcengine') {
// 检查是否是音频下载失败的错误
if (error.message.includes('audio download failed') || error.message.includes('Invalid audio URI')) {
resultText.innerHTML = `
<div style="color: #e74c3c; margin-bottom: 15px;">
<strong>❌ 音频文件下载失败</strong>
</div>
<div style="background: #fff3cd; padding: 15px; border-radius: 8px; border-left: 4px solid #ffc107; margin-bottom: 15px;">
<strong>🔍 问题原因:</strong><br>
您提供的URL不是有效的音频文件直链。火山引擎API无法直接下载该文件。
</div>
<div style="background: #d1ecf1; padding: 15px; border-radius: 8px; border-left: 4px solid #bee5eb; margin-bottom: 15px;">
<strong>✅ 解决方案:</strong><br>
<br>
<strong>1. 检查URL是否为直链:</strong><br>
• 在浏览器中直接打开您的URL<br>
• 如果直接开始下载/播放音频文件,则为有效直链<br>
• 如果跳转到登录页面或分享页面,则为无效链接<br>
<br>
<strong>2. 获取有效直链的方法:</strong><br>
• <strong>GitHub方式:</strong>上传到GitHub仓库,点击文件→Raw,复制链接<br>
• <strong>自有服务器:</strong>上传到您的网站服务器<br>
• <strong>专业CDN:</strong>使用阿里云OSS、腾讯云COS等服务<br>
• <strong>免费托管:</strong>切换到"通过上传服务获取URL"模式<br>
</div>
<div style="background: #f8d7da; padding: 10px; border-radius: 8px; border-left: 4px solid #dc3545;">
<strong>⚠️ 以下链接类型无效:</strong><br>
• 百度网盘、OneDrive、GoogleDrive分享链接<br>
• 需要登录验证的链接<br>
• 重定向链接<br>
</div>
<strong>错误详情:</strong> ${error.message}`;
} else {
resultText.innerHTML = `转换失败。请检查:
1. 火山引擎 APP ID 和 Access Token 是否正确
2. 网络连接是否正常
3. 音频文件URL是否为有效的直链地址
错误详情:${error.message}`;
}
}
}
// 验证URL是否为有效直链
function validateUrl() {
const url = directAudioUrlInput.value.trim();
const resultDiv = urlValidationResult;
resultDiv.style.display = 'none'; // 隐藏之前的结果
if (!url) {
resultDiv.textContent = '请先输入URL';
resultDiv.style.display = 'block';
return;
}
if (url.startsWith('http://') || url.startsWith('https://')) {
resultDiv.textContent = '✅ 这是一个有效的直链URL!';
resultDiv.style.color = 'green';
resultDiv.style.fontWeight = 'bold';
resultDiv.style.display = 'block';
} else {
resultDiv.textContent = '❌ 这不是一个有效的直链URL。请确保它以 http:// 或 https:// 开头。';
resultDiv.style.color = 'red';
resultDiv.style.fontWeight = 'bold';
resultDiv.style.display = 'block';
}
}
// 处理文件上传
audioFileInput.addEventListener('change', async (event) => {
const file = event.target.files[0];
if (file) {
console.log('选择的文件:', file.name, file.type, file.size);
// 检查文件类型
if (!file.type.startsWith('audio/')) {
showStatus('❌ 请选择音频文件', 'error');
return;
}
// 检查文件大小(限制为50MB)
if (file.size > 50 * 1024 * 1024) {
showStatus('❌ 文件过大,请选择小于50MB的音频文件', 'error');
return;
}
currentAudioBlob = file;
// 显示音频播放器
const audioUrl = URL.createObjectURL(file);
audioPlayer.src = audioUrl;
audioPlayer.style.display = 'block';
// 显示开始转换按钮
updateConvertButtonState(); // 更新按钮状态
}
});
// 事件监听器
convertBtn.addEventListener('click', () => {
console.log('点击转换按钮');
convertToText();
});
exportBtn.addEventListener('click', () => {
console.log('点击导出按钮');
exportToTxt();
});
// toggleView.addEventListener('click', toggleViewMode); // 移除视图切换按钮监听器
apiProvider.addEventListener('change', switchApiProvider);
audioUrlMethod.addEventListener('change', switchAudioUrlMethod);
directAudioUrlInput.addEventListener('input', updateConvertButtonState); // 添加URL输入监听器
validateUrlBtn.addEventListener('click', validateUrl); // 添加URL验证按钮监听器
// 页面加载完成后的初始化
document.addEventListener('DOMContentLoaded', () => {
console.log('页面加载完成');
showStatus('🔧 请选择API服务商并配置相关信息。', 'info');
// 初始化视图
// toggleView.style.display = 'none'; // 移除视图切换按钮
convertBtn.style.display = 'none';
exportBtn.style.display = 'none';
switchApiProvider(); // 初始化API配置显示
// 为选择的输入框添加监听器以实时更新按钮状态
document.getElementById('apiKey').addEventListener('input', updateConvertButtonState);
document.getElementById('volcAppKey').addEventListener('input', updateConvertButtonState);
document.getElementById('volcAccessKey').addEventListener('input', updateConvertButtonState);
});
</script>
</body>
</html>