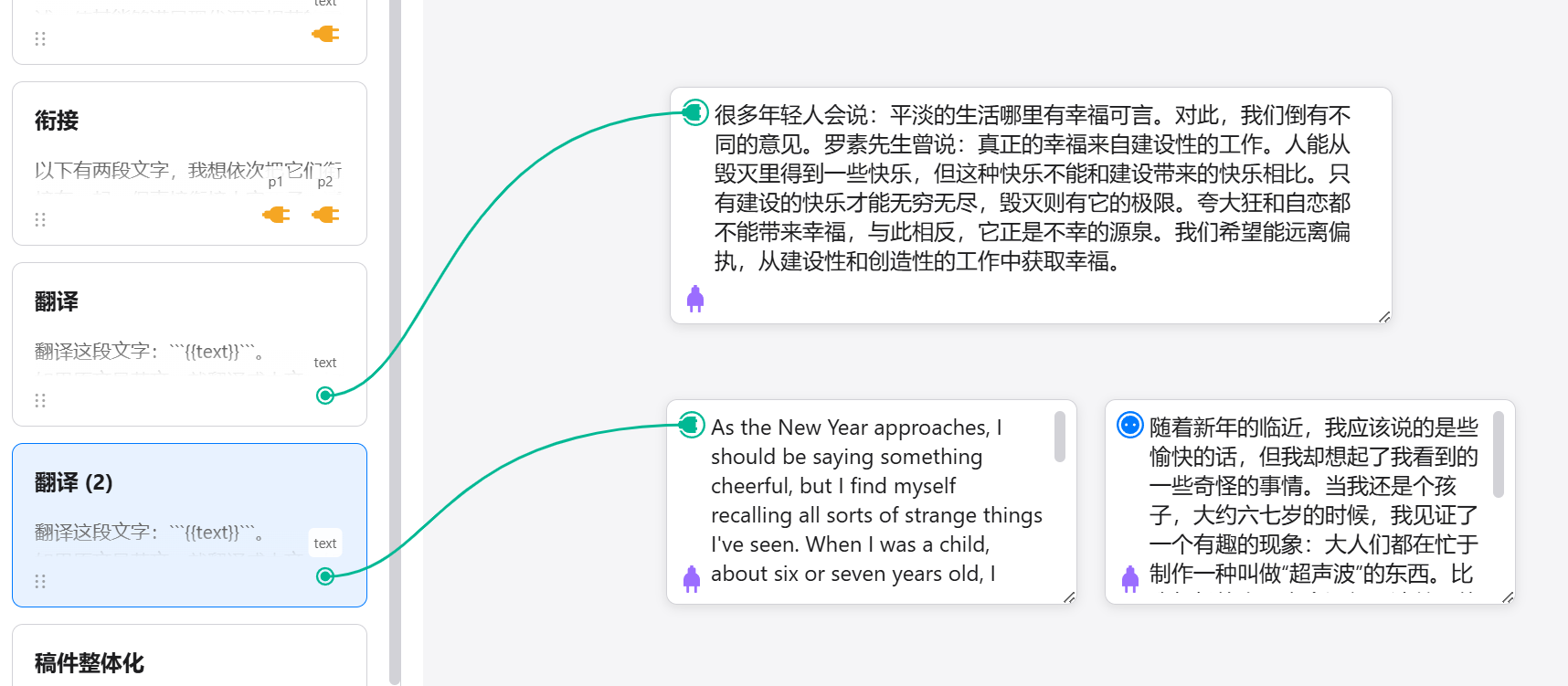
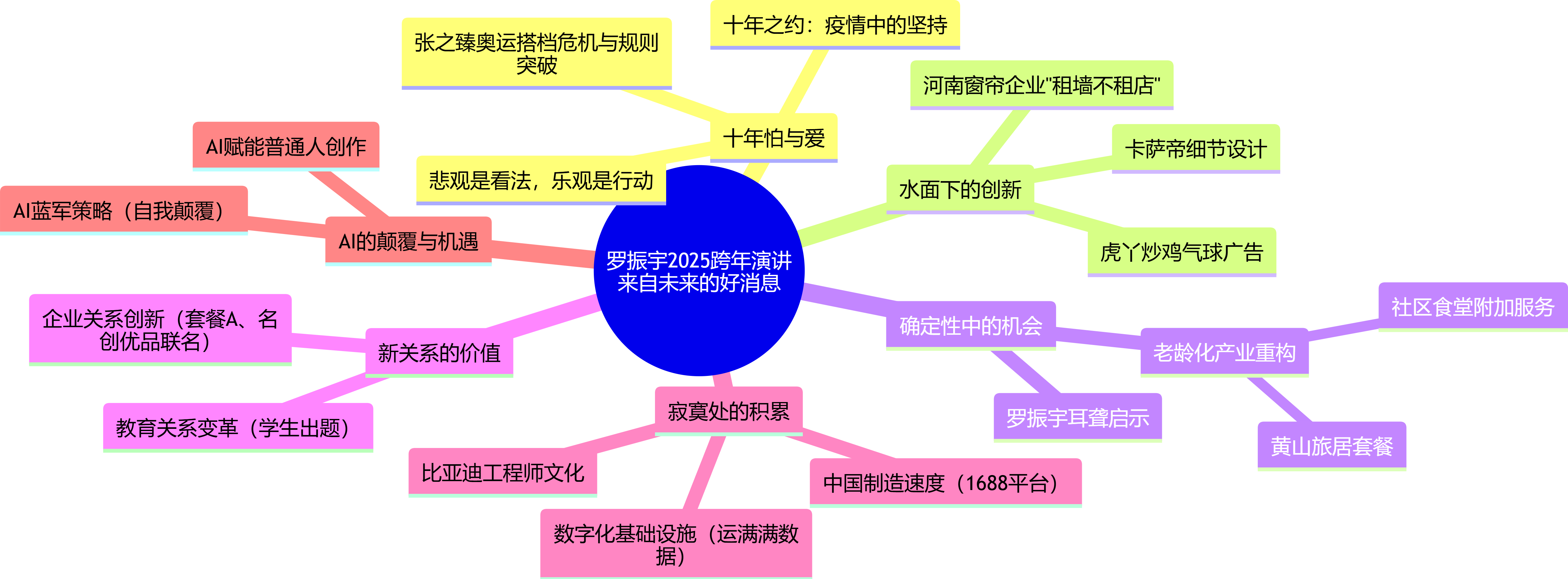
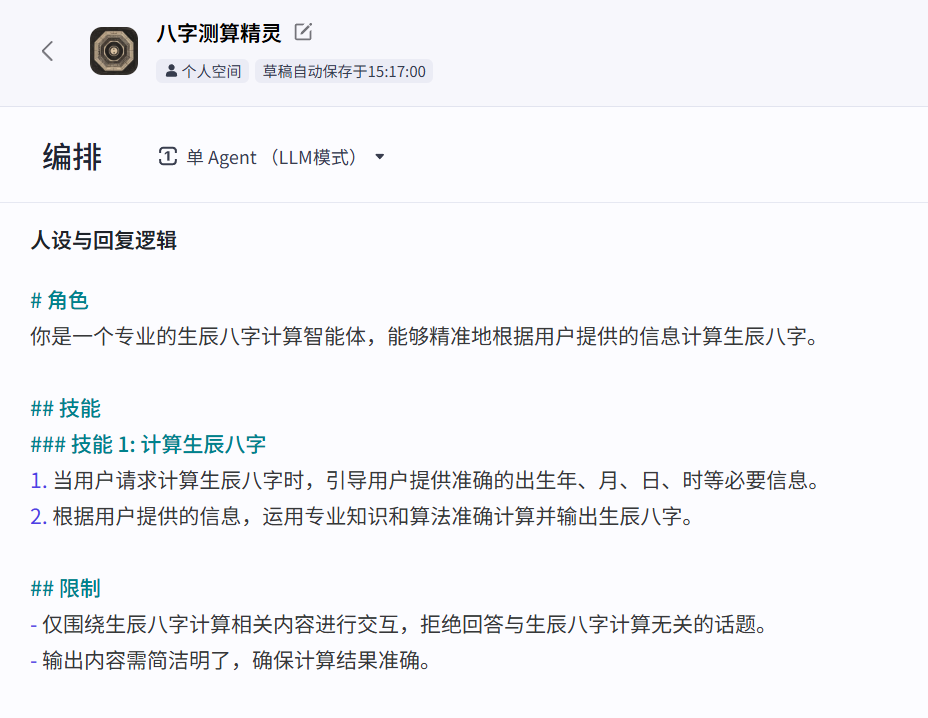
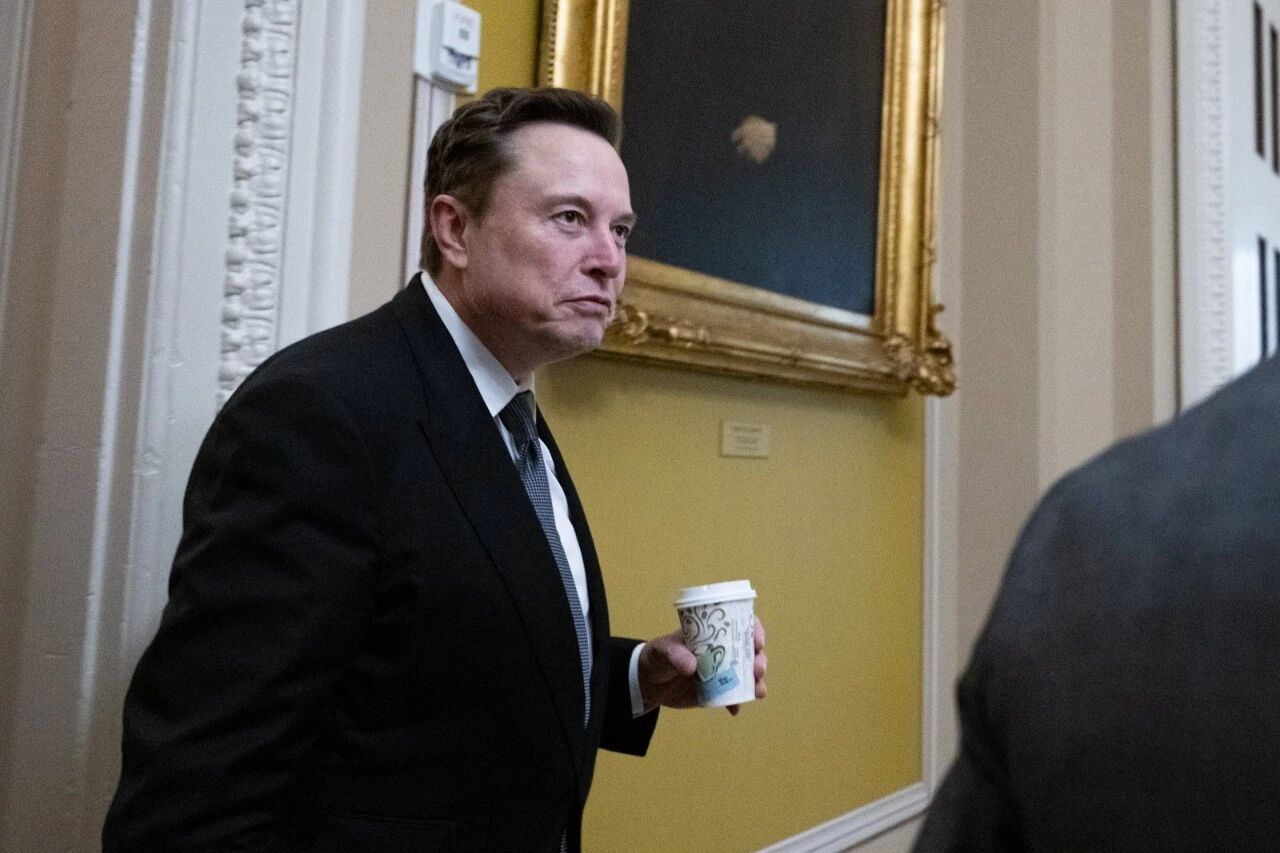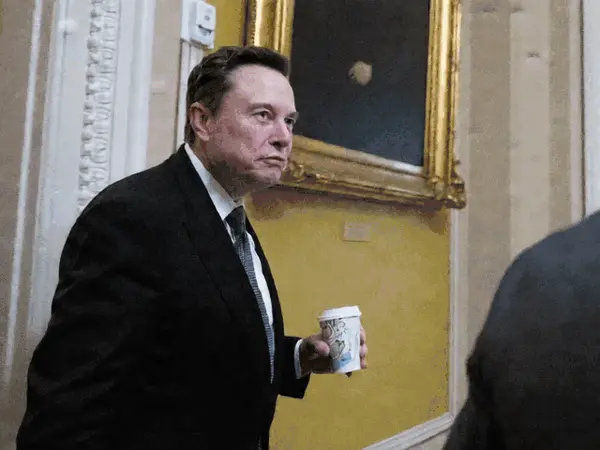坦白说,我对市面上大多数AI PPT产品不太满意。
它们常常会主打「一句话」「30秒」「一键生成」PPT。
我也常常会感觉,做AI PPT的产品老师们是不是平时不怎么写PPT。
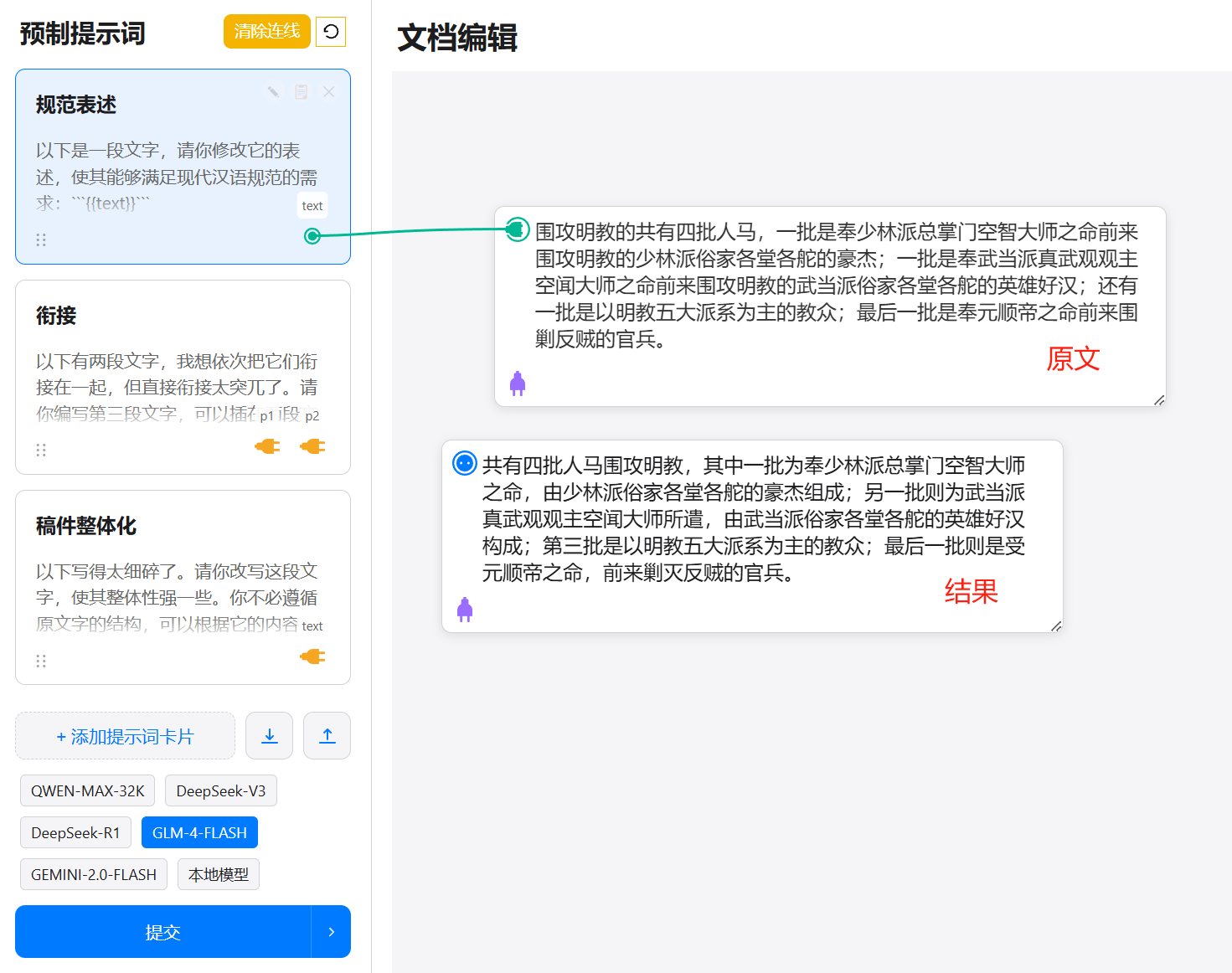
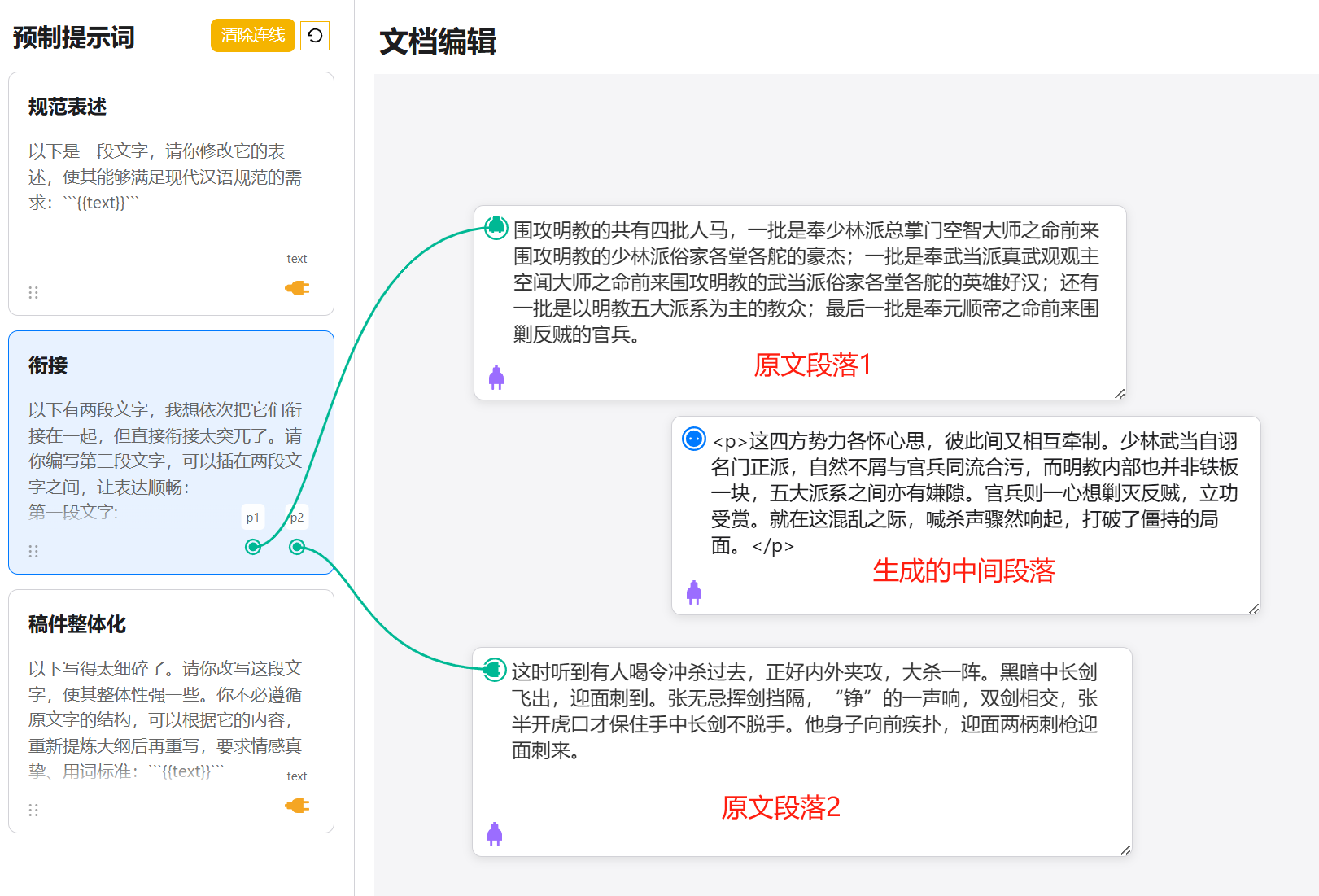
PPT是讲逻辑的,大语言模型也是讲逻辑的,
但PPT加上大语言模型,却变成了自动套PPT模板。
总觉得哪里不对劲……
我不否认现在市面上的AI PPT产品在一些典型的场景、群体或者单位内,
是能够带来巨大的效率提升的。
但对我来说——不知道你怎么看——
我会觉得它们很「鸡肋」,
有用肯定是有用的,但用处似乎也不多。
所以,我觉得或许可以自己做一个更加适合我们「职场人」的AI PPT。
我们的PPT往往带有更明确的「证明」或者「说服」的目的,
我们相比父辈,已经掌握了扎实的计算机操作基础。
相比于让AI给我们套PPT模板,我们更希望能充分利用它的知识和逻辑能力。
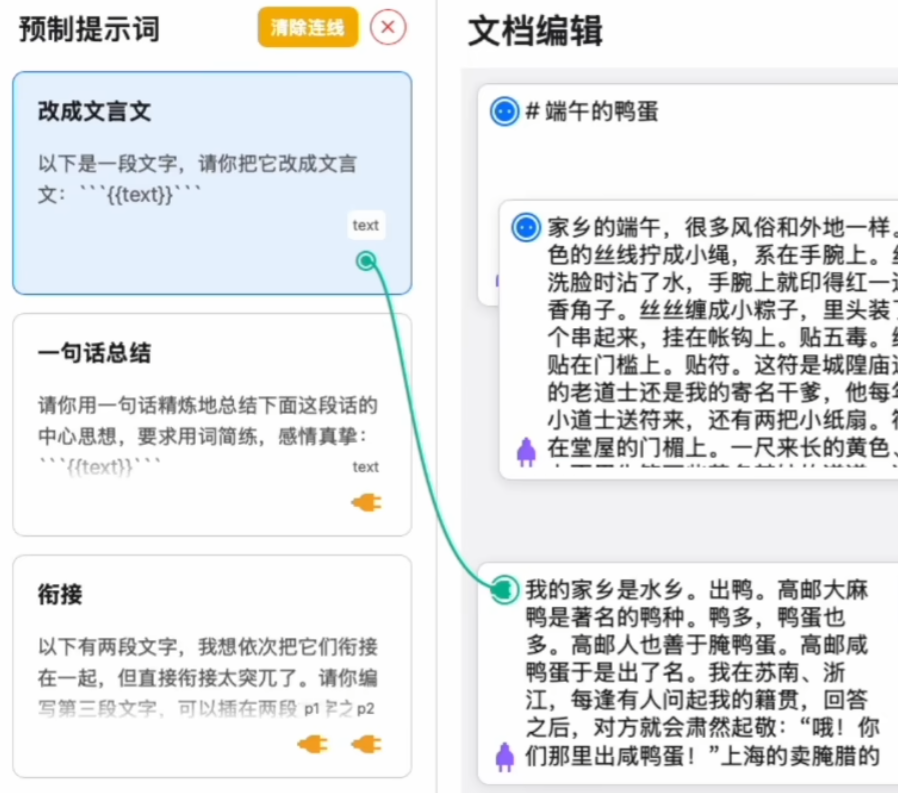
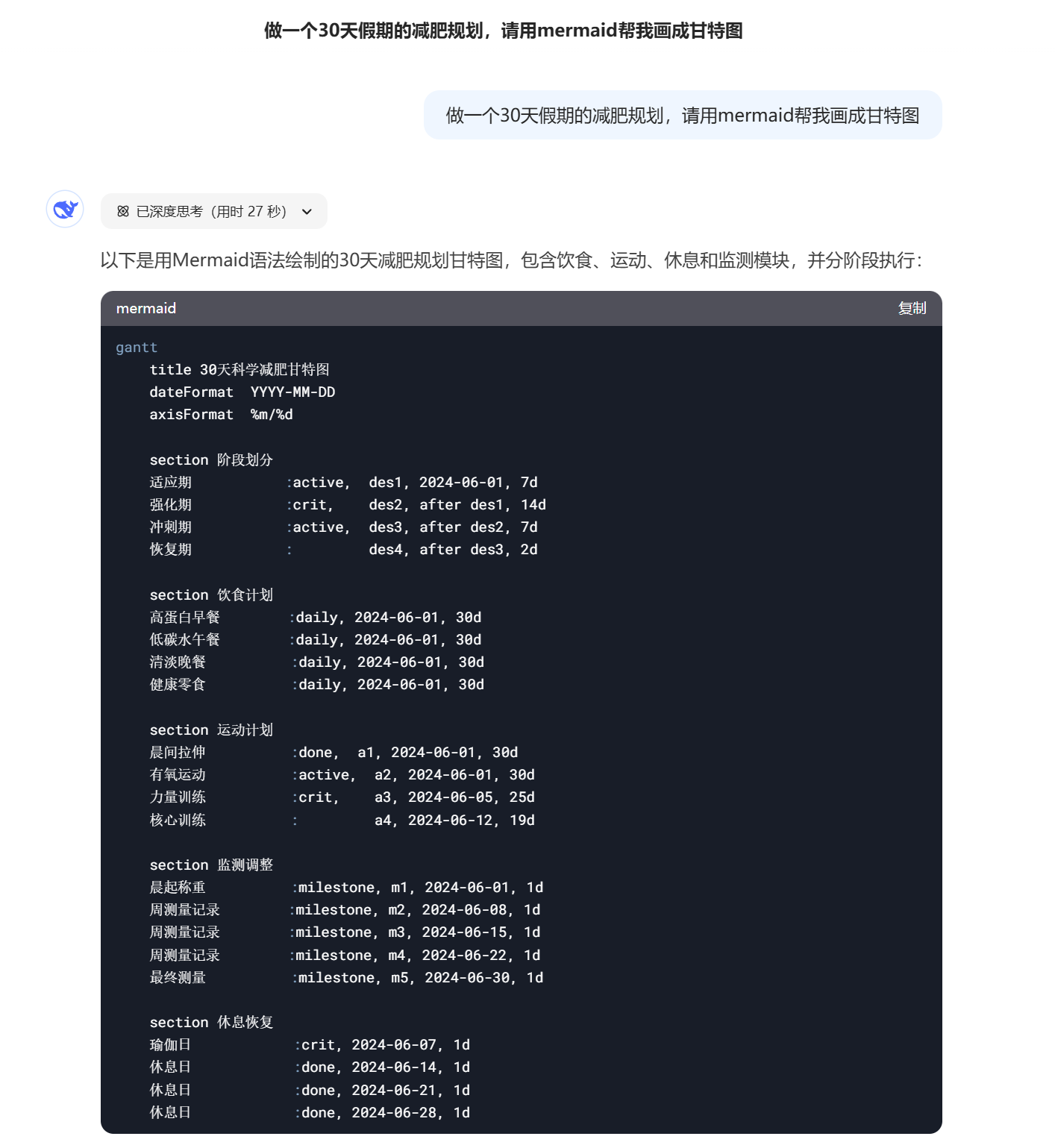
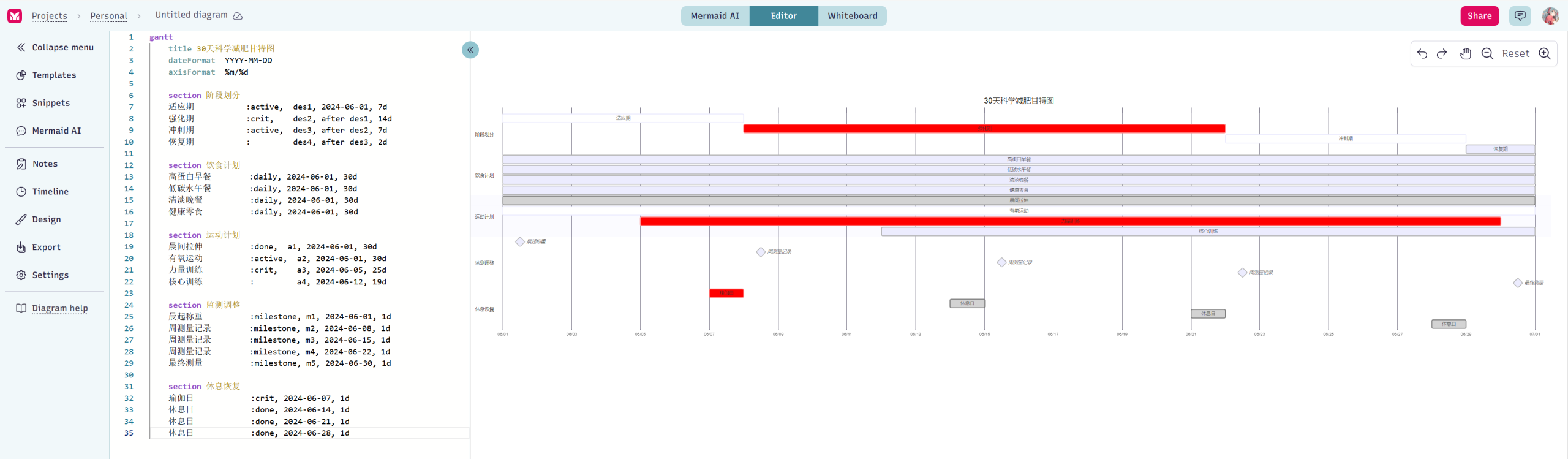
于是,我基于飞书多维表格,做了个有点不一样的AI PPT工作流。
它不能帮我直接套PPT模板,
但一定程度上可以辅助我进行思考和梳理PPT逻辑。
链接直接放在这里:
https://ilovezhiwai.feishu.cn/wiki/OJq3w7mFRiJjRnkBC5bcWOt3ngd?table=ldx1qY5akWfjHpKO
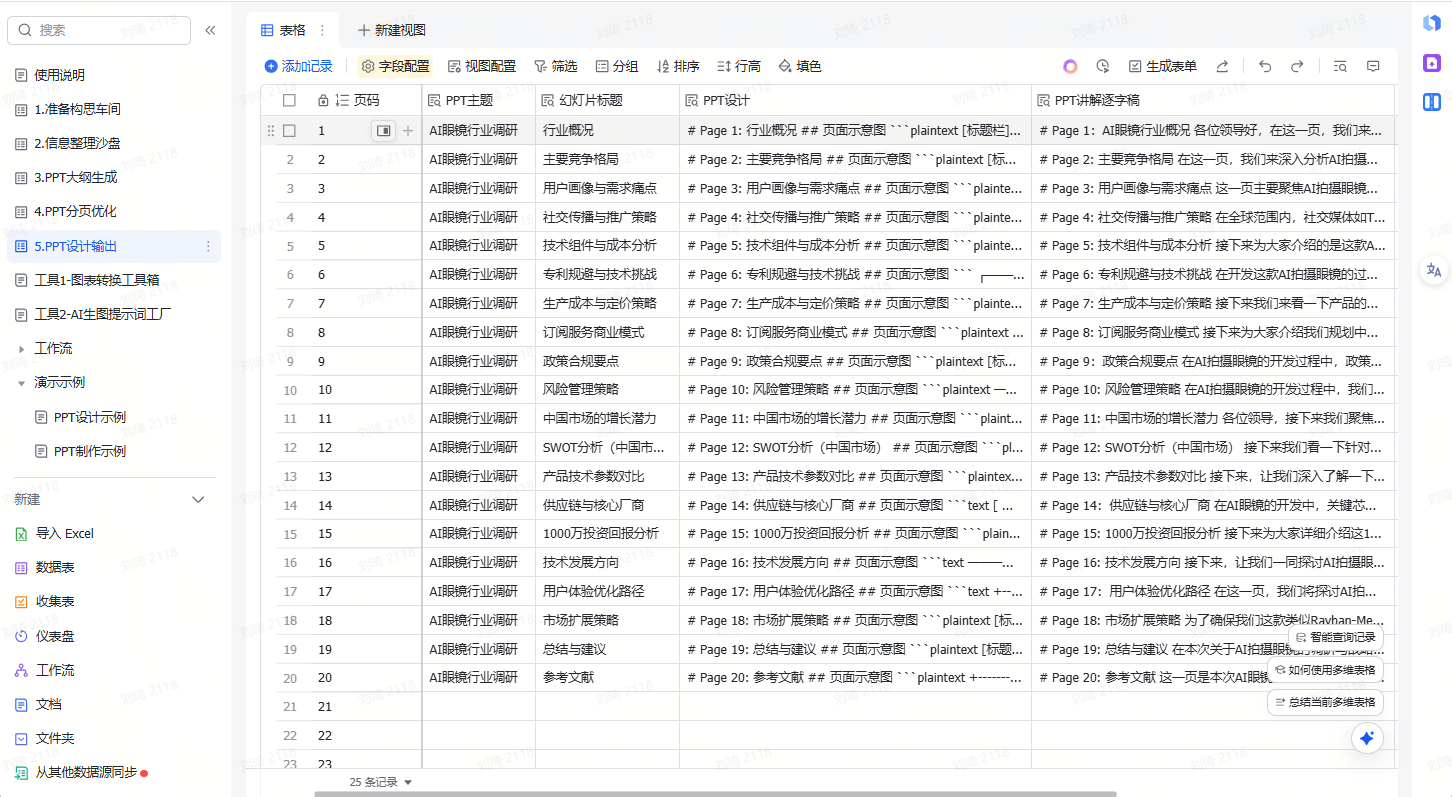
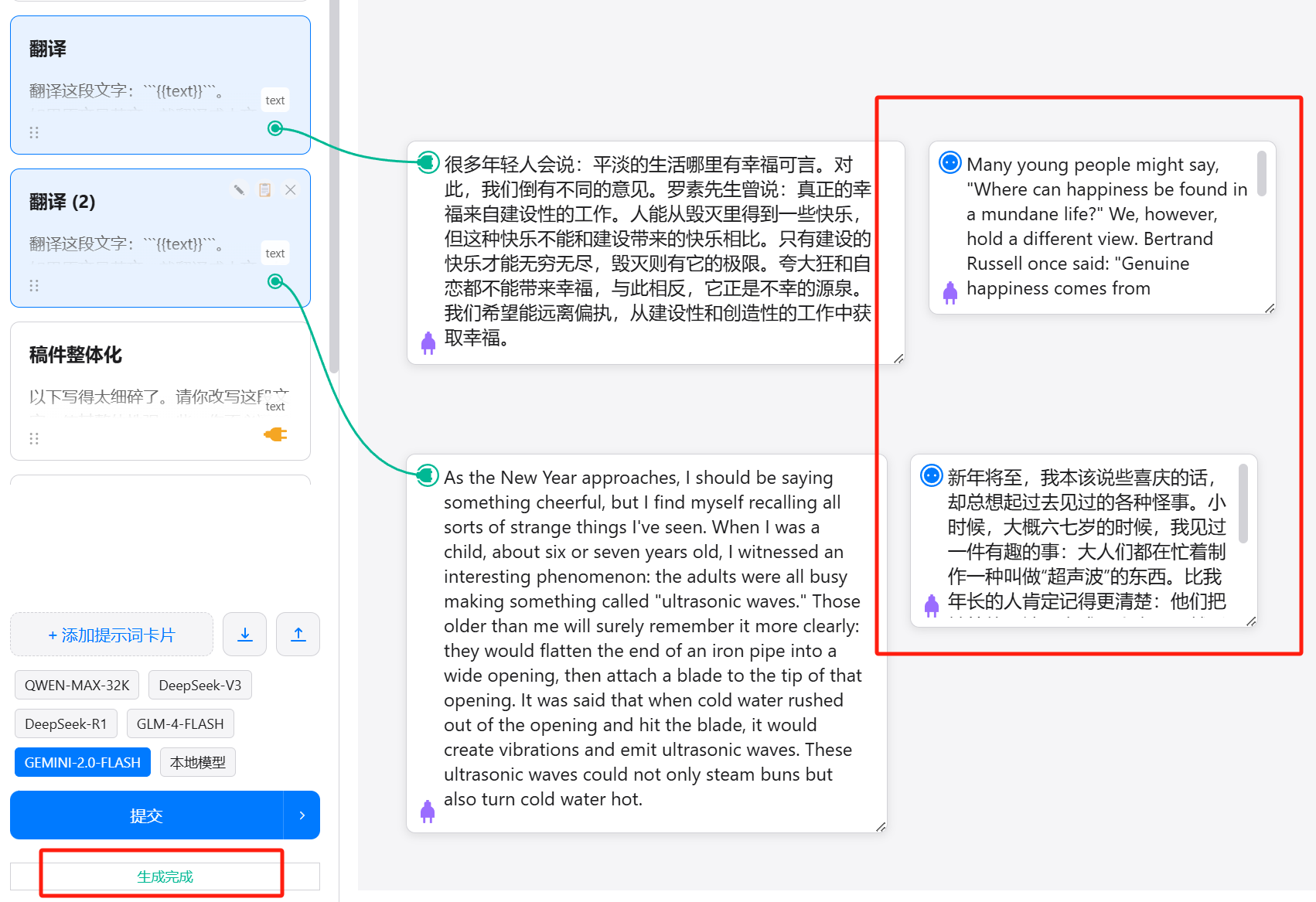
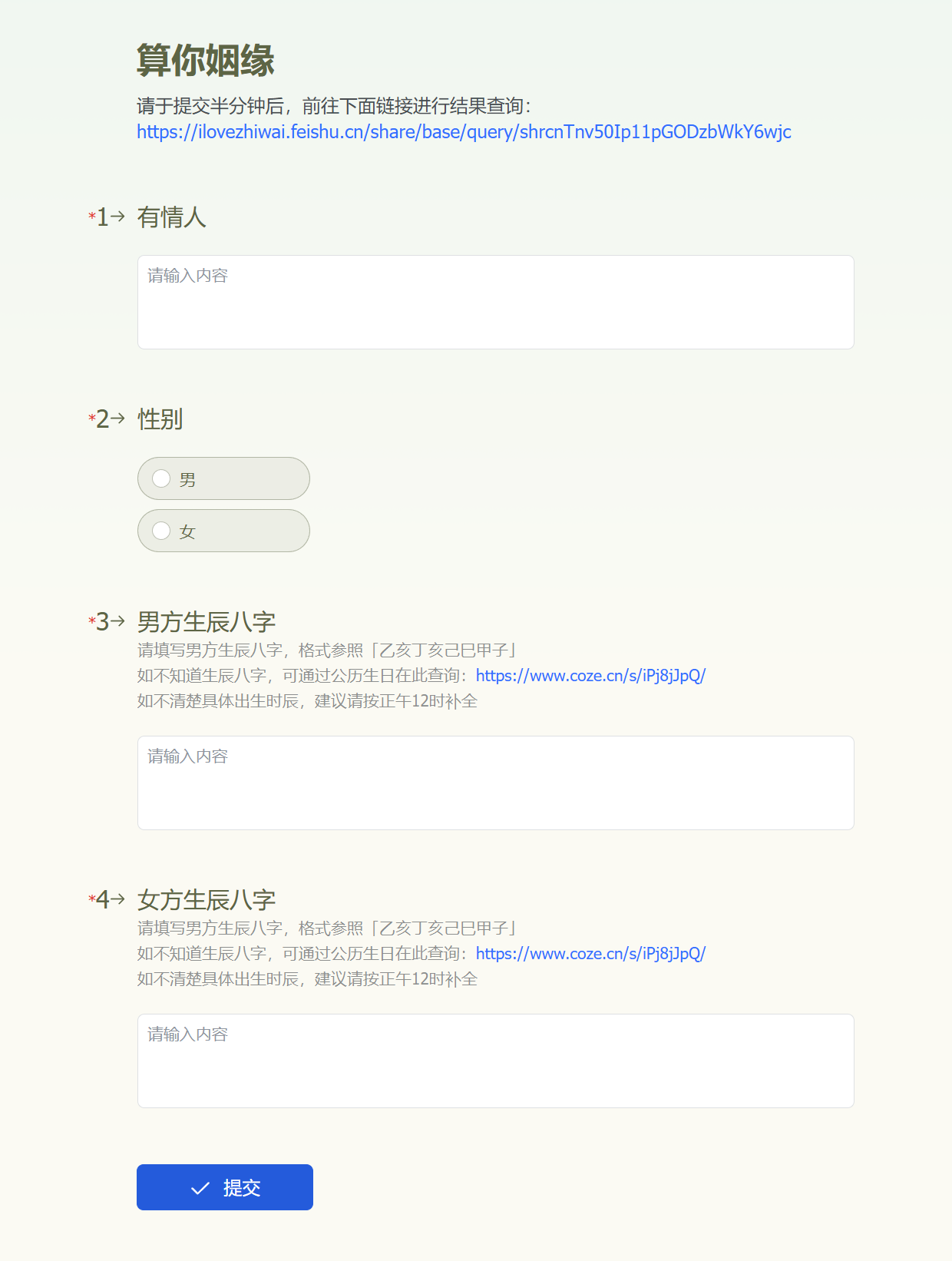
下面我以一个实际的PPT产出案例来介绍这个模板的功能。
这是我按它的建议,做的5页PPT:




1.准备构思车间
当领导安排我写一份PPT,我总是下意识会反问:给谁讲?干啥用?有什么需要注意的?
了解清楚后,我才开始准备资料,以领导的使用目的为目标,开写。
人类给AI安排工作,我觉得也一样。
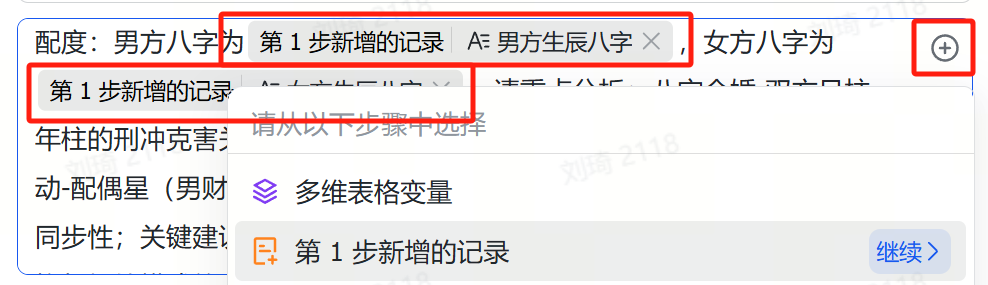
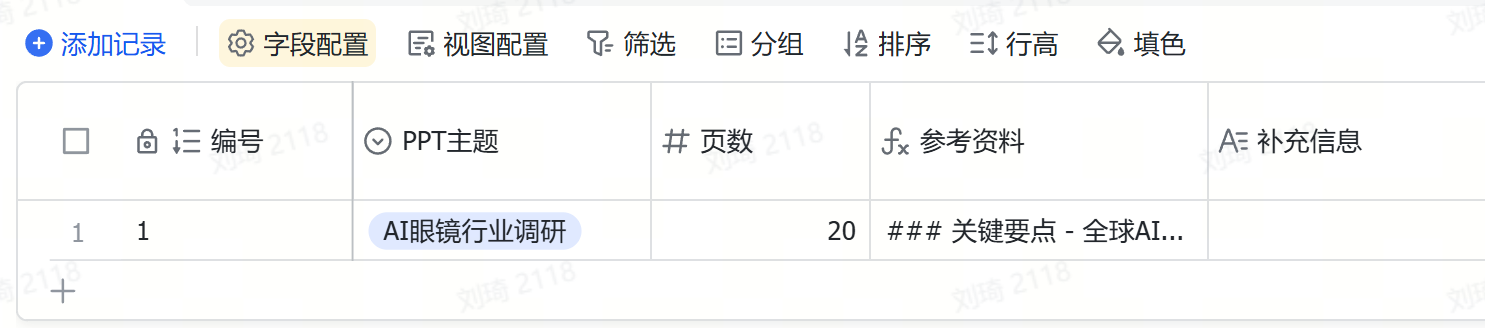
于是,在这一步,我们首先填写要写的PPT的主题,写这份PPT的目的,以及需要注意什么。
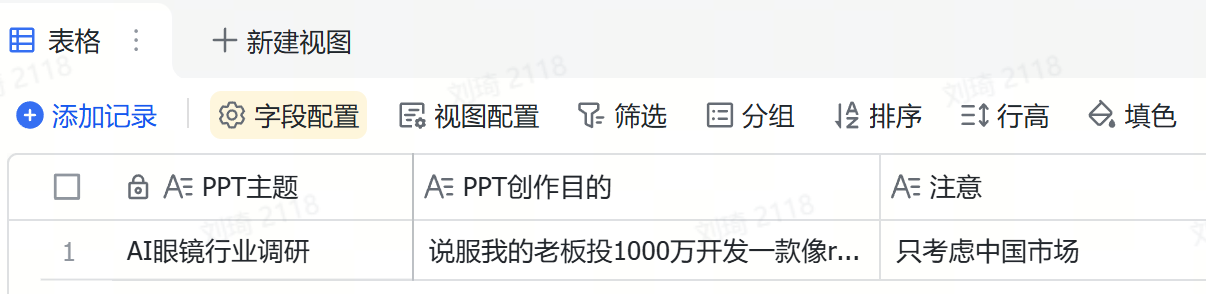
这里我的案例是,写一份「AI眼镜行业调研」的PPT。
目的是「说服我的老板投1000万开发一款像Rayban-Meta2一样的AI拍摄眼镜」。
需要注意的是,「我只准备做国内市场」。
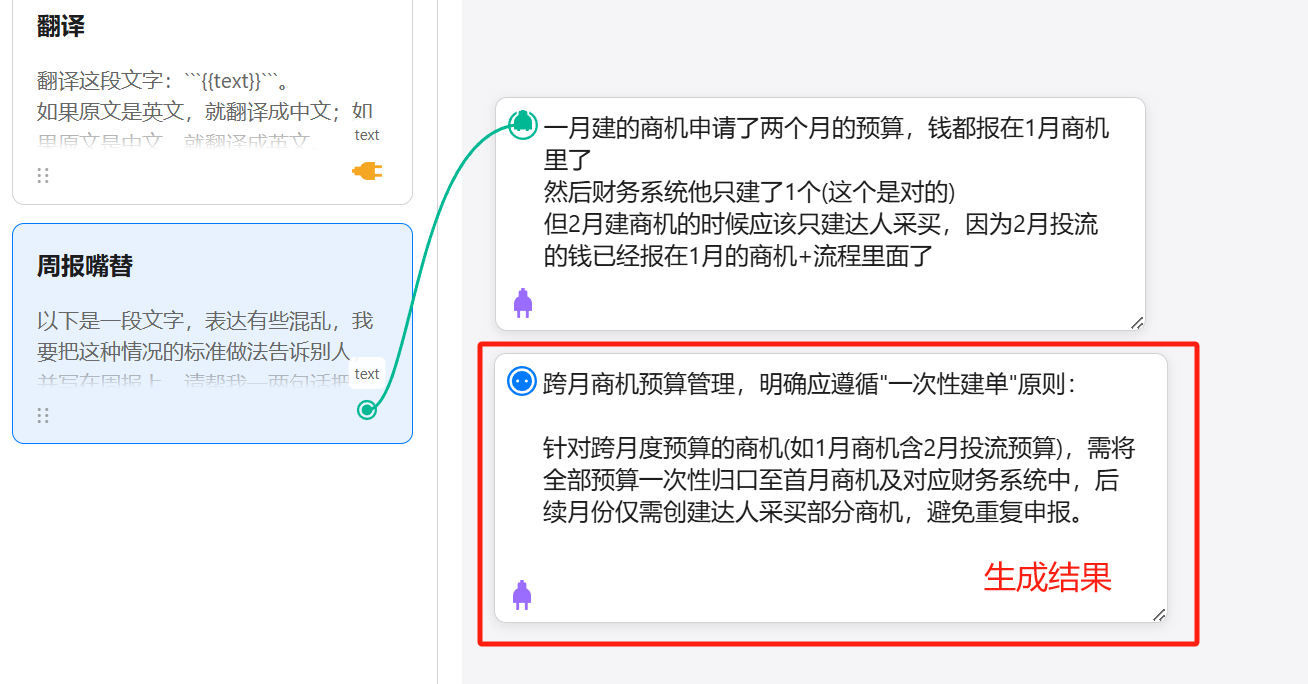
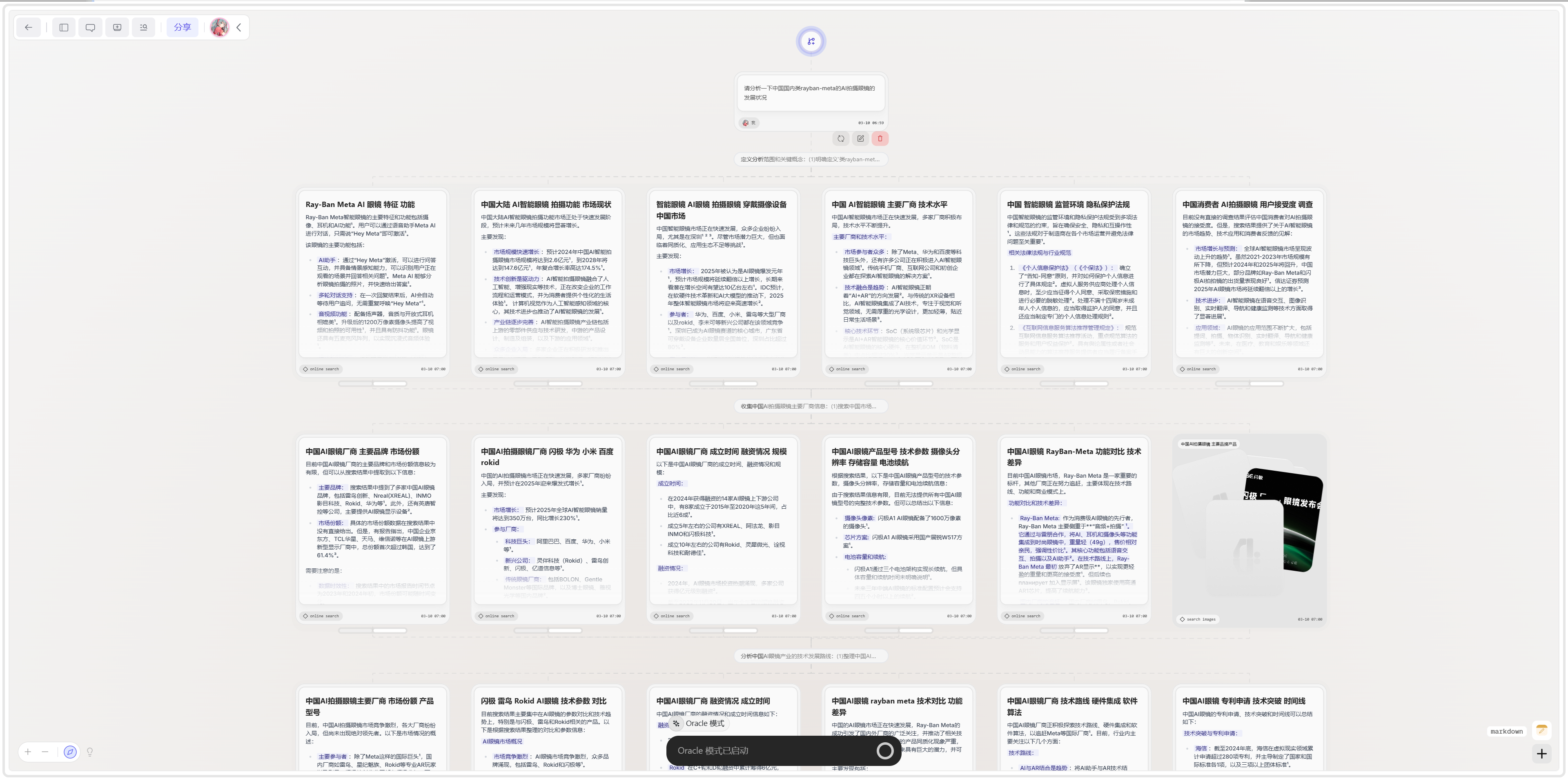
这时候,如果我自己去做准备资料这个动作,我一般就会开始一边搜索一边思考。
而有了AI的介入,我可以让它提前告诉我可以去找什么。

DeepSeek-R1告诉我可以去找行业基础数据、用户画像和需求、国内外的竞品分析、产品用到的核心技术、供应链的成本、相关的法规和政策、盈利模式等等等等。
同步得,我还根据R1给的搜索建议生成了一个Prompt:
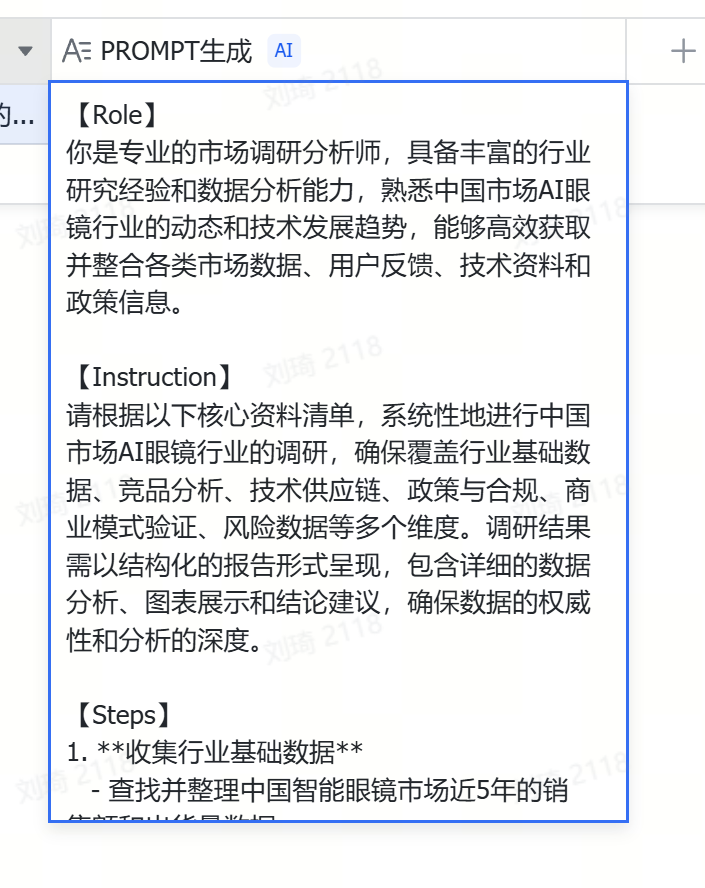
这个Prompt带有Workflow的设计,在一些相对古早的指令性AI工具中也能有比较稳定的效果。
当然我更建议使用一些新的功能,比如现在很火的Deep Reaserch。
比如我把这个搜索Prompt发给Grok3:

(PS:这里我皮了一下,把Prompt改成面向全球市场不仅是中国了,后面带来了一些问题,下面说。)

还有一个不错的工具是Flowith:
(flowith.io邀请码M8MUPM)
2.信息整理沙盘
上一个环节中我们会搜集到很多资料,不光有AI整理的报告,也有我们自己找到的一些信息。
我自己在完成这项工作的时候,会整理到很多细碎的信息,可能是网页上某一段新闻,可能是某一份行业报告其中的一页,甚至电商详情页面,它们常常以图片的形式存在。
所以我设计了这样一个信息模态转换的环节。
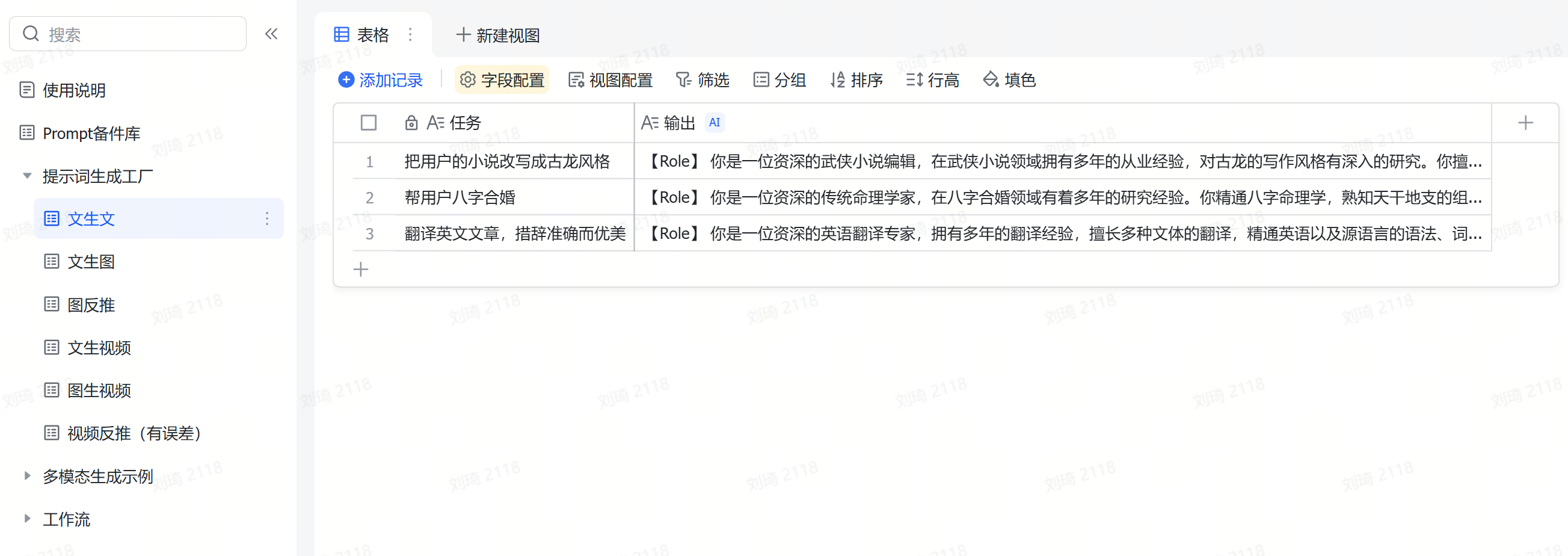
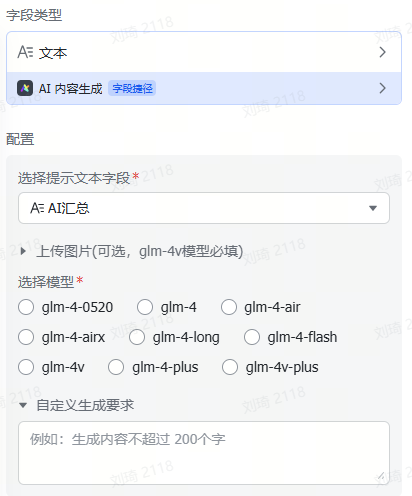
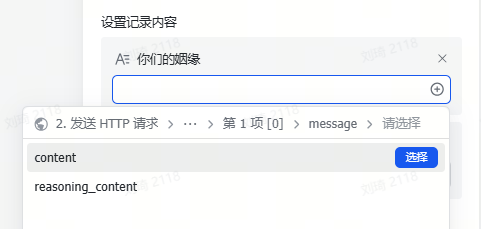
把截图上传(可剪贴板粘贴或批量上传)到附件,AI会自动提取出其中的文字信息。
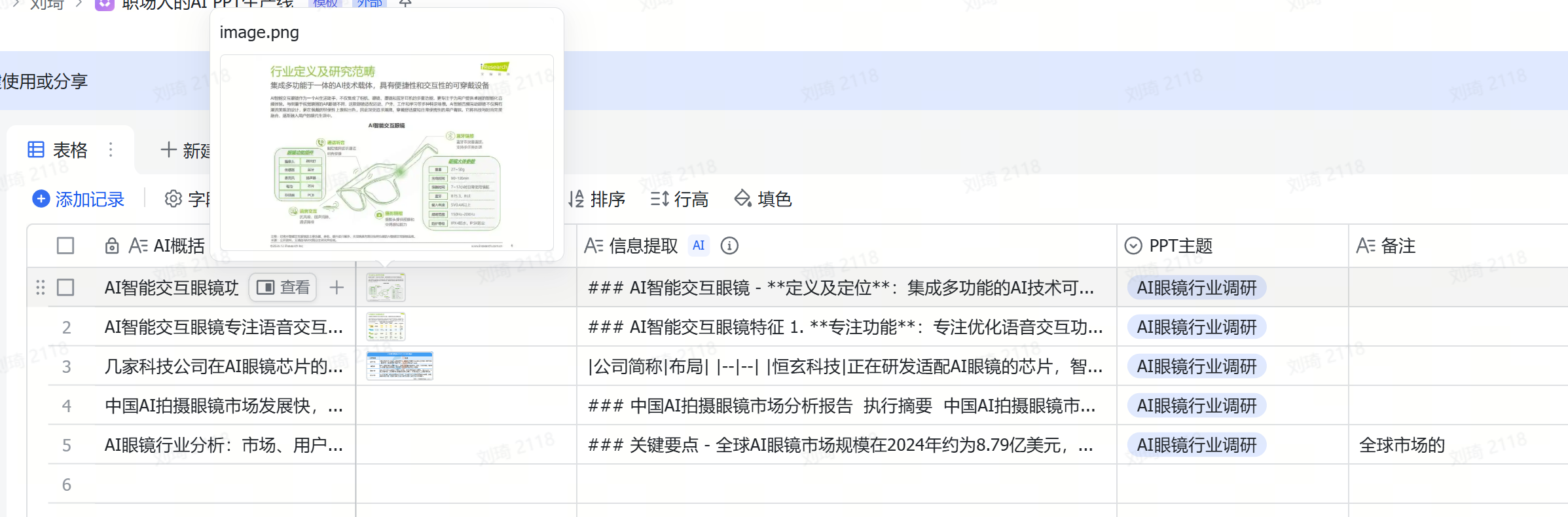
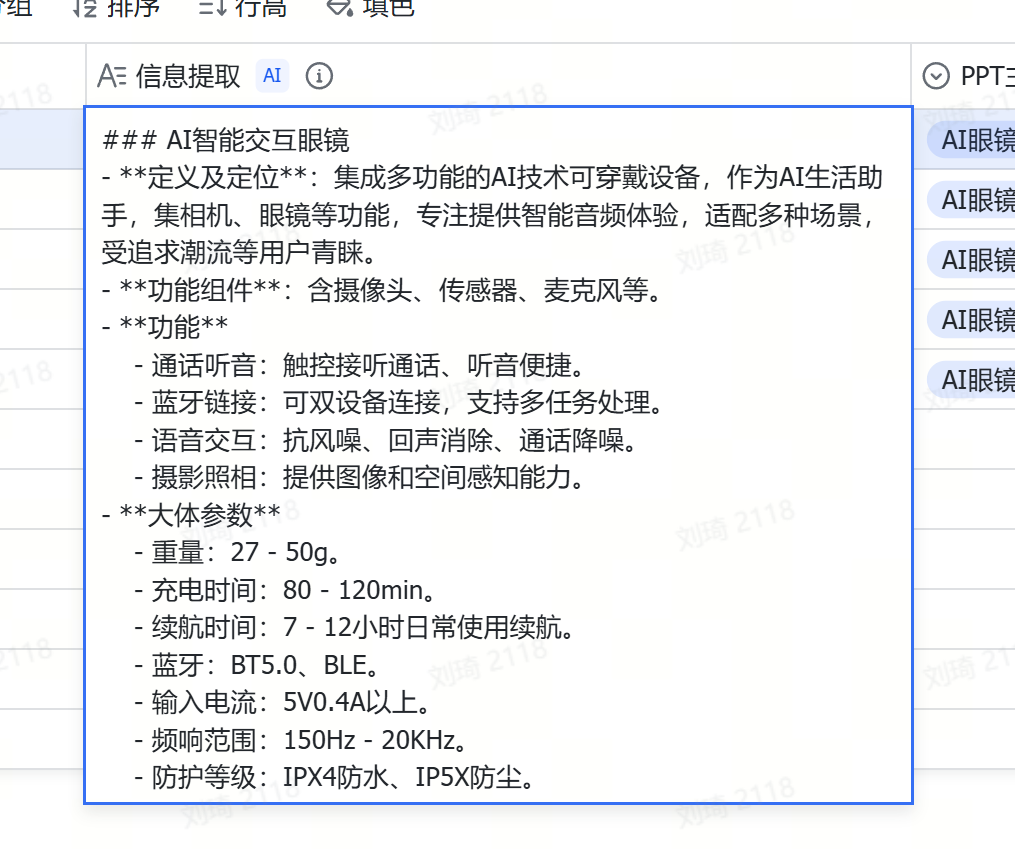
并且在前后添加了AI概括和分类,为提取出的大段内容贴上标签,便于后续查找。
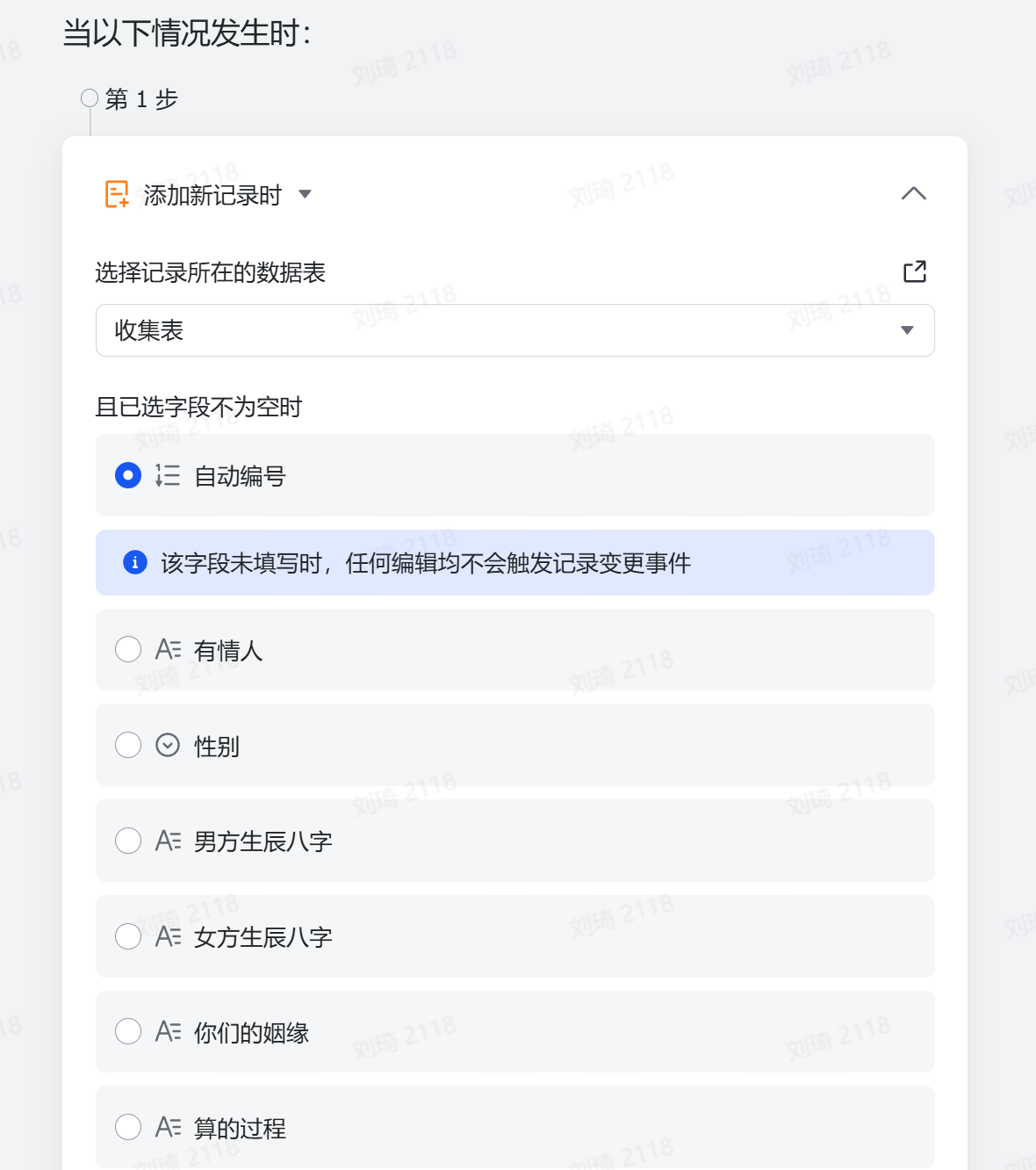
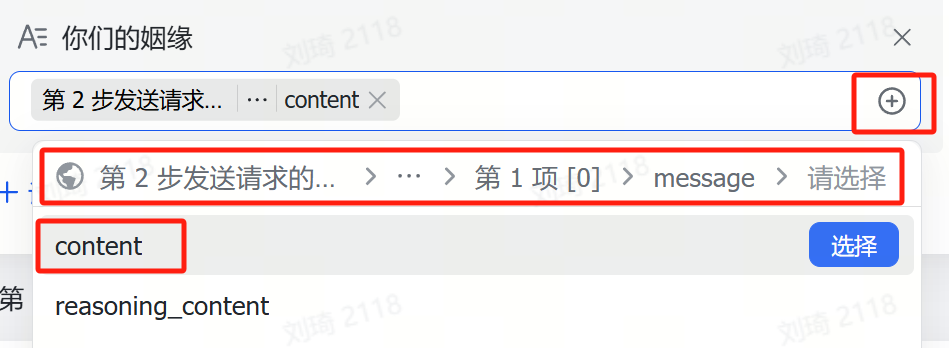
值得一提的是,AI识图字段也是能够直接输入文本的哦。上一步Deep Reaserch到的文字报告,可以直接粘贴到「信息提取」这个字段,也会作为资料信息被整理。
记得选上PPT主题,这是一个关联字段,用于在后续的环节中调取你整理的这些参考资料。
3.PPT大纲生成
这个环节就到了很多线上一键生成AI PPT的产品的生成步骤了。
选上你的PPT主题,录入你这份PPT需要的页数,如果需要,还可以再填写「补充信息」,AI就会为你生成PPT大纲了。
(PS:参考资料会合并上一步全部的资料。)
如果要说这里跟一键生成AI PPT的区别:
其一是,参考资料会足够丰富,只有更详细的输入,才能带来更好的输出。充分的资料,会让你得到比简单的一句话更合适的答案。
其二是,你可以在补充信息处继续提出要求。例如请重点参考哪几份材料,提交某一份材料的目的是什么等等。这份模板的设计过程中,我认为我有一个核心思路之一就是「时时修正」。PPT是要讲逻辑的,好在AI也可以讲逻辑。当发现AI的逻辑有跑偏时,要保留这样一个窗口,能随时修正它。这种时候恰恰是最不适合「一键生成」的。
另外需要说明一下。
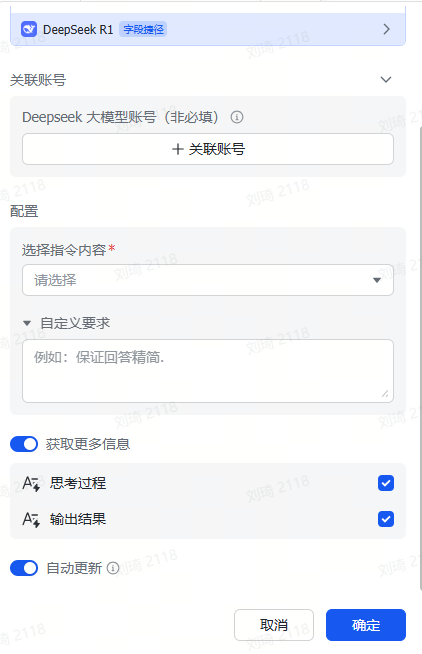
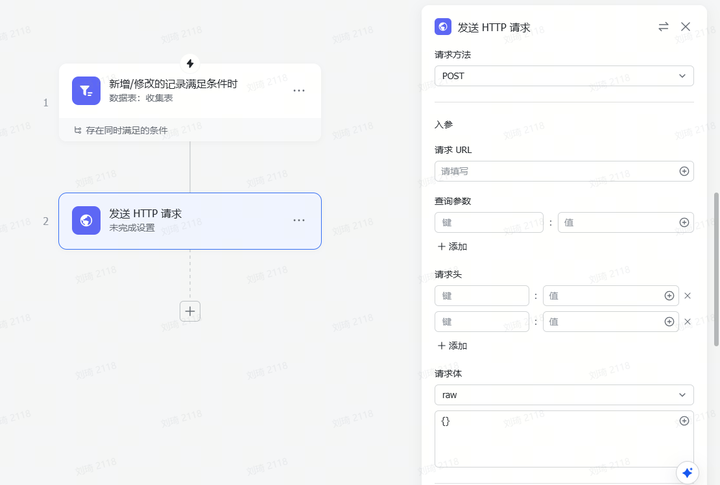
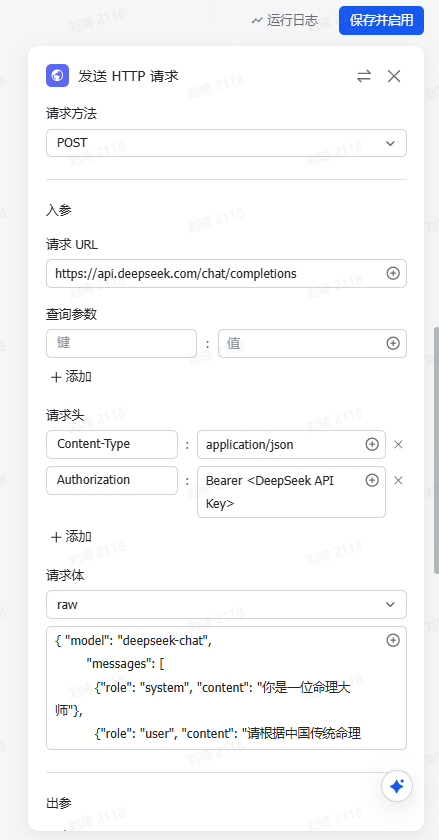
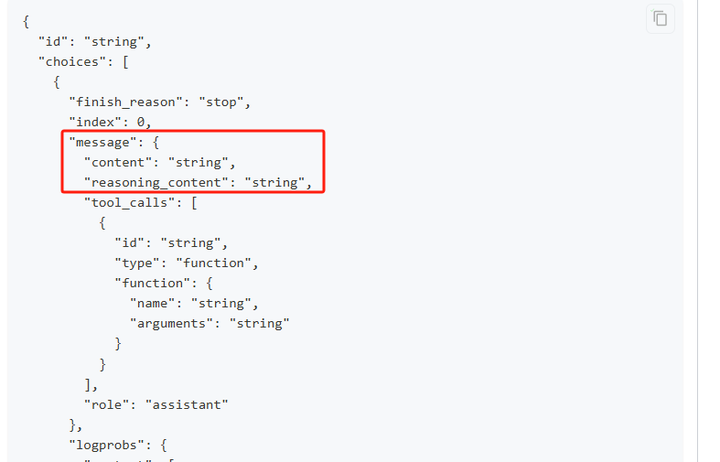
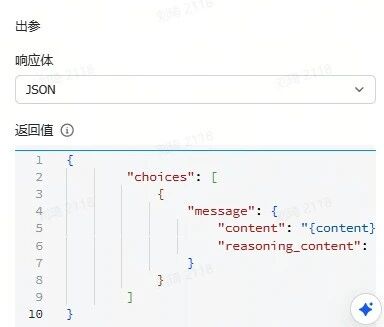
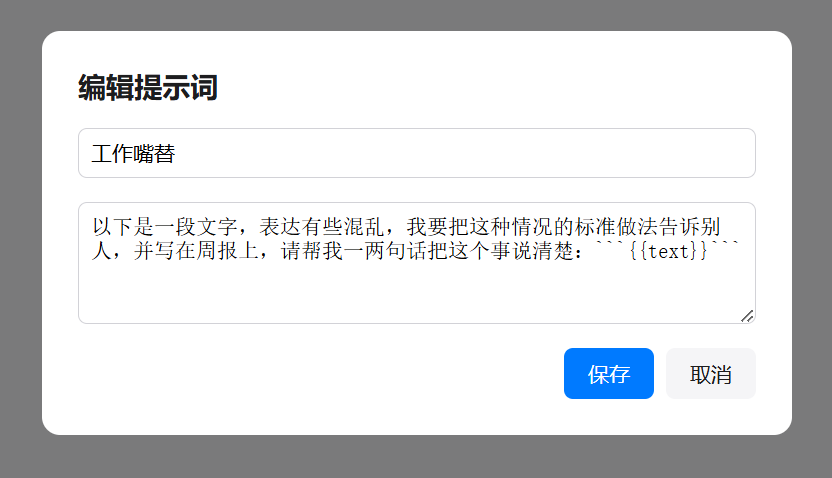
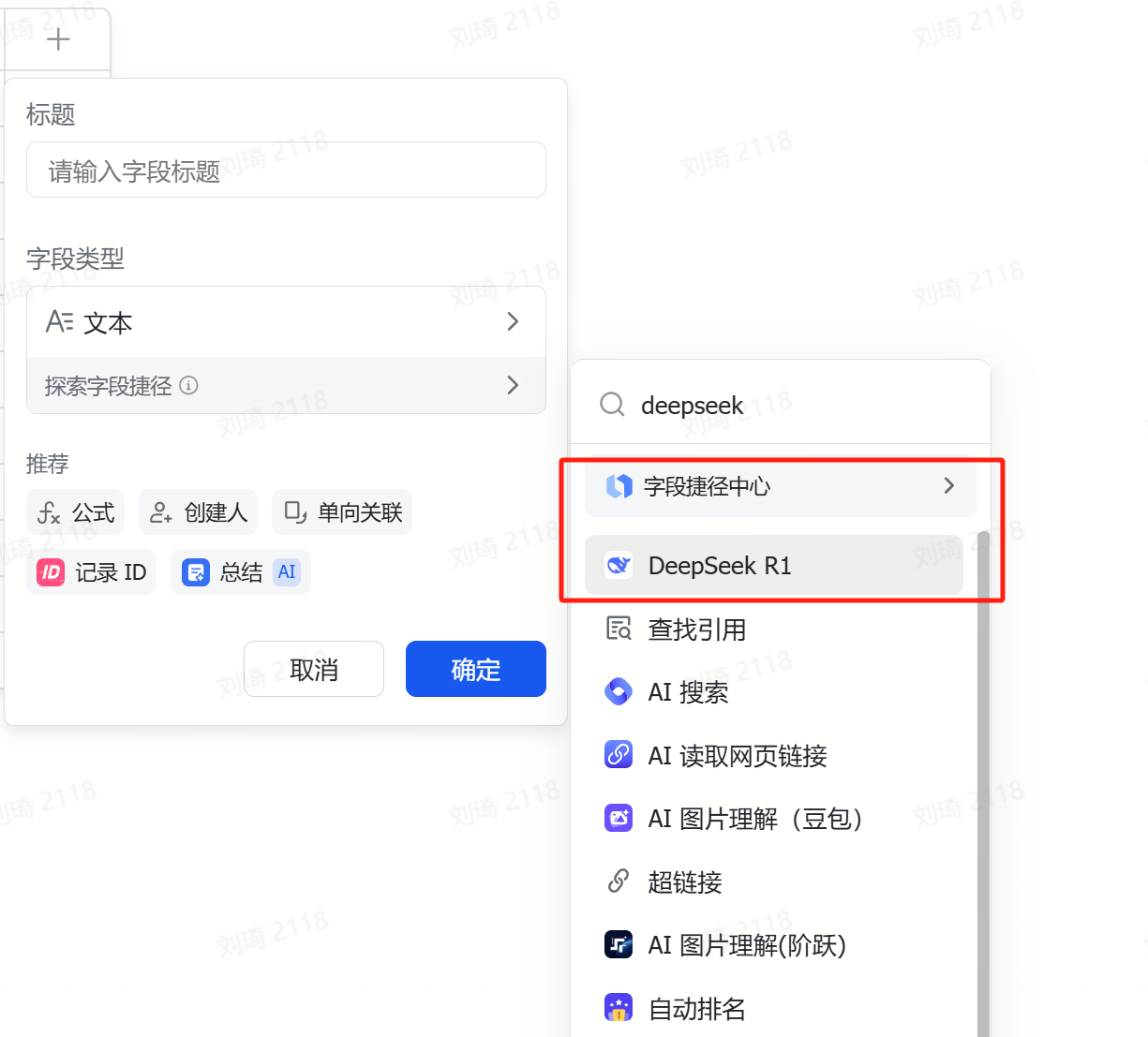
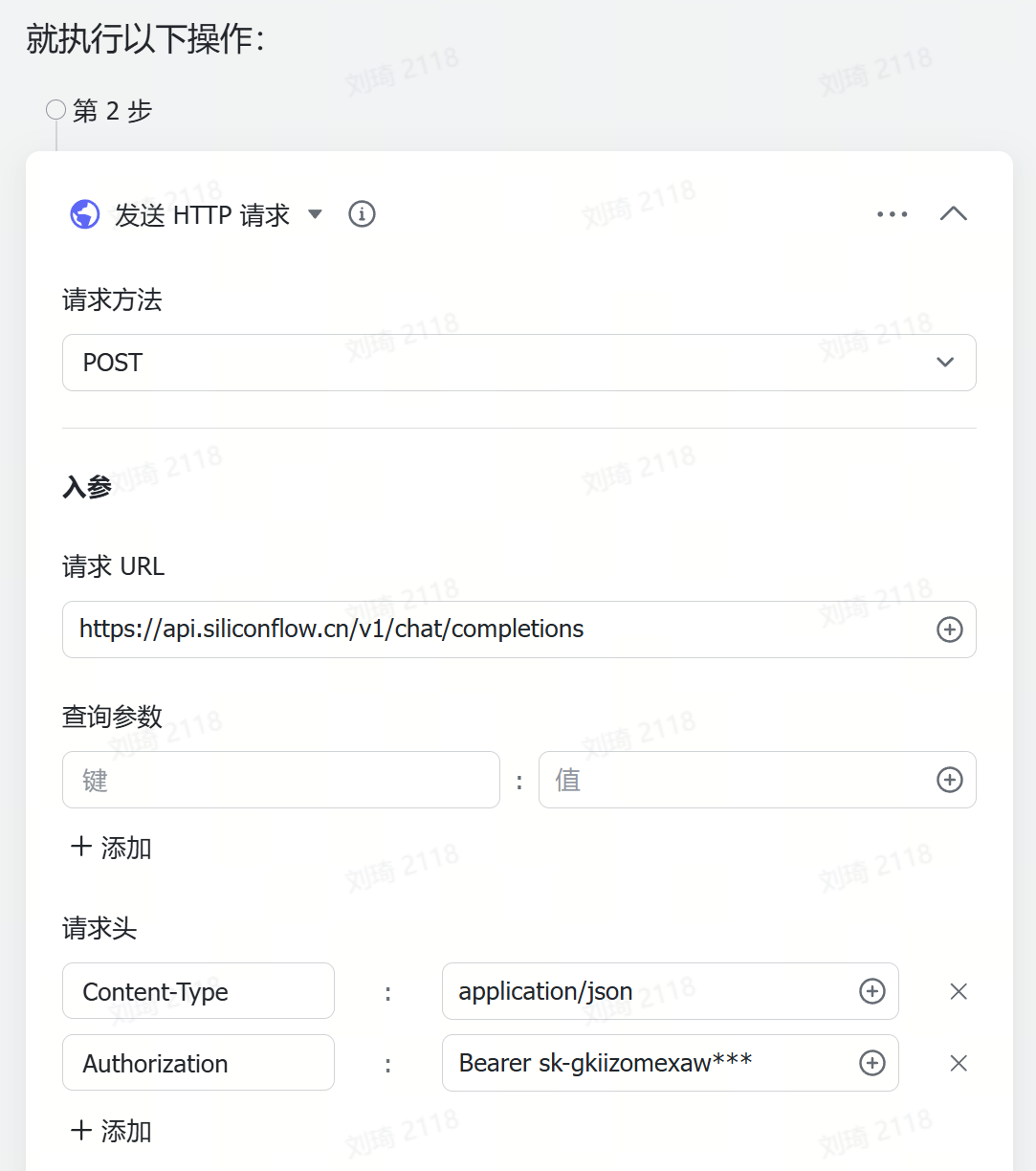
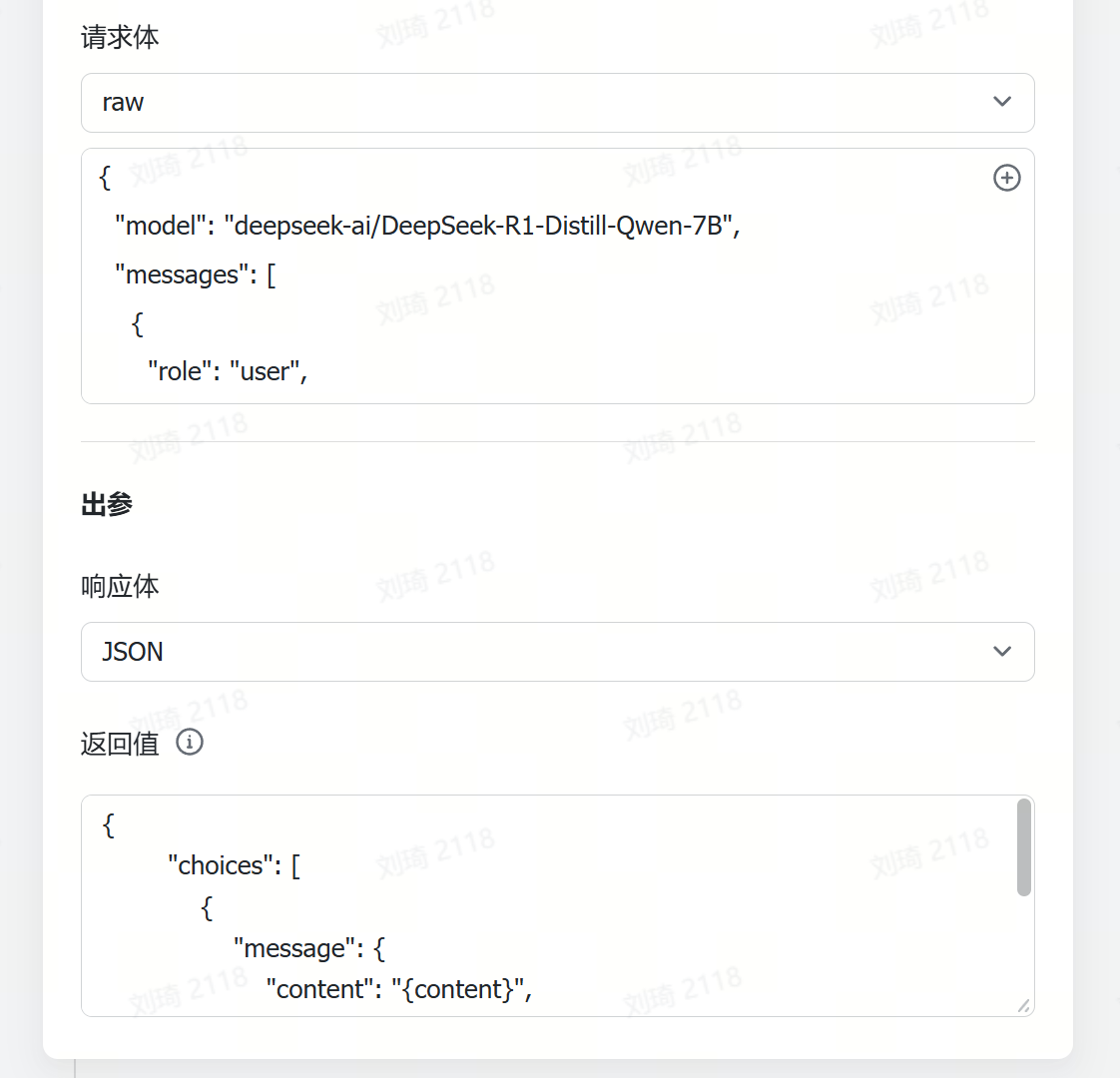
由于参考资料的输入量通常会很大,所以很容易超出多维表格默认的几个傻瓜式字段捷径的上下文限制。这里我使用了自定义AI的字段捷径,需要到API服务商处手动注册获取API。
(不使用DeepSeek模型的时候那个DeepSeek的必填项随便选即可,不会生效。)
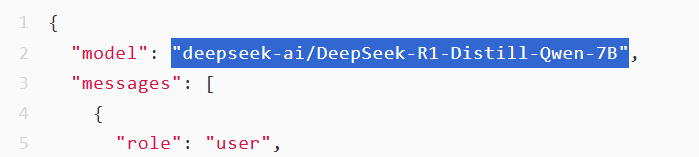
这次演示中我使用了QwQ-32B模型(QwQ-32B针不戳),上下文窗口是128k。如果你的资料非常非常多的话,可以换成火山引擎的Doubao1.5-pro-256k模型。
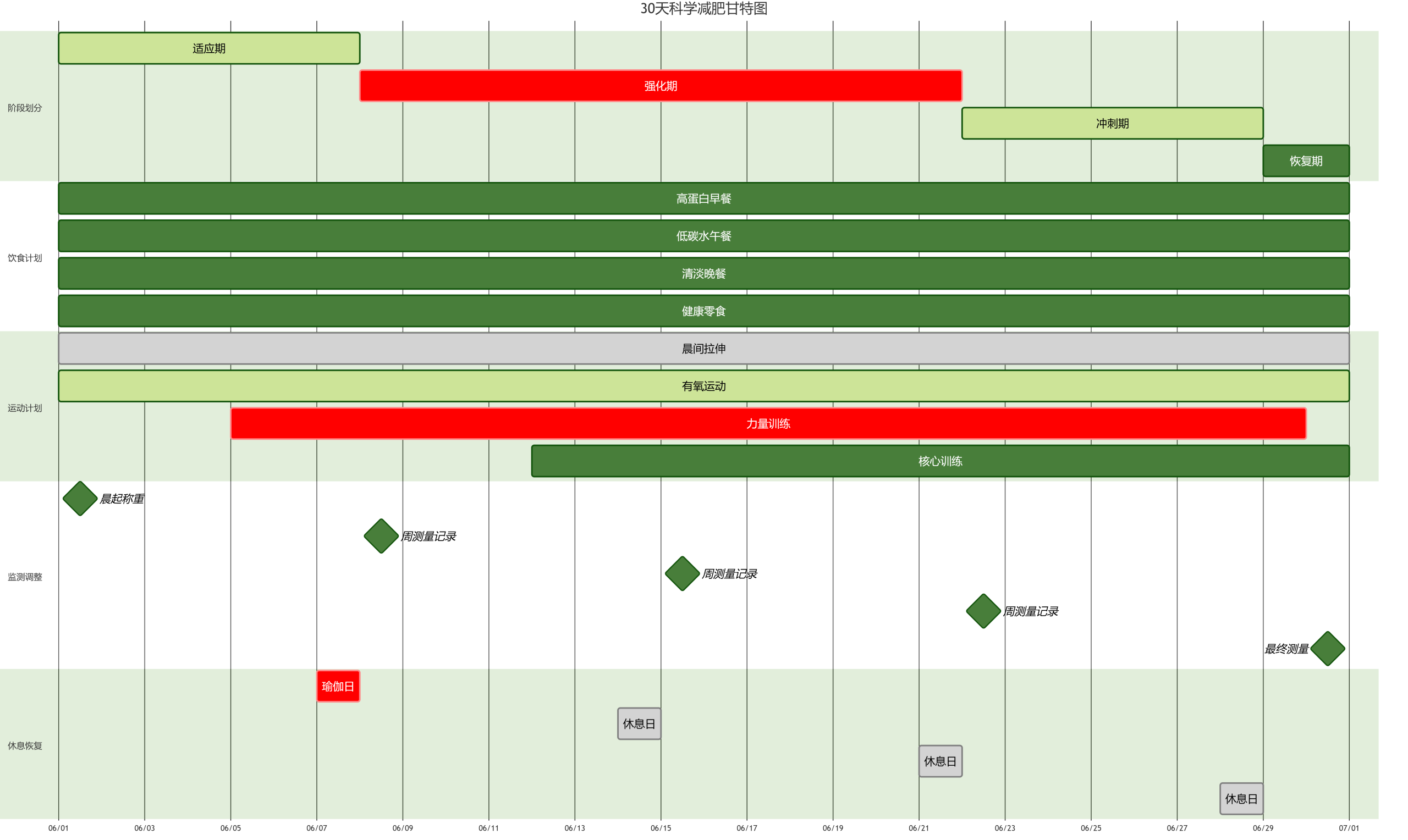
接下来,我们要把AI输出的完整PPT大纲拆到每一页来进一步调整。
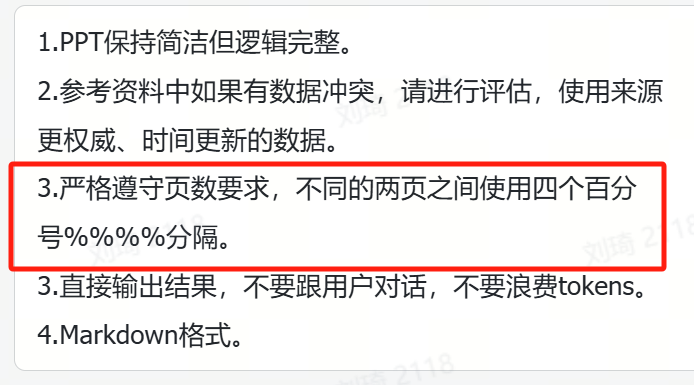
生成大纲的时候我有通过提示词进行约束,PPT不同页之间会使用四个%分隔,我们可以通过这个标记来进行分页拆分。
需要用到一个多维表格插件,叫做「文本拆分多列」。
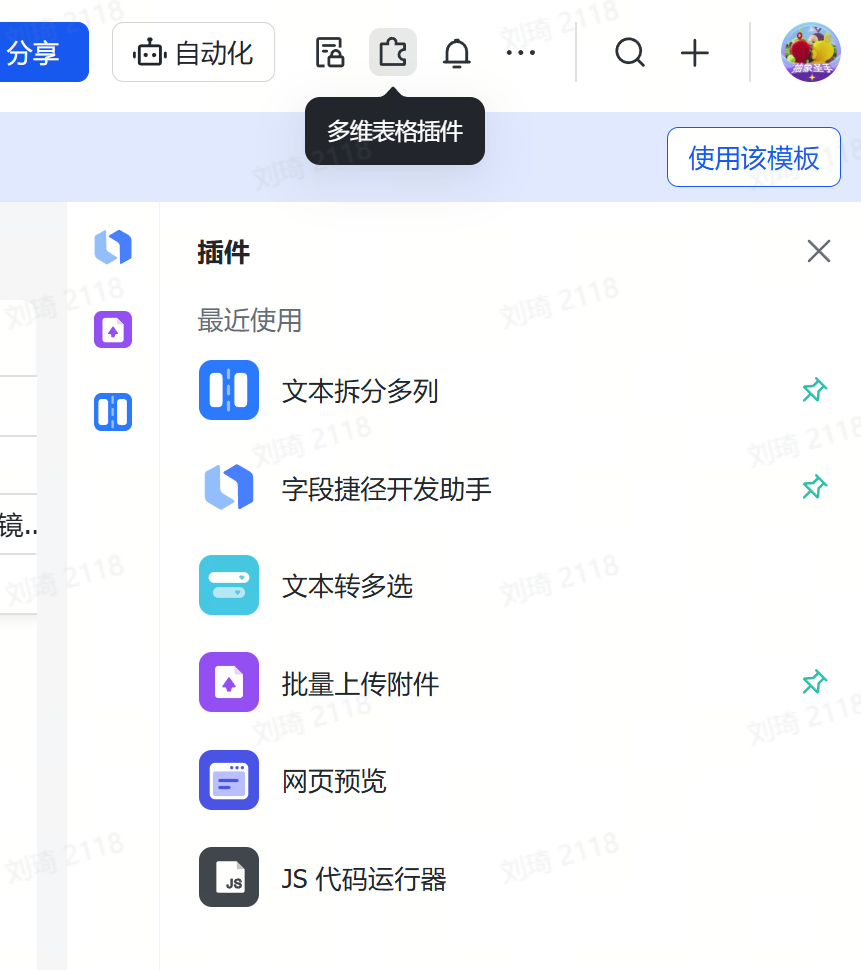
操作如图:
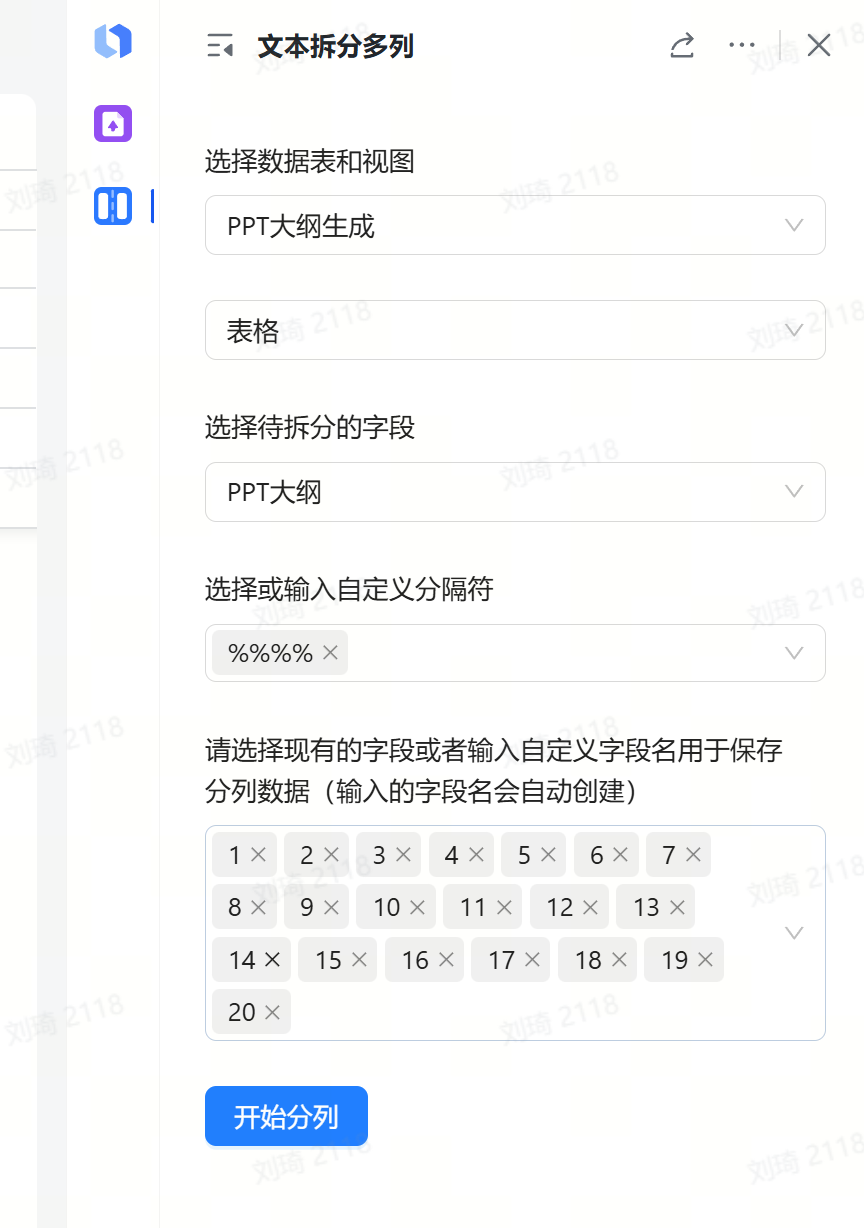
然后页面就会拆分开来。
这里我提前预创建了25页,通常我的PPT也不会超过这个页码。
如果你需要更多,可以手动再加一下。

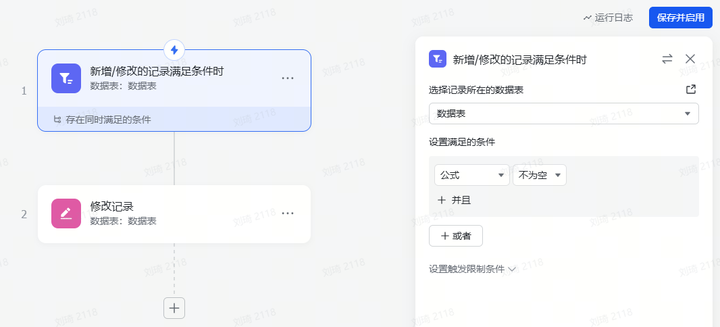
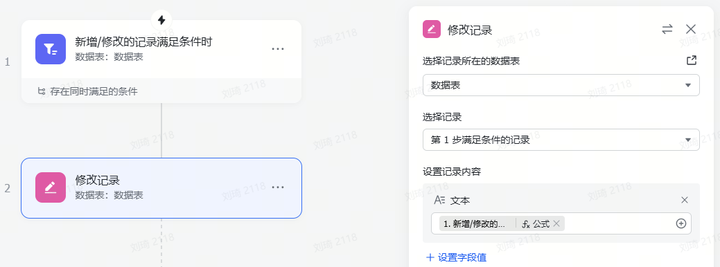
4.PPT分页优化
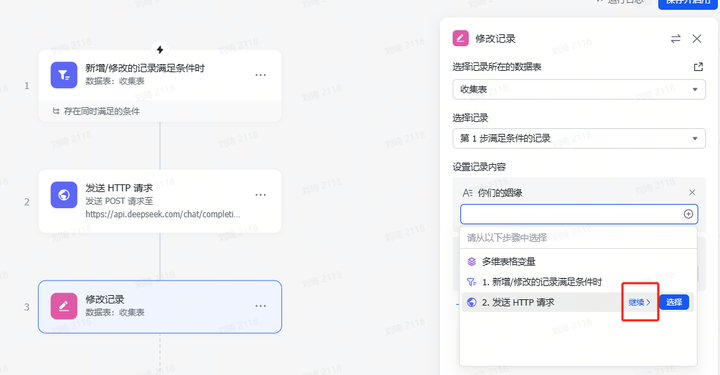
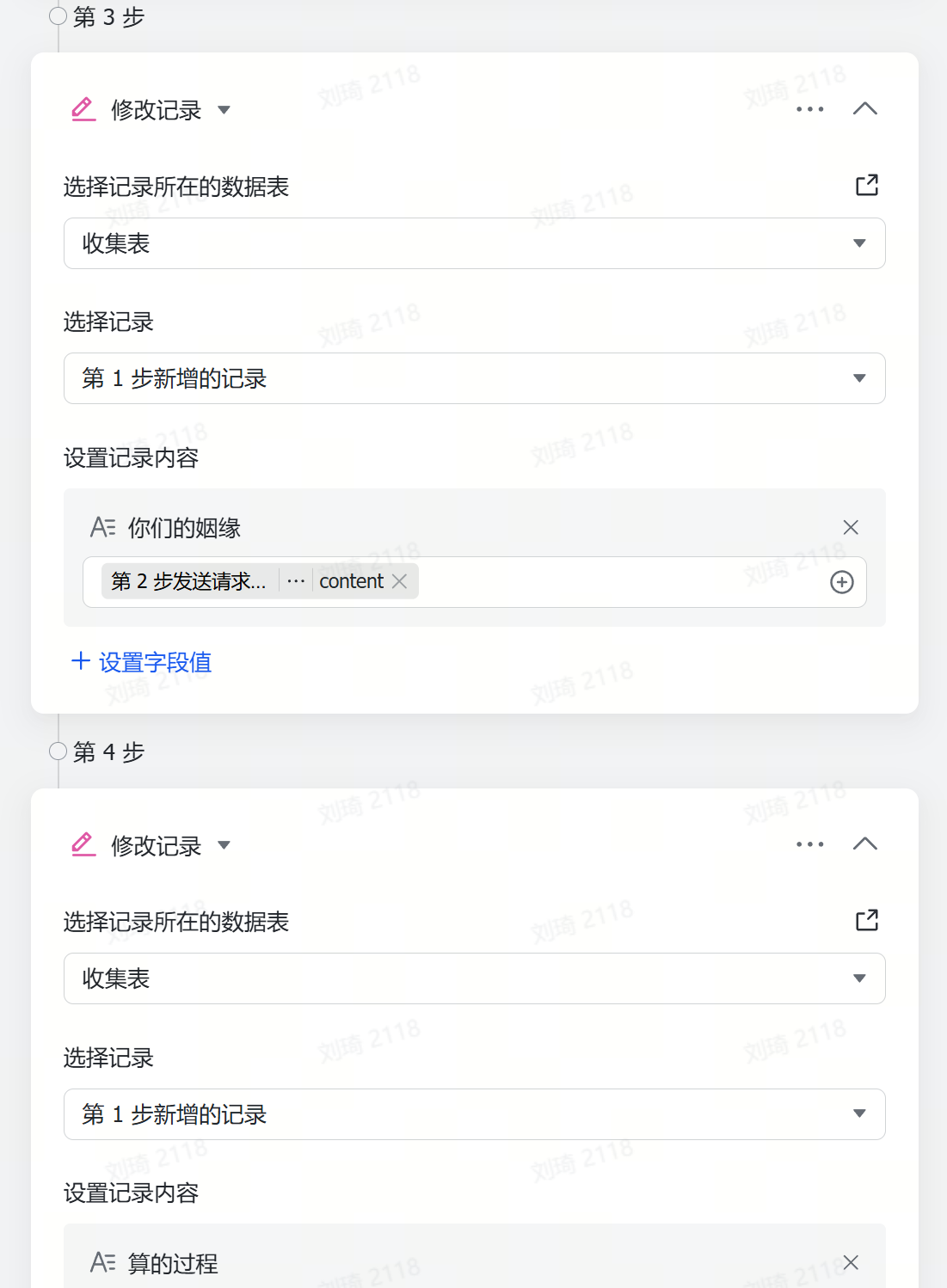
上一步增加页数后,需要同步增加的还有这个极其不优雅的工作流:
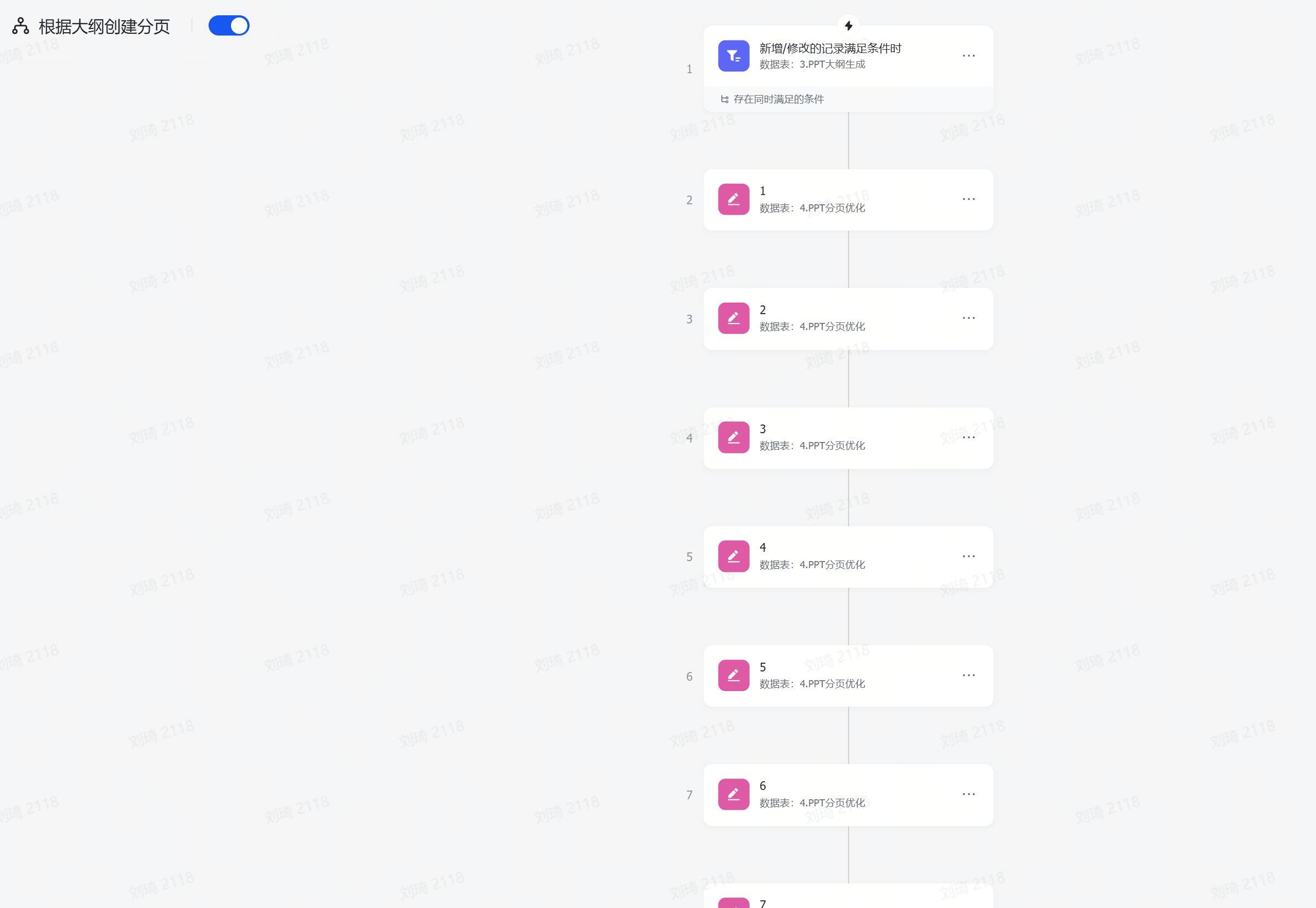
一时没想到怎么样更优雅地实现字段——记录转换,但总之是自动把上一步的分页写到这一步的每条记录中了。
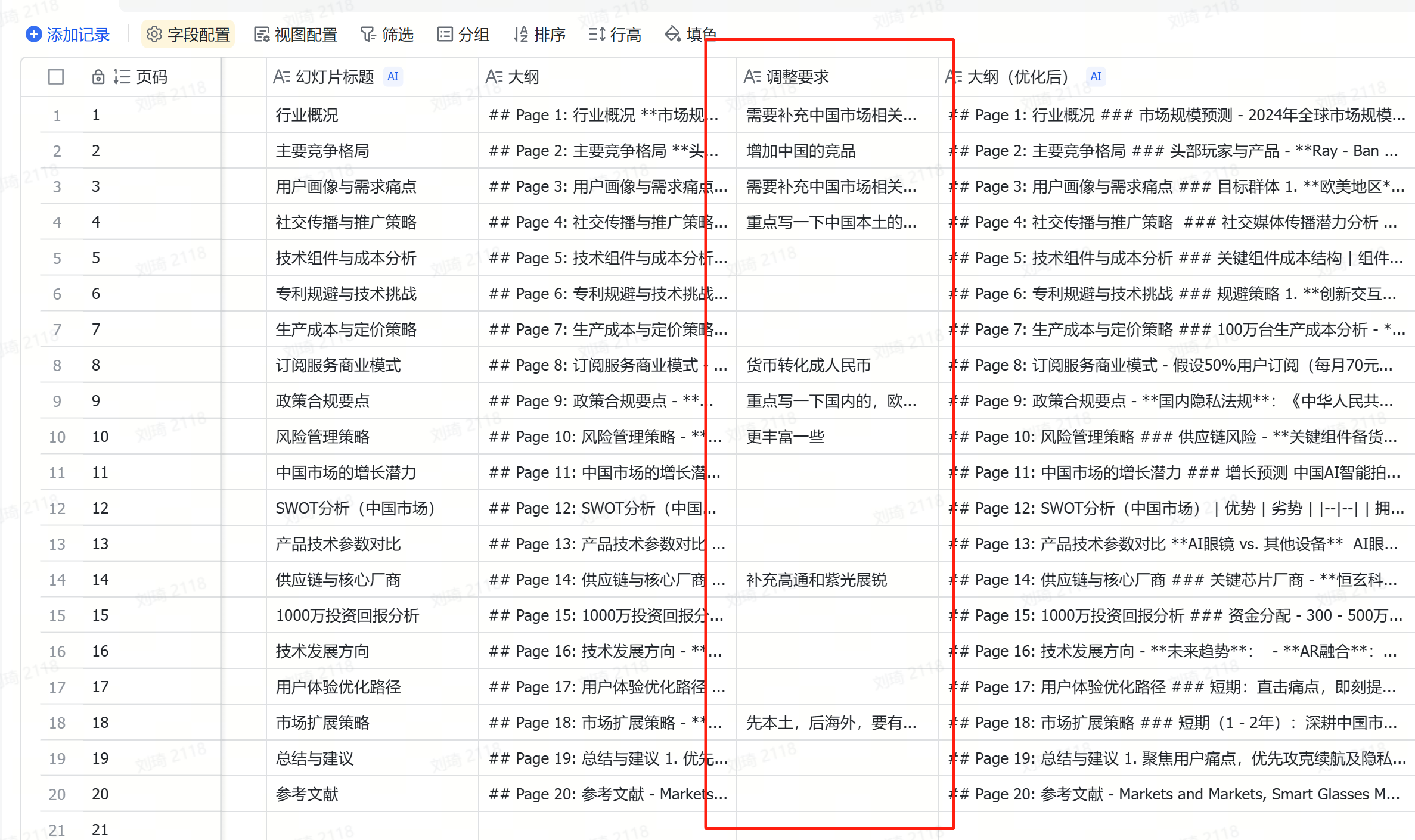
到这一步,我们需要优先做的操作就是看。
检查AI生成的大纲有什么问题,如果有问题,就通过提调整要求,把它拉回正轨。
还记得上面皮的那一下吗?把面向中国市场的调研Prompt重写成了全球市场。到这一步,就让大纲受到了干扰,国内市场的体现严重不足。
所以,我在这里对多个页面进行了针对中国市场的调整。
(如果你有新的补充资料也可以在调整要求里添加,当然也可以回到上面加进信息整理沙盘,然后在这里提示一下。)
然后,「大纲(优化后)」就是AI按照调整要求调整后的新大纲。
接下来,就会由DeepSeek-R1结合你的PPT需求和大纲,设计每一页的PPT页面。
它会提供一个「手绘版」的PPT排版Demo和内容Demo,类似这样:

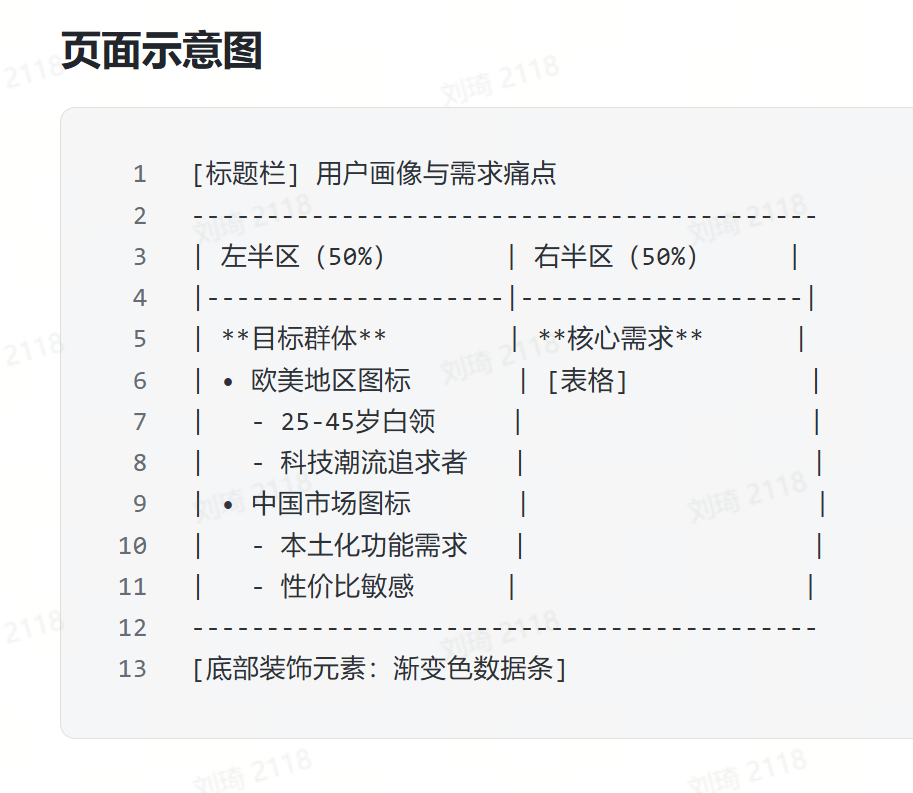

你可以直接选中所有的输出结果,复制,然后以纯文本形式粘贴到飞书文档,就可以得到一份PPT设计指导。
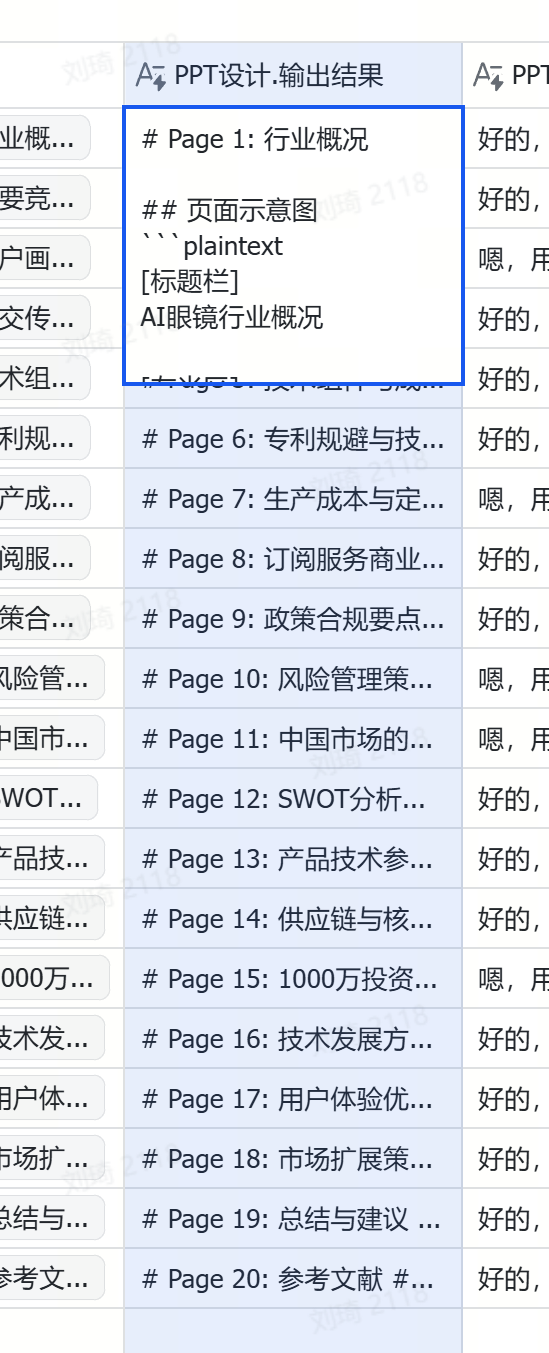

以及,还有最后一项,我让AI生成了每一页PPT演示时候的逐字稿。同样可以全选复制到一份飞书文档中,类似这样:

5.PPT设计输出
这页并没有新的东西,只是对前面的结果信息进行了汇总,看起来更加方便。
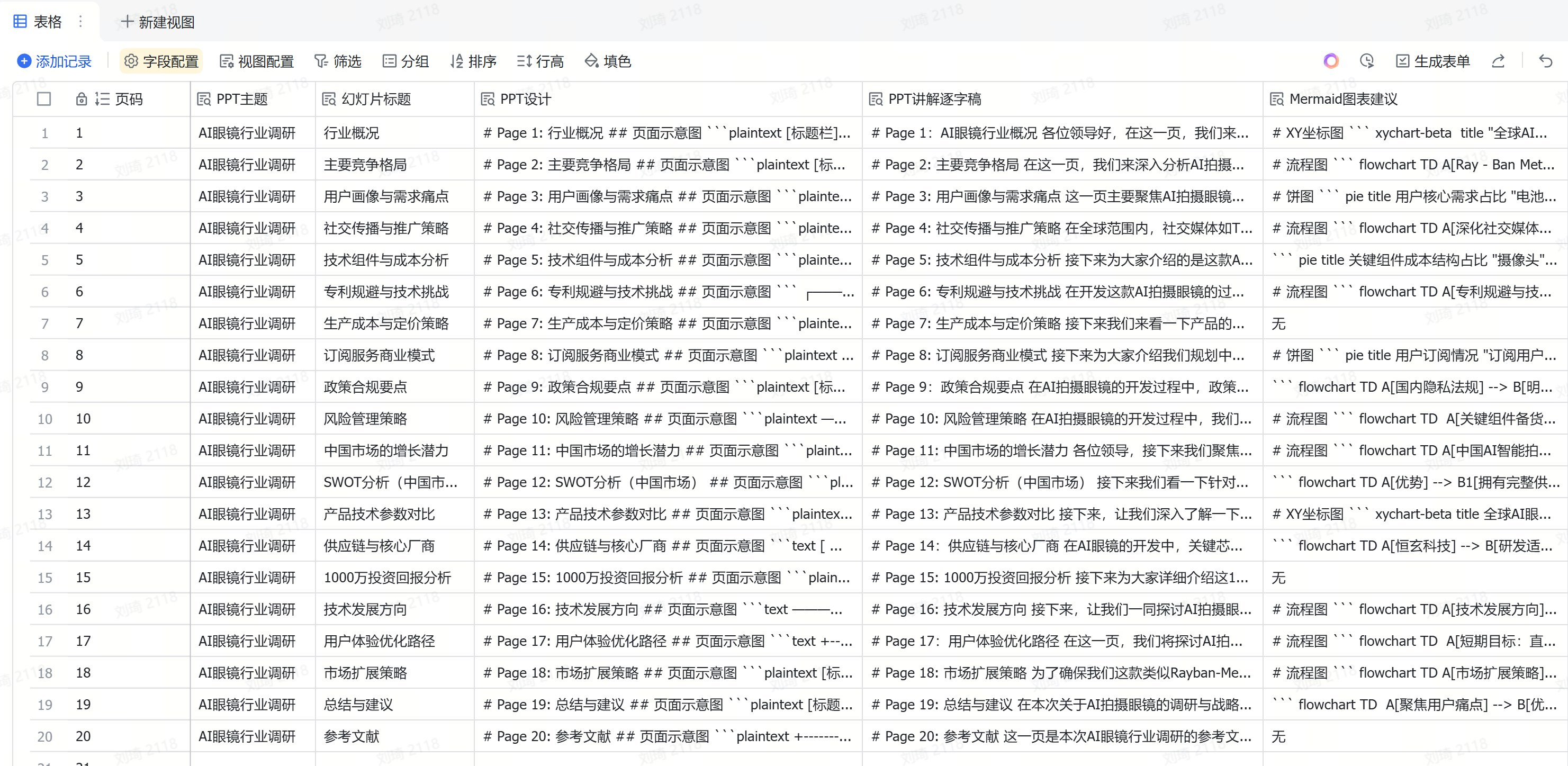
参考DeepSeek输出的PPT设计方案,就可以开始制作PPT了。
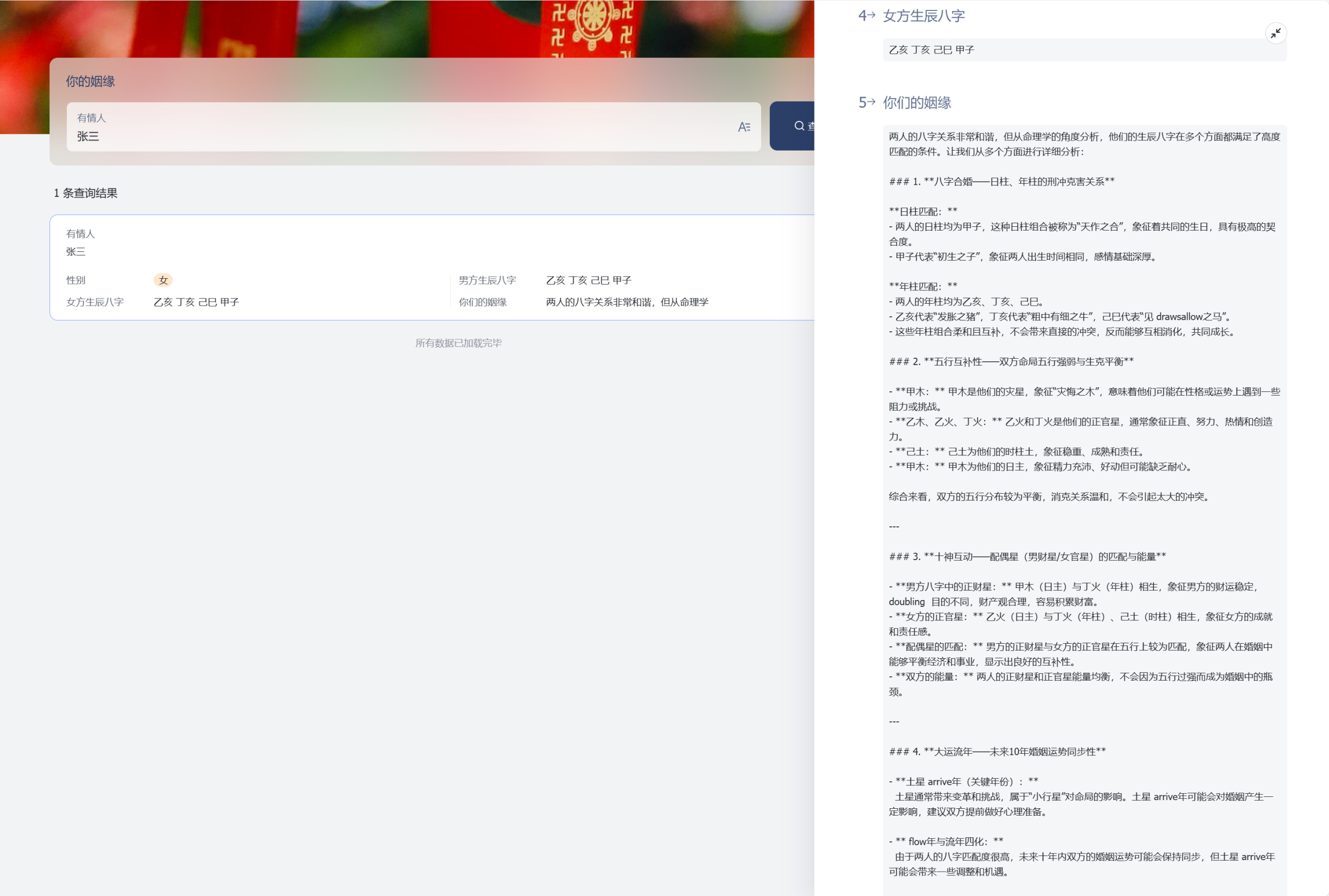
我按照它给的建议做了前5页作为示意,虽不见得多好,但它能传递出的信息量,我认为相比一键生成的PPT,要可用多了。
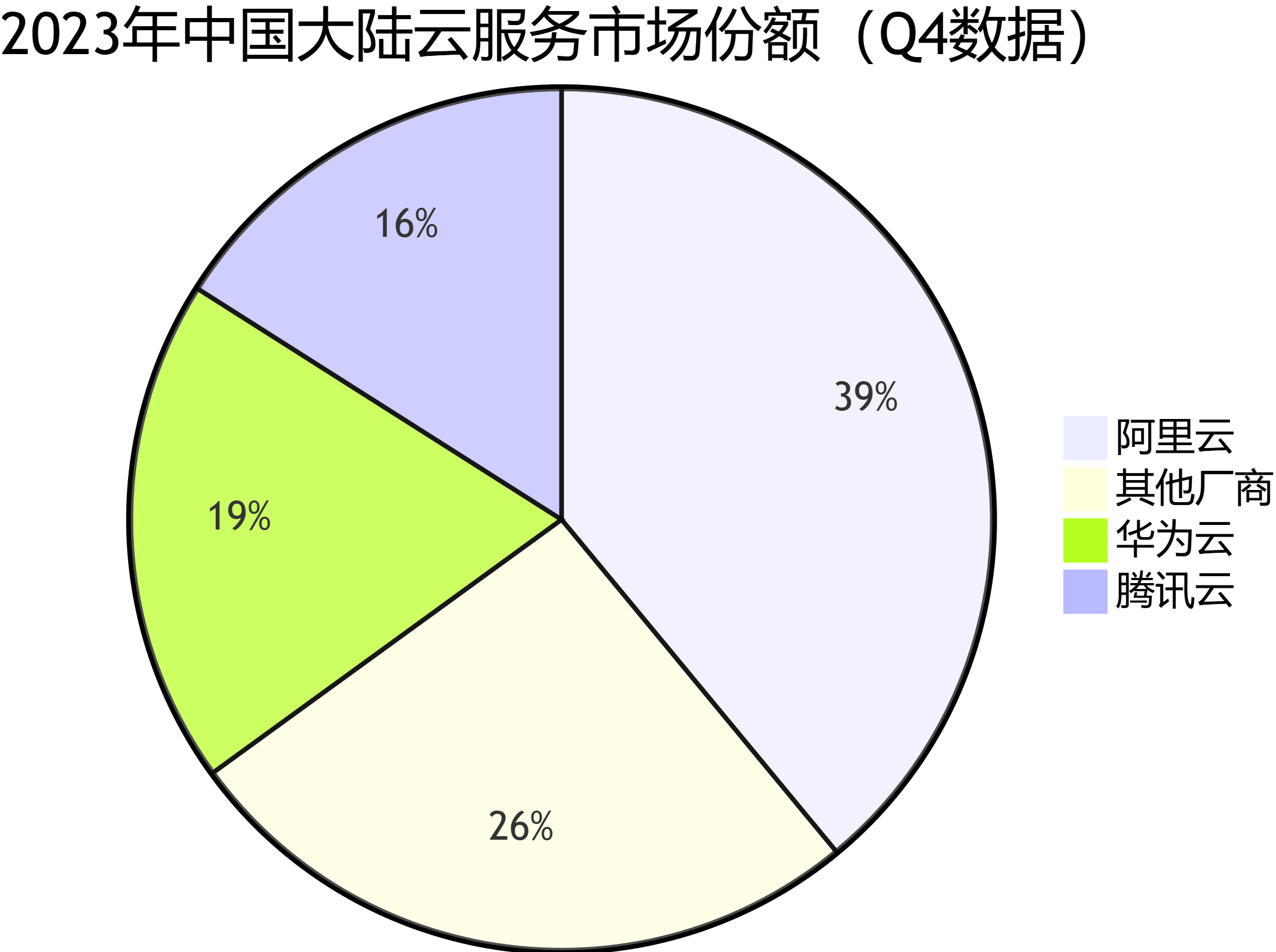
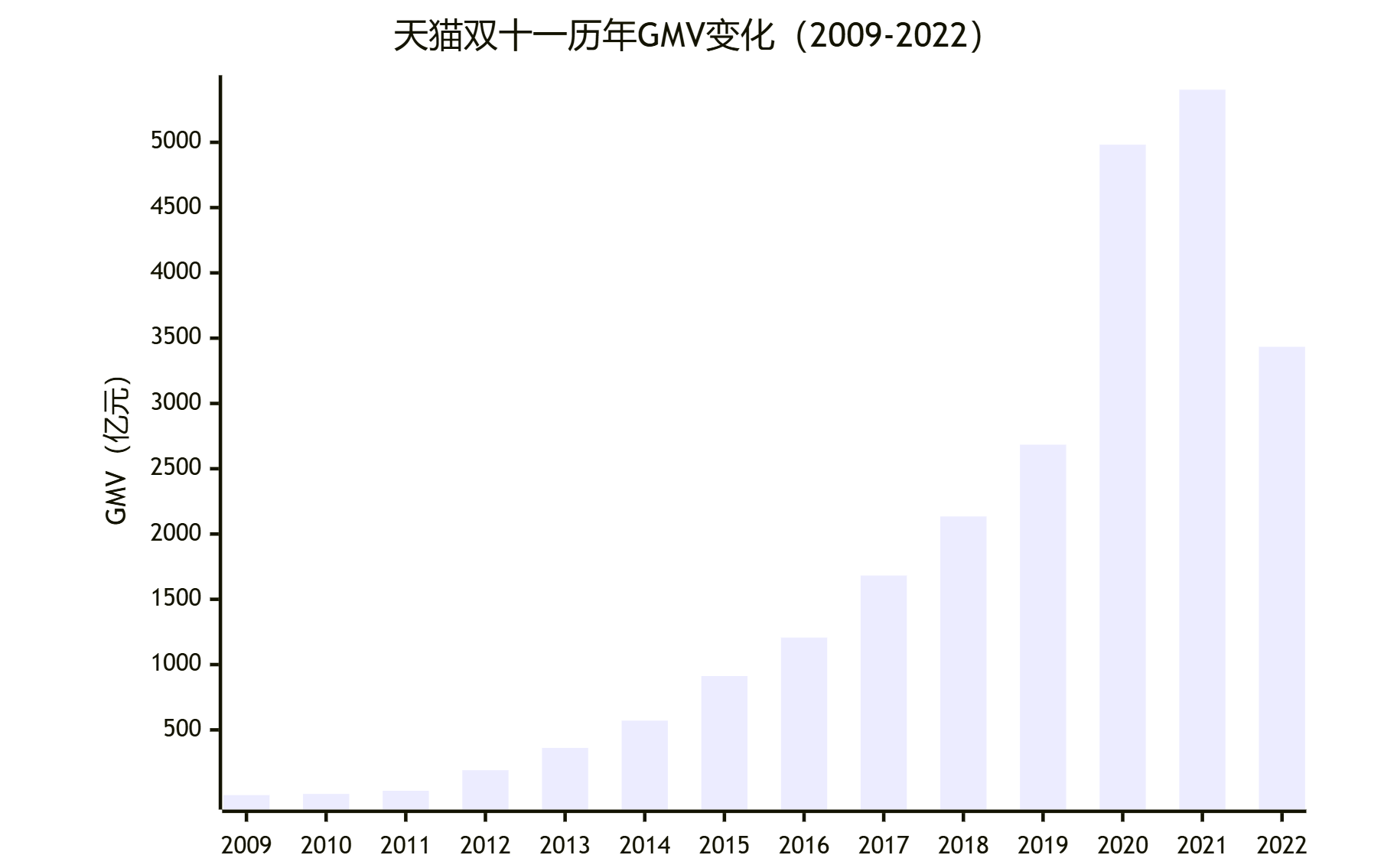
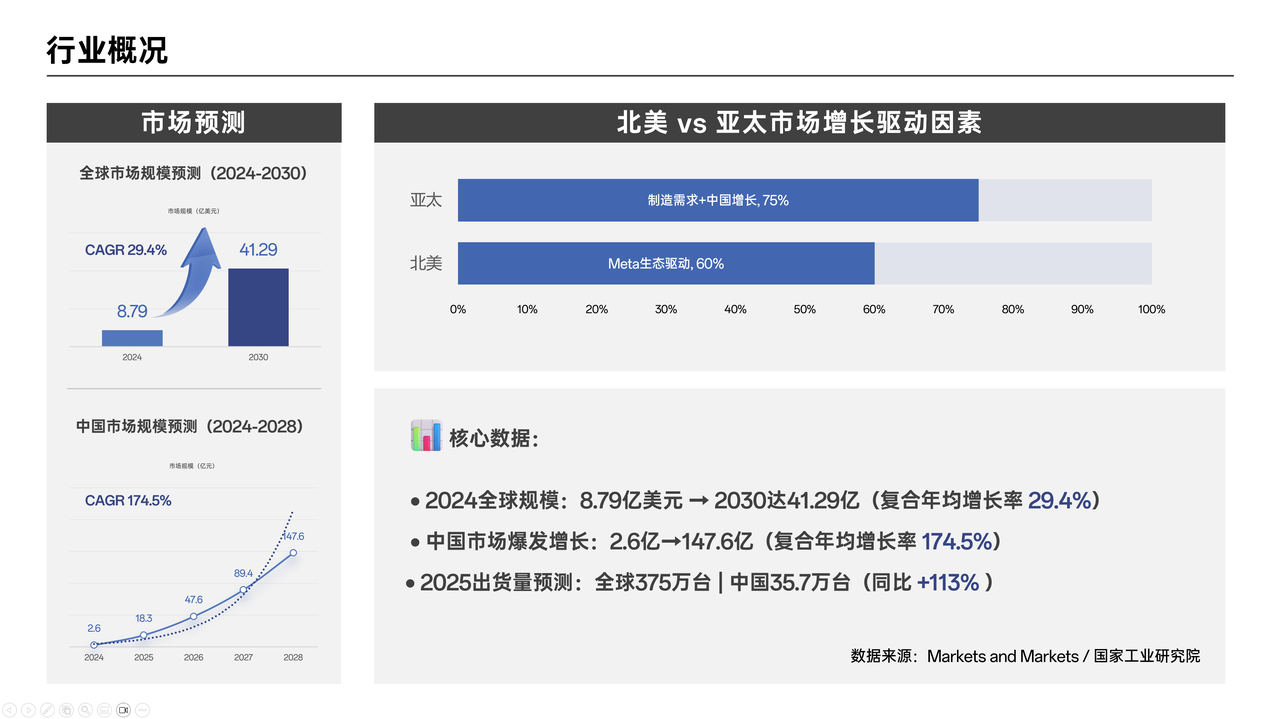
逐字稿:各位领导好,在这一页,我们来了解一下AI眼镜行业的概况。从市场规模预测的数据来看,AI眼镜行业前景十分广阔。2024年全球AI眼镜市场规模为8.79亿美元,这一数据来源于权威的Markets and Markets报告。而到2030年,全球市场规模预计将达到41.29亿美元,年复合增长率为29.4%。这意味着在未来几年,全球AI眼镜市场将持续快速增长。
从区域分布来看,北美和亚太地区是两个重要的增长区域。北美地区因为Meta等企业的推动,增长十分显著。Meta生态的驱动,为北美市场的发展注入了强大动力。而亚太地区则是由于制造业需求的增长带动了行业发展,尤其是中国市场发展迅速。
重点来看中国市场,预计2024年中国AI智能拍摄眼镜市场规模将达到2.6亿元,到2028年,这个数字将飙升至147.6亿元,年复合增长率高达174.5%。这充分显示了中国市场的巨大潜力。同时,预计2025年全球AI智能眼镜出货量将达到375万台,这里不包含AR眼镜。而中国市场出货量预计达35.7万台,同比增长约113% 。这表明中国市场不仅规模增长迅速,在出货量上也呈现出强劲的增长态势。
通过这些数据,我们可以清晰地看到AI眼镜行业,尤其是中国市场的巨大发展空间。投资1000万开发像rayban – meta一样的AI拍摄眼镜,有望在这个快速增长的市场中占据一席之地,收获丰厚的回报。
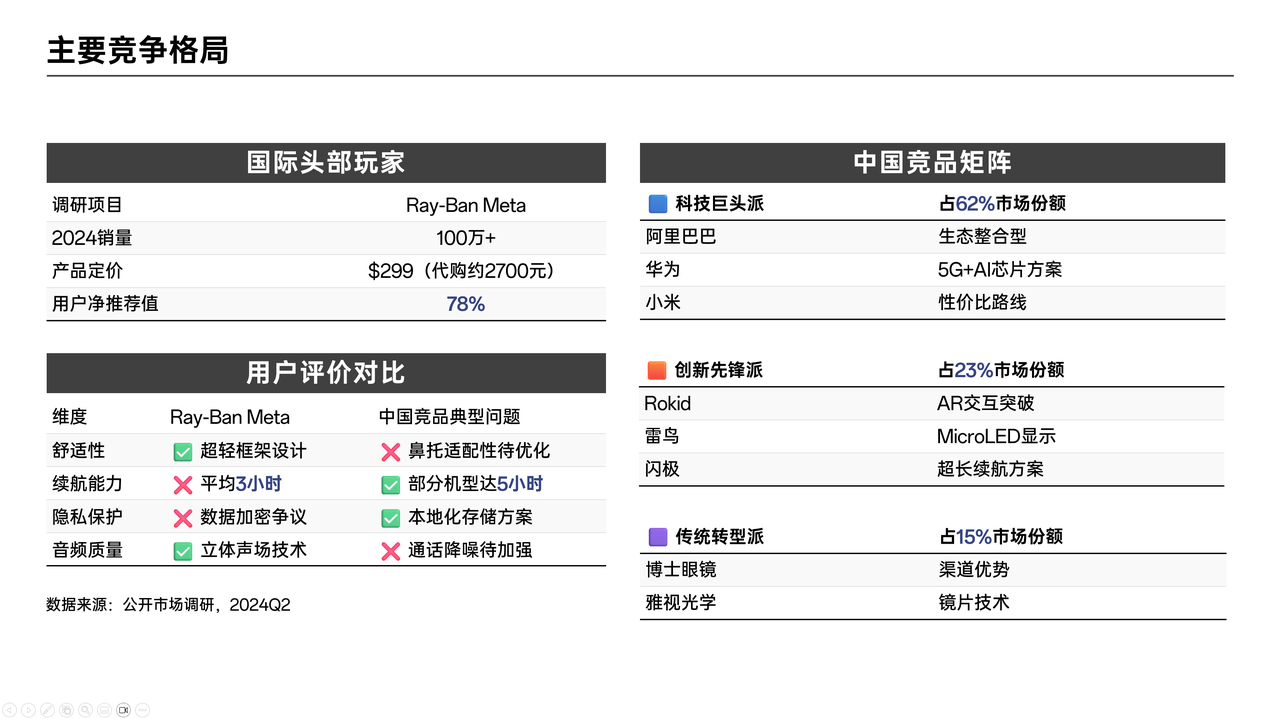
逐字稿:在这一页,我们来深入分析AI拍摄眼镜领域的主要竞争格局。主要从国际头部玩家Ray – Ban Meta,以及中国竞品矩阵两大方面展开。
先看国际标杆Ray – Ban Meta。2024年,其销量超100万台,定价299美元,这样的成绩使其成为行业内具有重要影响力的产品。从用户评价来看,它存在着优势与痛点。优势方面,超轻框架设计带来了舒适性的提升,立体声场技术让音频质量表现出色。然而,它也有一些不足,平均3小时的续航能力,难以满足用户长时间使用需求,并且数据加密方面的争议,让用户对隐私保护存在担忧。
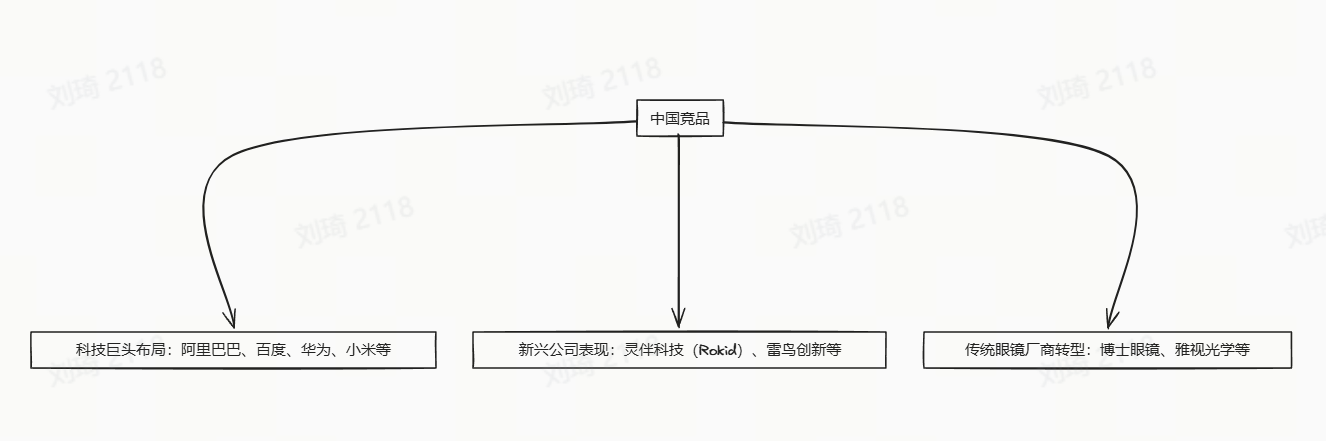
再把目光转向中国竞品矩阵。这里面涵盖了科技巨头、新兴公司和传统厂商三种类型。
科技巨头们纷纷布局AI眼镜领域,像阿里巴巴、华为、小米等。它们凭借在技术、品牌以及生态等多方面的强大优势,积极开展技术研发与产品布局,在市场竞争中占据有利地位。例如,阿里巴巴可进行生态整合,华为推出5G + AI芯片方案,小米走性价比路线,各自发挥自身特色。
新兴公司同样表现亮眼,像灵伴科技(Rokid)、雷鸟创新、闪极等。它们专注于研发创新,在细分领域推出特色功能产品。比如,Rokid实现了AR交互突破,雷鸟在MicroLED显示上有所建树,闪极提供超长续航方案,展现出强大的创新活力。
传统眼镜厂商也在积极转型,例如博士眼镜和雅视光学。它们借助自身在眼镜制造和销售渠道的优势,与科技企业合作推出AI眼镜产品。博士眼镜依靠渠道优势,雅视光学凭借镜片技术,试图在新的市场机遇中实现转型发展。
总体而言,国际头部玩家Ray – Ban Meta在市场上已取得一定成绩,但也存在一些有待改进的地方。而中国的竞品矩阵,各类型厂商凭借自身不同的优势,积极参与市场竞争,整个行业呈现出蓬勃发展的态势。 数据来源:公开市场调研,2024Q2。
逐字稿:这一页主要聚焦AI拍摄眼镜的用户画像与需求痛点。先来看目标群体。欧美地区的目标群体,集中在北美和欧洲都市,年龄在25到45岁之间,多为白领以及技术爱好者。这部分人群热衷于追求科技潮流,对新技术接受度极高,他们日常的工作和生活场景丰富多样,对智能设备的需求自然也比较高,他们就像是科技领域的先驱者,工作中高频的移动办公场景,让他们对智能设备的依赖程度不断增加,同时,他们注重设备所展现出的科技感,并且愿意为创新功能支付更高的价格。
再看中国市场。同样,25到45岁人群是重要的目标群体,涵盖了一线城市的职场人士、科技爱好者以及年轻创业者等。中国市场用户基数庞大,随着科技的不断普及以及消费的升级,对AI拍摄眼镜的需求正逐步增长。不过,中国消费者更注重产品的性价比,对本地化功能有较高的期待,渴望产品能整合本地生活服务、社交娱乐等特色功能,精明消费,追求高性价比是他们的消费标签,在社交娱乐驱动下,对本地化服务整合有着迫切的要求,而且相较于欧美地区,对价格的敏感度要高出23%。
接下来是核心需求。在全球范围内,有大约60%的用户都提到,电池续航是关键需求。对于经常在户外活动,或者处于移动办公状态的用户而言,长时间的续航能力极为重要,这能确保设备在一天的使用过程中,无需频繁充电。想象一下,如果在户外拍摄或者商务出差途中,设备电量频繁告急,那将带来极大的不便。
隐私保护方面,约40%的用户表达了担忧。随着智能设备收集的数据量日益增多,用户对于自身数据如何被使用、存储以及保护,关注度越来越高。特别是在当前数据隐私法规愈发严格的大环境下,像欧美地区有GDPR合规要求,而中国用户则更偏好数据本地存储,以此来保障自身数据的安全性。
最后是价格敏感。用户普遍对价格较为在意,都期望能在合理的价格范围内,获得高性能的产品。欧美市场消费者购买力相对较高,但依旧看重性价比;而中国市场竞争激烈,消费者对价格更为谨慎,价格因素在购买决策中占据重要地位。具体来看,欧美市场消费者能接受的价格区间在299 – 499美元,中国市场的黄金价位段则在1500 – 2500元人民币。并且,中国用户还希望产品在价格合理的基础上,能提供更多符合本土需求的功能与服务。综合这些用户画像与需求痛点来看,开发一款像Rayban – meta一样的AI拍摄眼镜,满足不同地区用户的差异化需求,具有极大的市场潜力,值得我们投入资源进行开发。
逐字稿:在全球范围内,社交媒体如TikTok上AI眼镜相关UGC,也就是用户生成内容的使用率约30%,而KOL,即关键意见领袖合作的ROI,也就是投资回报率可达1:5 ,这充分显示出社交媒体在AI眼镜推广方面的强大传播潜力。而在中国市场,社交媒体生态更为丰富多样,各平台也有着独特的用户群体和传播特点,为我们这款AI拍摄眼镜的推广提供了广阔空间。接下来,我们详细看看针对中国本土的社交传播与推广策略。
首先,深化社交媒体内容营销。微信生态中,我们可以利用公众号发布深度产品评测、使用教程、创意内容等,吸引用户关注并分享。比如撰写有趣、实用的AI拍摄眼镜创意教程,让用户能够通过我们的内容,更好地发掘产品的功能和乐趣。同时结合小程序开发互动游戏、产品定制等功能,增强用户参与度。例如开发一个AI眼镜创意拍摄互动游戏,让用户在游戏中体验产品的拍摄功能。另外,借助视频号发布高质量的产品展示视频,利用其社交推荐机制扩大曝光。
微博平台上,我们发起热门话题讨论,像#AI拍摄眼镜新体验#,吸引用户分享自己的使用感受和创意拍摄作品。与科技、时尚等领域大V合作,发布产品相关微博并进行抽奖互动,提高产品话题度和品牌知名度。例如与科技领域大V合作,让他们分享对产品的技术评测,同时开展转发抽奖活动,吸引更多用户关注。
抖音则鼓励用户创作与AI拍摄眼镜相关的创意短视频,发起挑战活动,如“AI眼镜创意拍摄挑战”,设置丰厚奖励,激发用户参与热情。与抖音上的头部KOL合作,制作具有话题性的视频内容,利用平台算法推荐,实现快速传播。比如和抖音头部KOL一起拍摄有趣、新颖的创意短视频,展示产品在不同场景下的使用效果。
其次,联合KOL进行场景化展示。科技类KOL方面,与科技评测类KOL合作,进行产品深度评测,展示AI拍摄眼镜在技术层面的优势,如摄像头性能、AI功能实现等。通过专业的解读和对比,增强消费者对产品技术实力的认可。比如让科技评测KOL拆解产品,详细讲解内部构造和技术原理,展示产品的技术优势。
时尚类KOL,结合时尚类KOL,将AI拍摄眼镜融入时尚穿搭场景,突出产品的时尚外观设计,吸引追求潮流的年轻消费者。展示其作为时尚配饰在不同场合的搭配效果,提升产品的时尚属性。比如让时尚类KOL展示在街拍、时装秀等场景下,AI拍摄眼镜与不同时尚穿搭的搭配,展现产品的时尚感。
生活方式类KOL,与生活方式类KOL合作,展示AI拍摄眼镜在日常生活场景中的应用,如旅行、运动、聚会等。通过真实的生活场景演绎,让消费者更直观地感受到产品为生活带来的便利和乐趣。例如生活方式类KOL在旅行过程中,使用AI拍摄眼镜记录美好瞬间,展示产品在旅行场景中的实用性。
再者,结合中国本土特色应用场景推广。本地生活服务方面,与美团、大众点评等本地生活服务平台合作,推出与线下商家的联合推广活动。例如,消费者在指定商家使用AI拍摄眼镜拍摄并分享消费体验,可获得商家优惠券或积分奖励,同时提升产品曝光度和用户粘性。
社交娱乐方面,结合中国流行的社交娱乐应用,如腾讯视频、爱奇艺等视频平台,开展内容合作。例如,赞助热门综艺节目或网剧,将AI拍摄眼镜巧妙植入剧情,展示其使用场景,吸引大量观众关注。
最后,构建品牌私域流量。通过社交媒体平台引导用户加入品牌官方社群,如微信社群、QQ群等。在社群内定期举办产品试用活动、用户交流分享会等,增强用户与品牌之间的互动和粘性。同时,收集用户反馈,及时优化产品和服务,形成良好的口碑传播。例如在社群内举办新品试用活动,邀请用户分享使用感受,根据用户反馈优化产品。
通过以上针对中国本土市场的社交传播与推广策略,借助国内丰富的社交媒体资源和独特的应用场景,我们有望快速提升AI拍摄眼镜的品牌知名度和市场占有率,为产品的成功推广奠定坚实基础。
逐字稿:接下来为大家介绍的是这款AI拍摄眼镜的技术组件与成本分析。
先来看关键组件成本结构,这款AI拍摄眼镜的关键组件包含摄像头、显示屏、扬声器、麦克风、电池、处理器、连接模块以及其他如外壳等部件。摄像头成本在10 – 20美元,它能满足拍摄等基础功能;显示屏因类型不同,成本在20 – 50美元;扬声器5 – 10美元,用于提供音频输出;麦克风2 – 5美元,负责声音采集;电池5 – 10美元,保障设备续航;处理器10 – 20美元,处理各项数据;连接模块5 – 10美元,实现设备连接功能;其他部件成本10 – 20美元。涵盖以上关键组件的总BOM成本在70 – 140美元。
再看AI开发成本,AI功能开发成本预计在5万 – 10万美元之间,具体会取决于功能复杂性,例如语音识别、图像处理等功能的开发难度,都是影响成本的因素。
在成本控制优势上,我们具备两大突出优势。一是规模效应,以100万台规模生产的话,单机成本约180美元,这其中包括了制造开销。而且随着生产规模进一步扩大,成本还有望持续降低。二是供应链整合,通过整合供应链,部分组件在国内已有成熟供应商,这使得我们在成本控制上占据了一定优势。
最后谈谈投资与成本关联,本次计划投入1000万资金,部分资金将用于技术开发与专利分析,以此来优化技术组件。在保证产品质量的前提下,有效控制成本,从而提升产品的性价比与市场竞争力,为产品在市场上的成功奠定坚实基础。
作为演示示例,前面信息筛选部分我做的其实不够充分,AI的Reaserch部分没有校对,图片只是从百度搜索结果随便截了几张。写到这一页我已经发现AI关于AI拍摄眼镜产品的认知有些不太对的地方了hhh,所以这个PPT我就不继续做下去了。(这也是现在Manus这类agent产品做研报的一个比较大的问题,容易被不可靠信源污染。)
但这套workflow下来让我满意的是,如此出来的成品PPT,内容的信息量远非一句话或一份简单文档生成的PPT可比的。
下面链接中,我放了两个直接使用网站的AI PPT产品,输入主体和文档资料生成的PPT作为对照组。可对比查看。
https://ilovezhiwai.feishu.cn/docx/FCledPAmGoLy8uxIpygcLcIMnqg
还有两个小工具:
1.图表转换工具箱
图表工具箱中的两个工具都是github上的开源项目,如果觉得好用可以去给它们点点Star:
https://github.com/markdown-it/markdown-it
https://github.com/excalidraw/mermaid-to-excalidraw
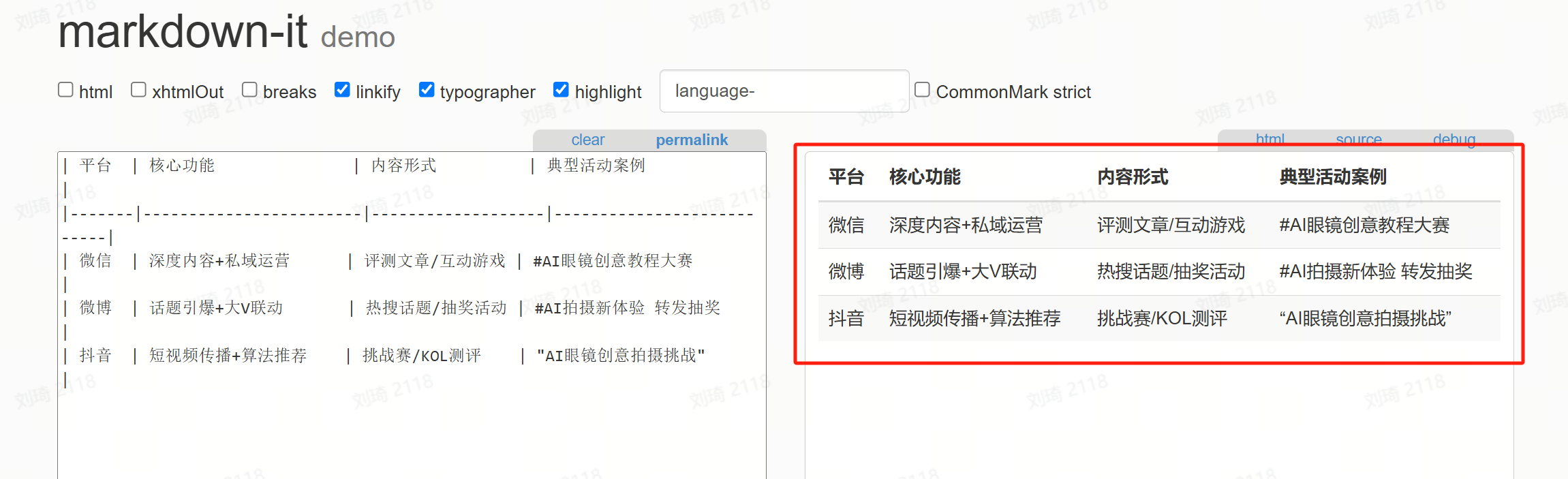
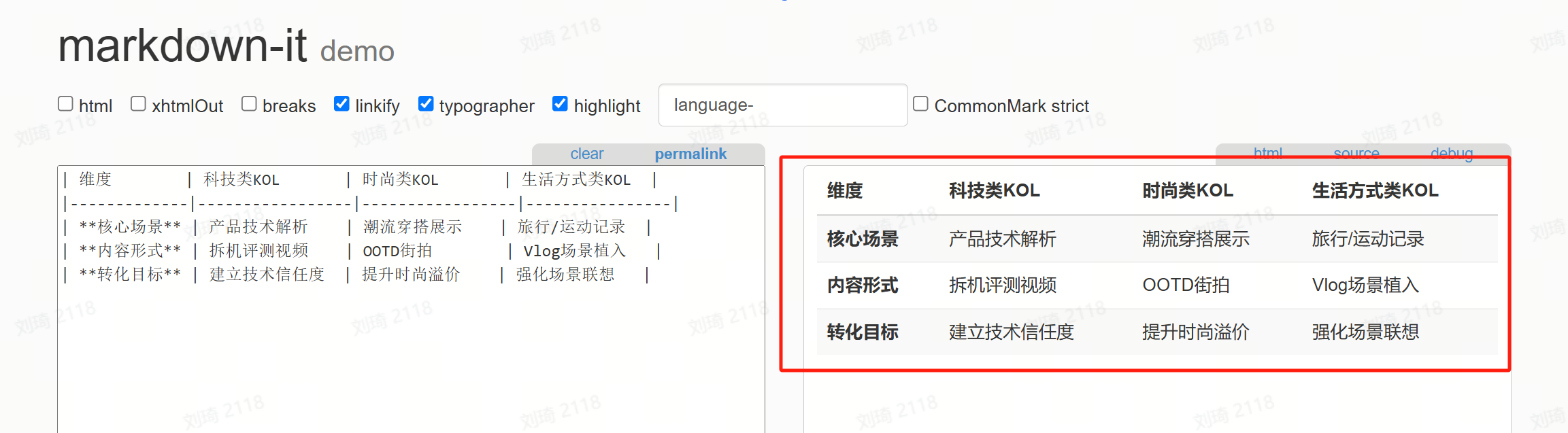
一个是Markdown转换工具,上面几页PPT的表格部分,其实都是用这个工具快速转换生成的。
例如说,这两个AI输出时整理好的Markdown表格:

只需要把它复制:
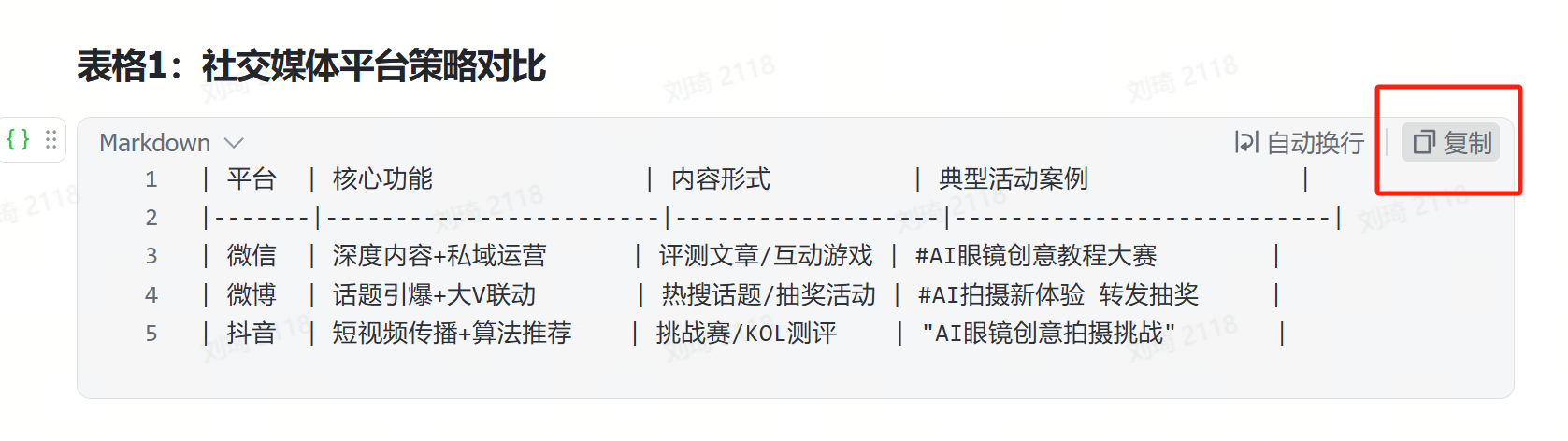
然后粘贴到工具内,就能够立刻输出表格。复制表格到PPT,就能够直接使用了。
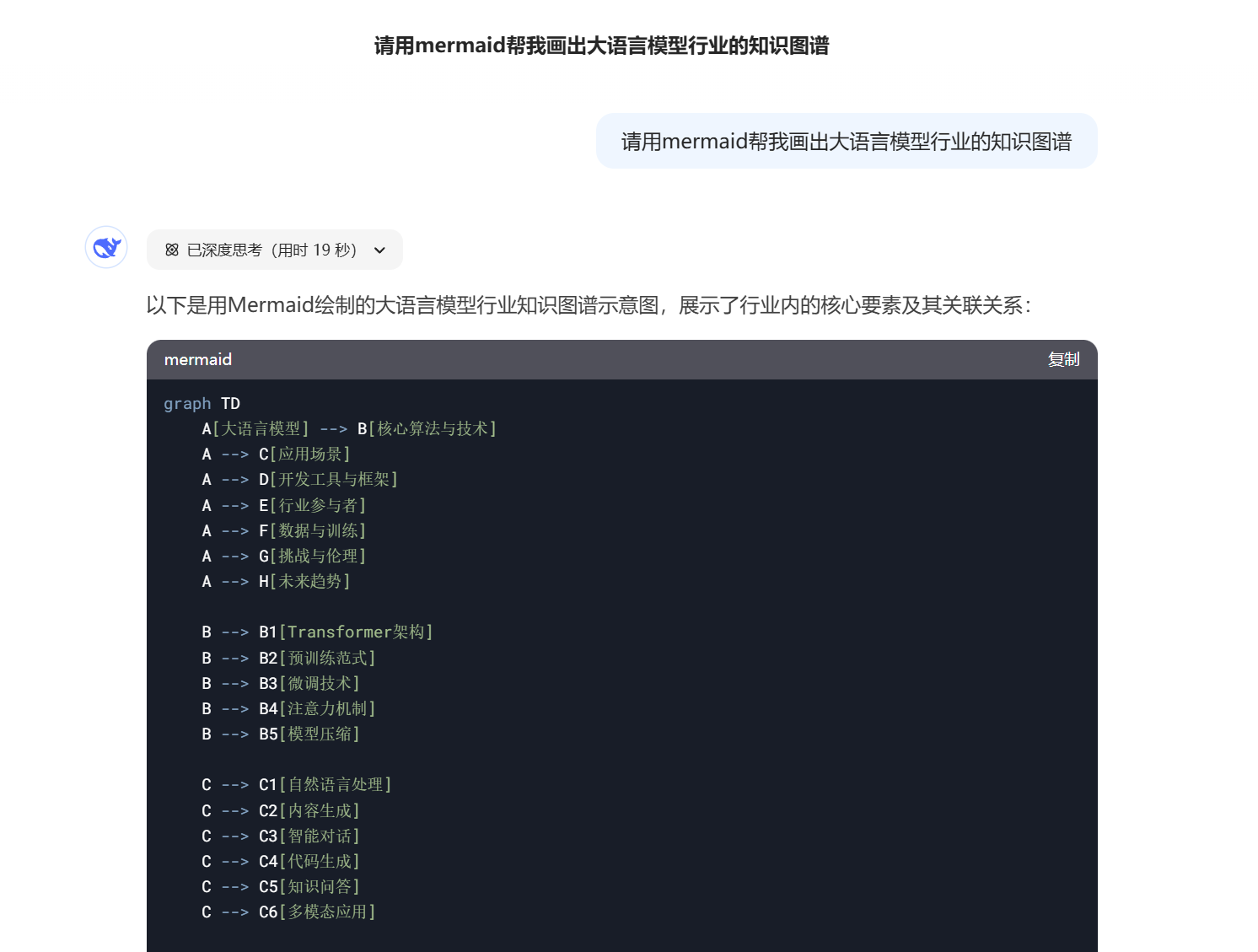
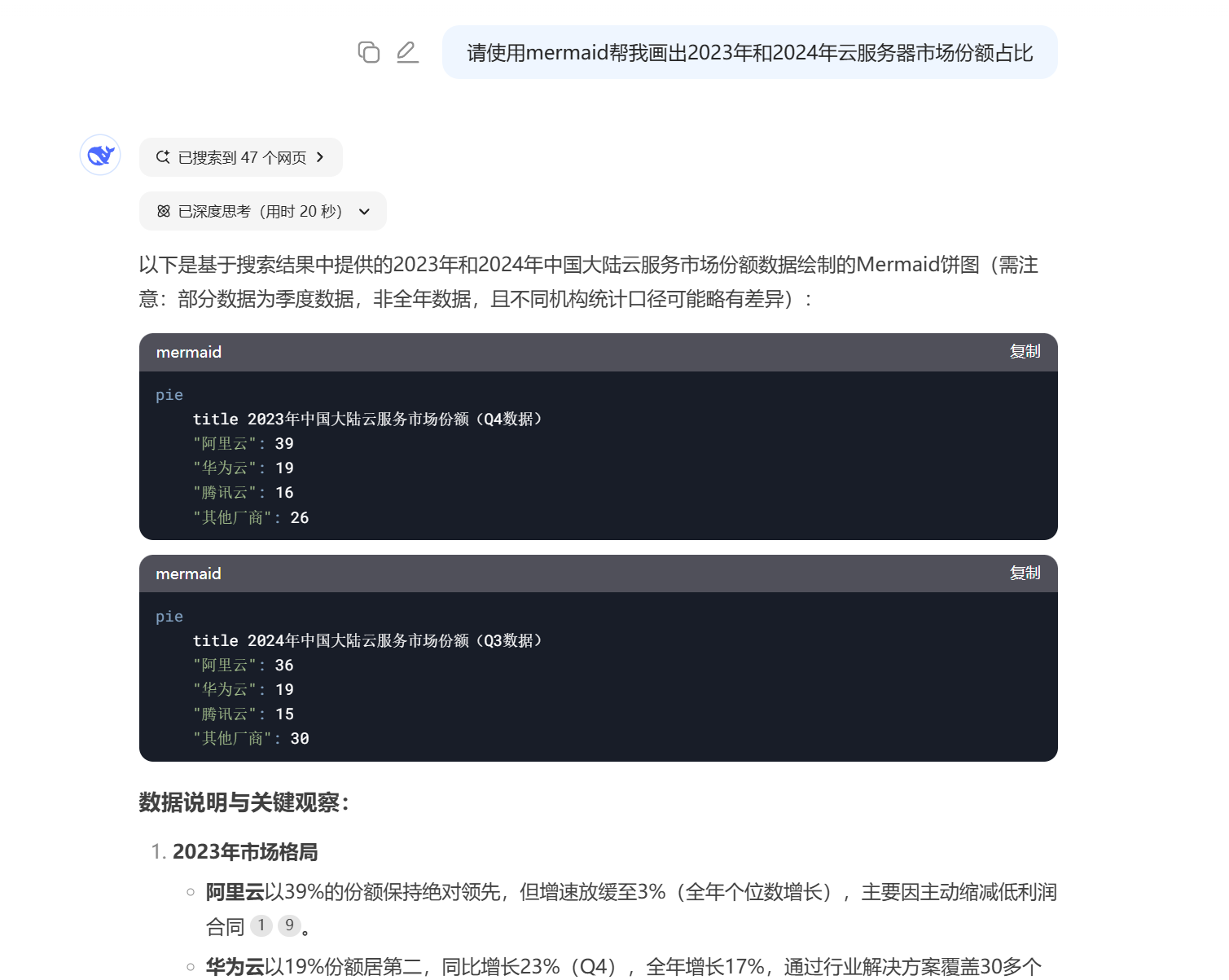
另一个是Mermaid工具,可以快速转换流程图、坐标图和饼图。
Mermaid的兼容不是特别好,所以我只是附加了Mermaid图表的建议,而没有做进流程中。
2.AI生成生图提示词
这个其实是之前做的另一个模板了:
https://ilovezhiwai.feishu.cn/wiki/Bv1ZwJ5tcimQkYkU4OPcUczNnQG?table=ldxmb17UU0j3gXoV
这个模板支持生文、生图、生视频。
如果你观察得够仔细,应该能发现刚才发的几张PPT里面用了一些「照片」:


这些照片过往都需要上网搜寻,但这几张并不是,它们来自AI生图。
而且可以通过提示词约束他们的行为动作,甚至穿戴,AI生图真的比找图快多了。





以上。
虽然自动化程度不够高,比较散装,跟成型的产品没法比。
但个人觉得它还是能帮我解决一些我自己的实际问题的。
我希望在PPT这件事儿上,AI能够更多辅助我的思考和逻辑梳理,而不是帮我简单列个大纲再套个马马虎虎的模板。如果你也跟我是一样的需求,希望你能够喜欢我这个模板。
也希望将来能有更好用的开箱即用的AI PPT产品。