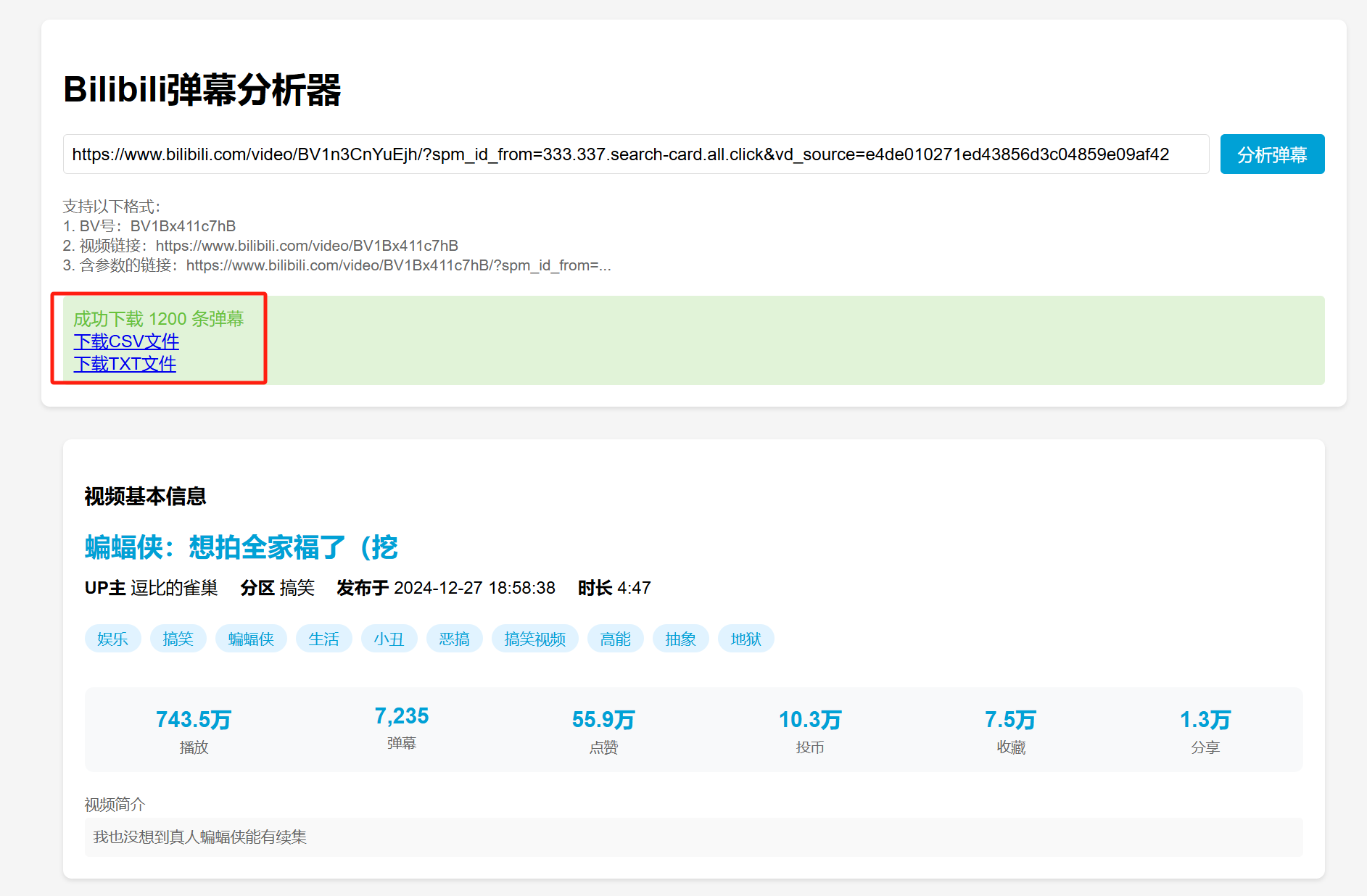
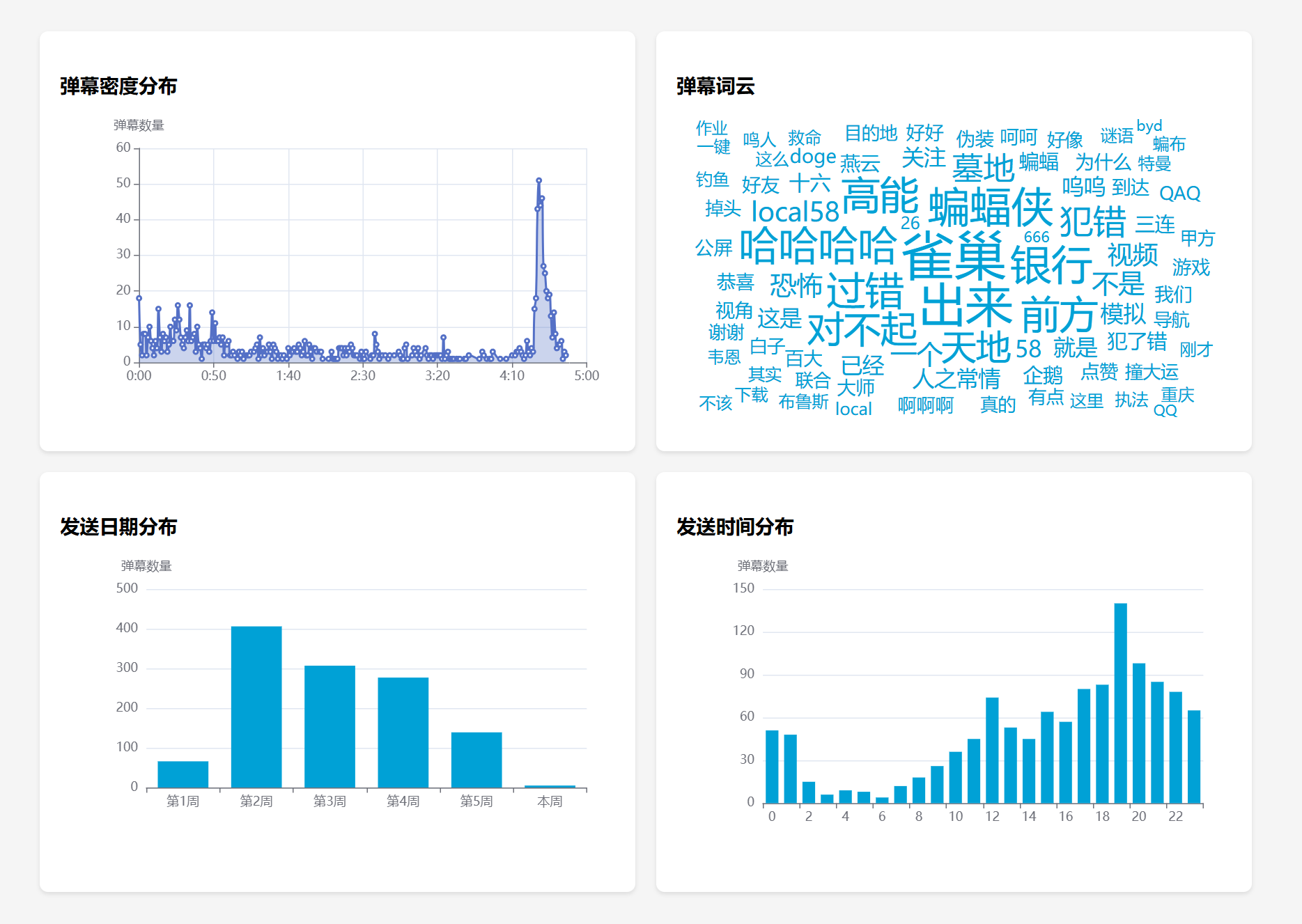
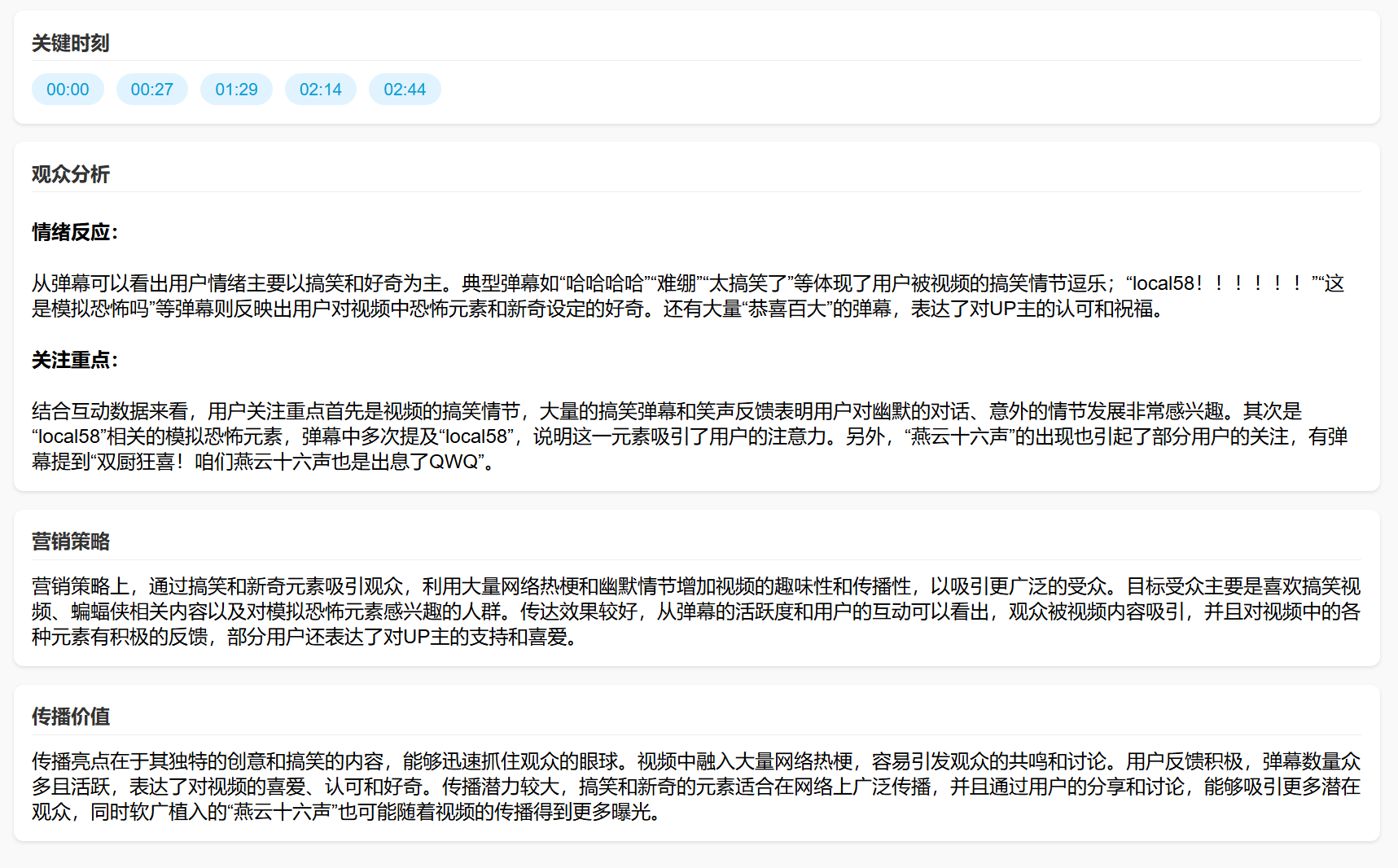
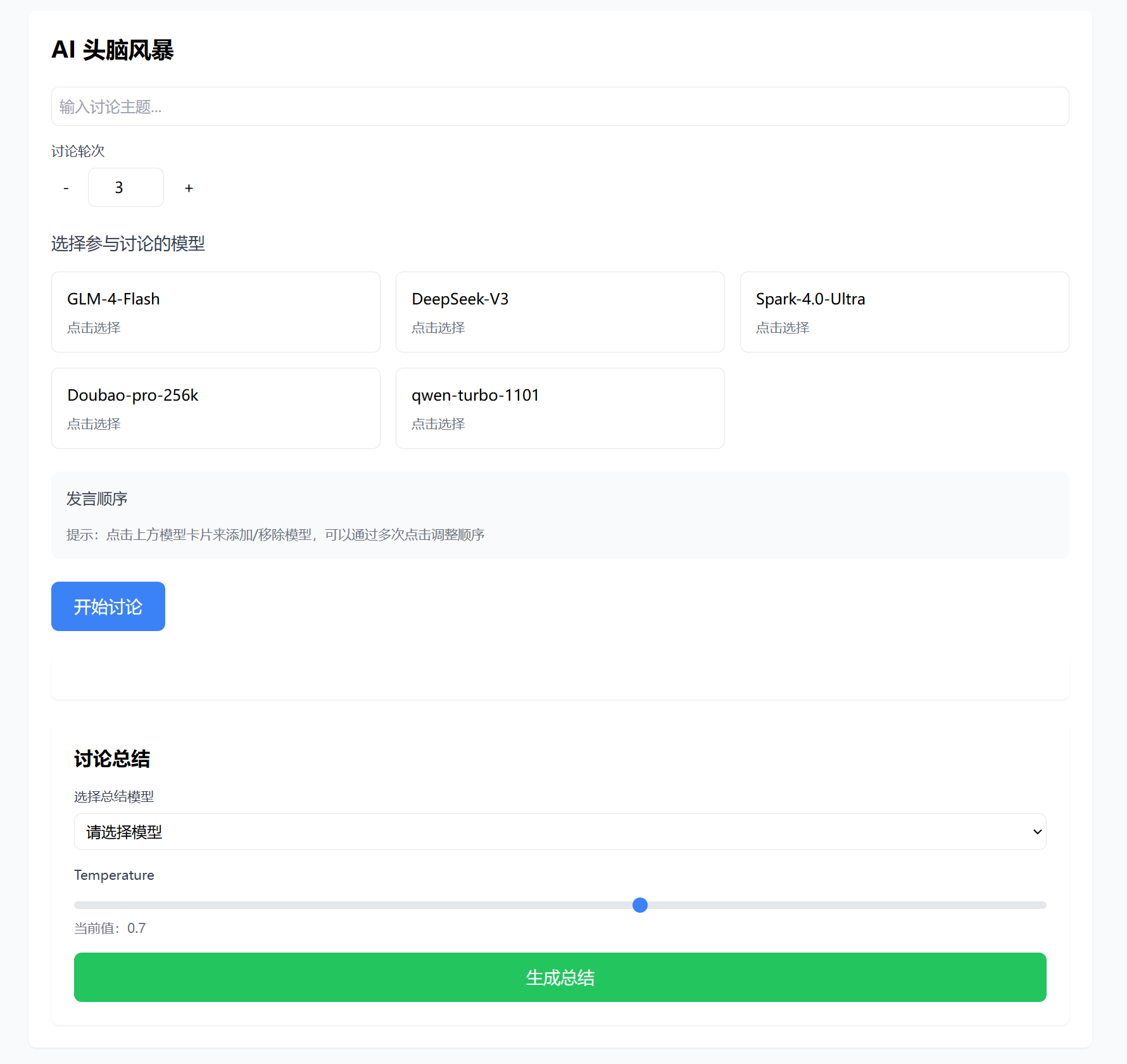
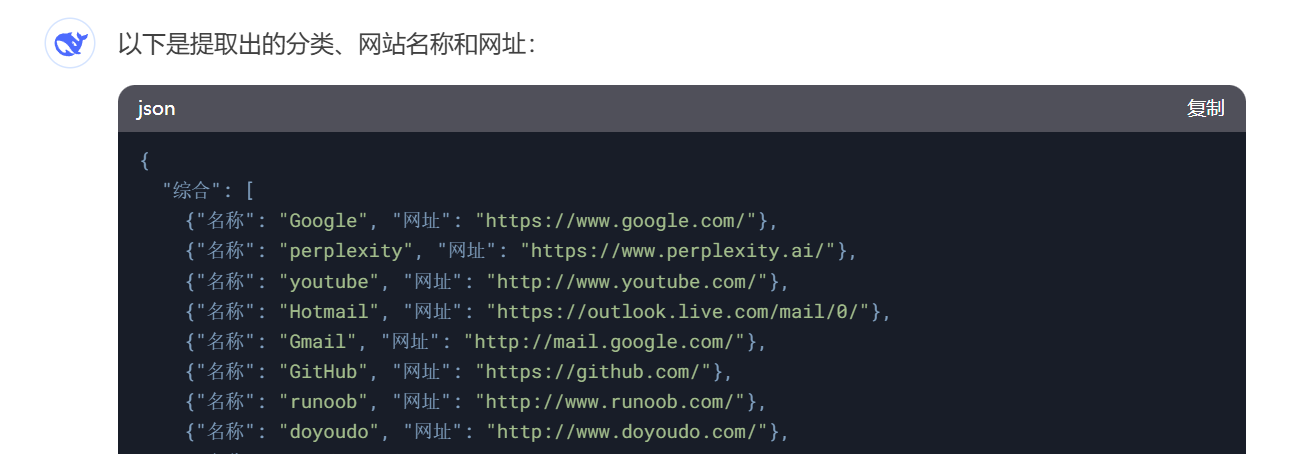
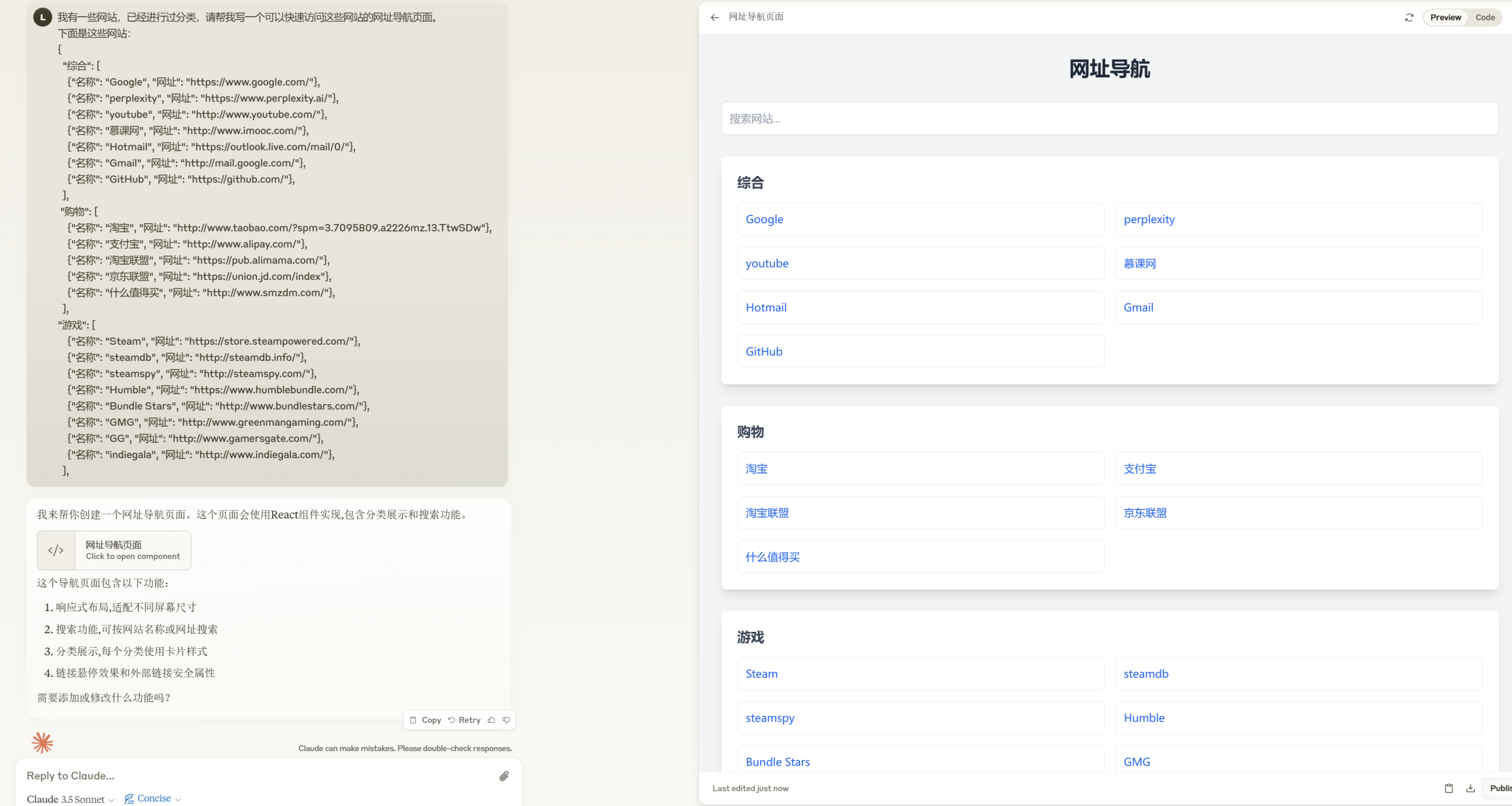
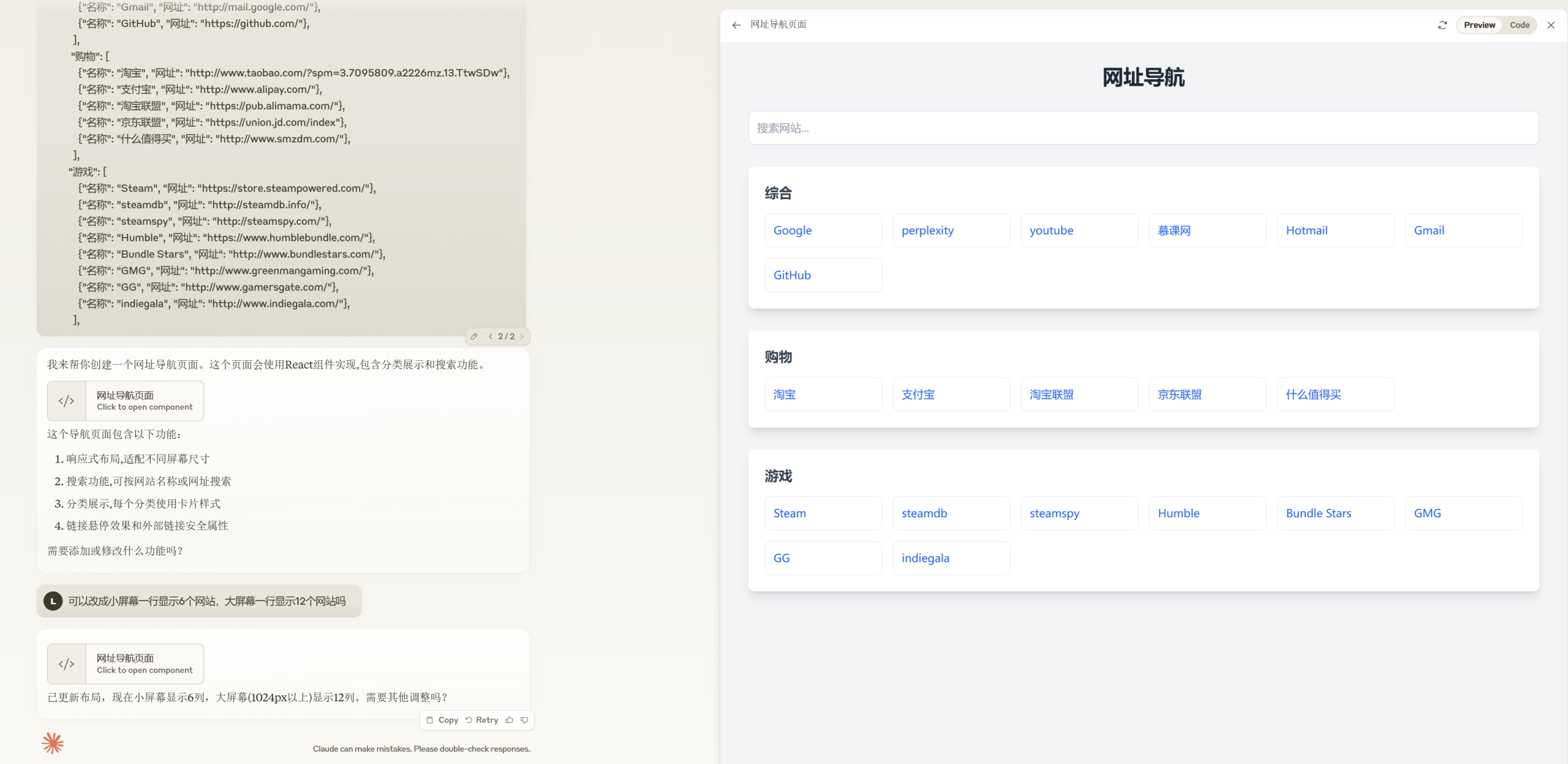
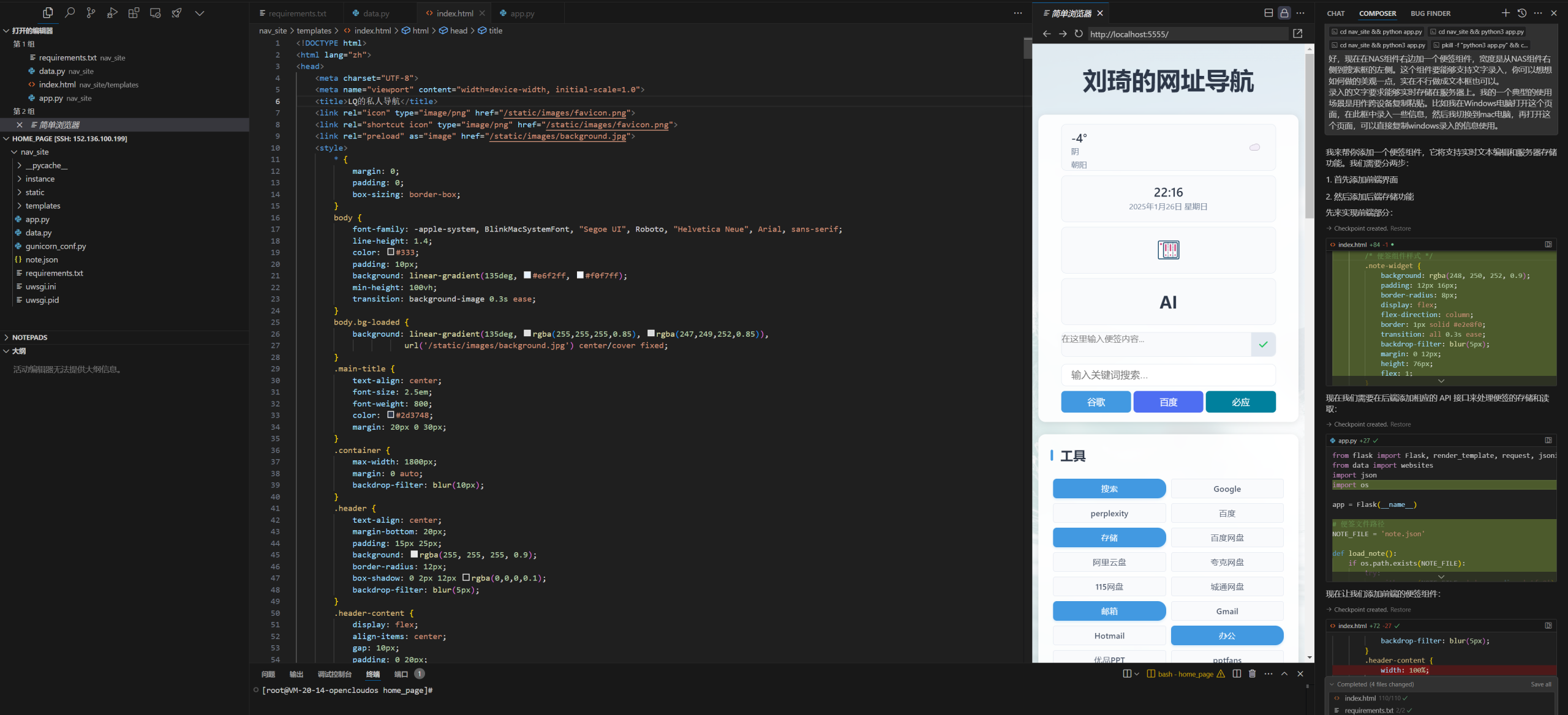
今天我们需要用到的工具是Chatbox,它可以接入各路AI的API(包括本地的Ollama),实现跟不同AI大模型的聊天。
https://chatboxai.app/zh
不仅支持Win、MacOS、Linux三大主流桌面操作系统,也支持手机端的iOS和Android。下载对应的版本安装,然后在设置里配置好API,就可以开始聊天了。或者,也可直接使用网页版。
软件自带Markdown、LaTeX、Mermaid等多种排版、公式、图表渲染,还支持Artifacts渲染,十分方便。

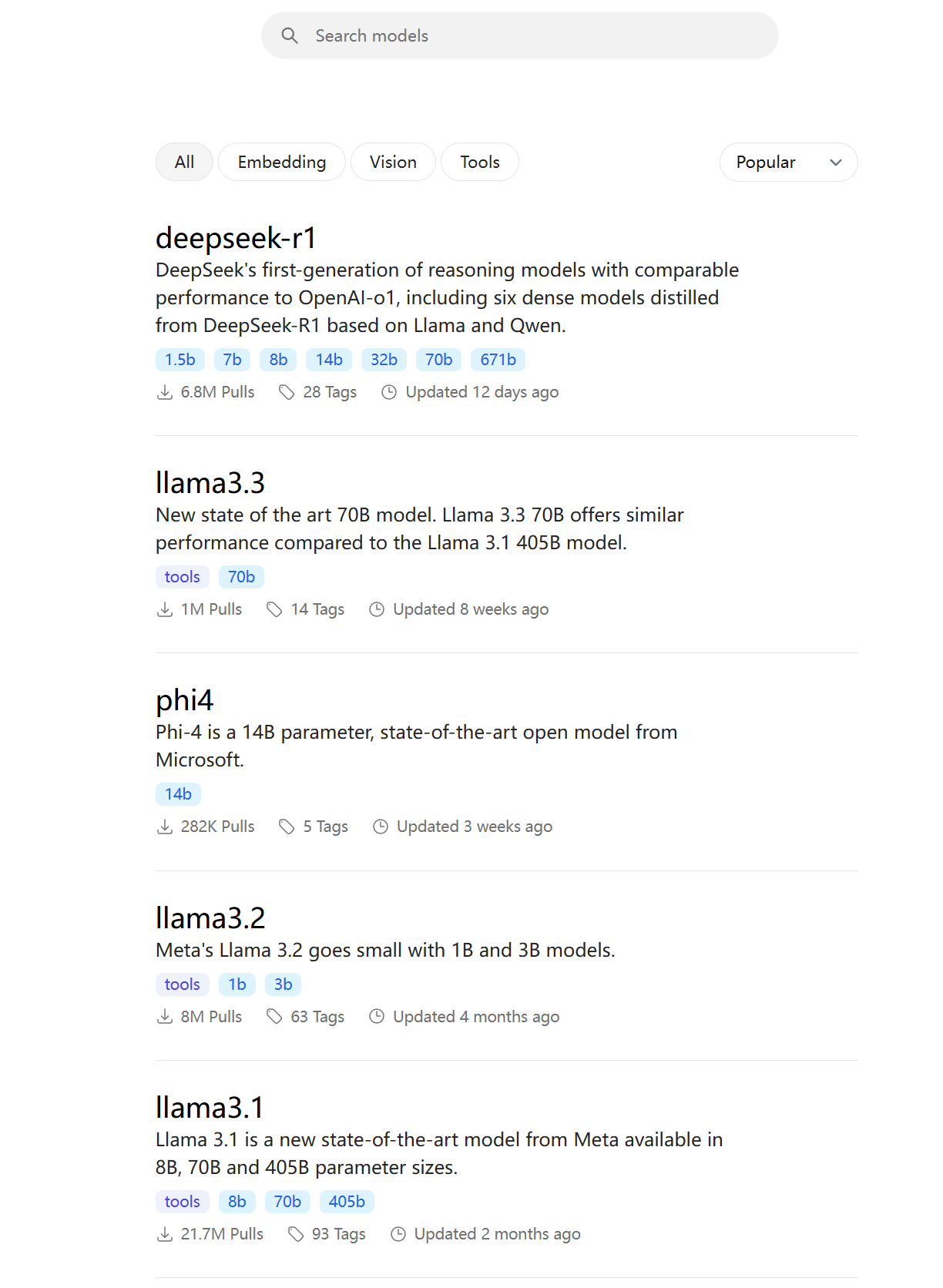
作为开源模型,到今天,基本上各个大模型云服务平台都已经支持DeepSeek-V3和DeepSeek-R1的API调用,在这我重点推荐三家。
一、硅基流动SiliconFlow
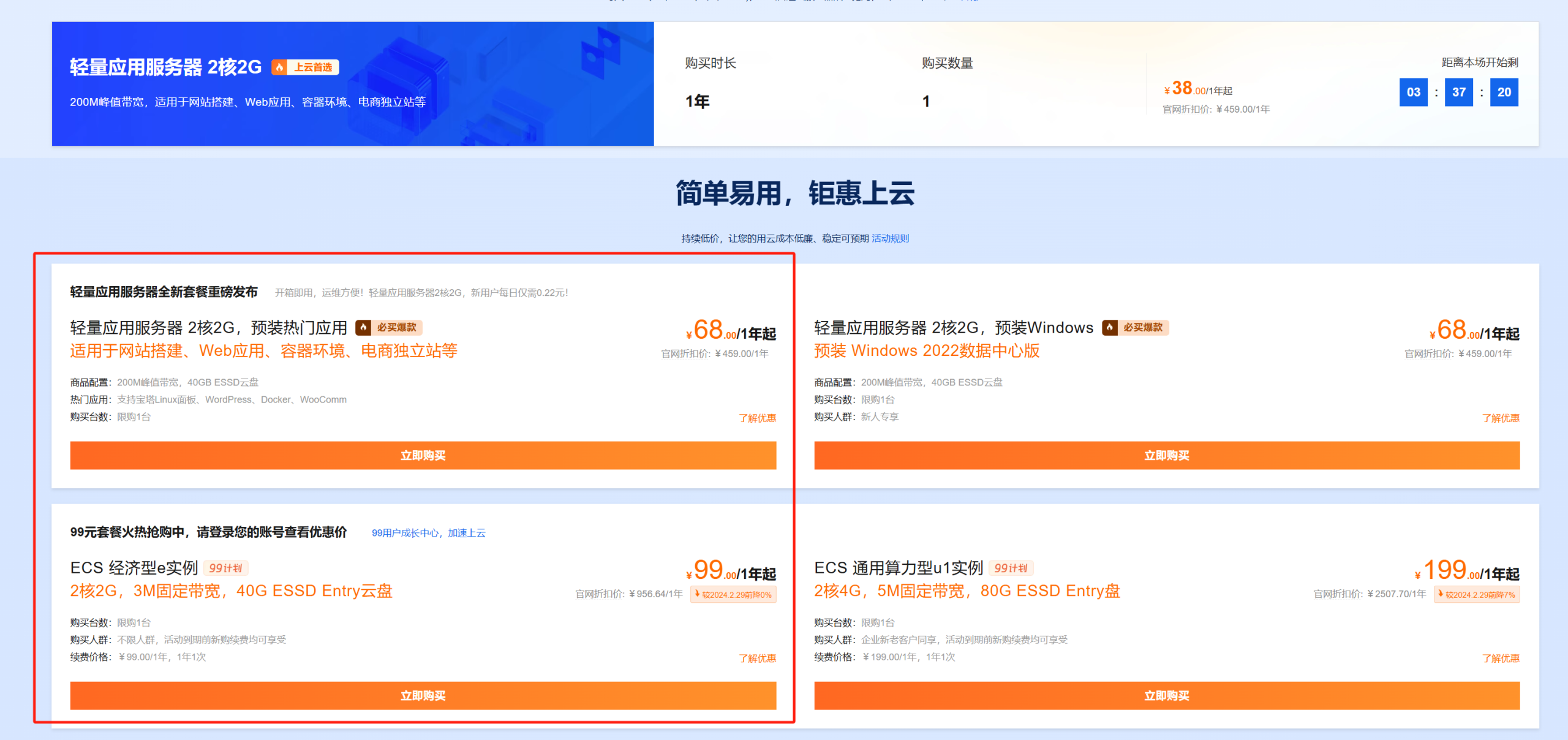
硅基流动应该是最早上线第三方DeepSeek API服务的,他们跟华为云合作,基于昇腾云服务部署了完整版本的DeepSeek-V3和DeepSeek-R1模型。

他们的邀请注册活动现在已经恢复,通过邀请链接注册,邀请人和被邀请人可以同时获得等价14元平台配额的2000万tokens。换算成DeepSeek-R1的API大概应该有200万左右的额度。
你可以通过我的邀请链接注册:
https://cloud.siliconflow.cn/i/My0p5Jgs
然后再去邀请下家人朋友,薅到的免费额度也够用一阵子了。

不过注意,尽量避免到群里去四处乱发邀请链接打扰别人。一方面其实对大多数人来说,14元已经可以用好久了;另一方面活动奖励的金额是赠送余额,官方可以随时把特定模型的API修改成仅限充值余额使用,所以囤积大量赠额的意义也不大。
注册完成后,来到左侧菜单找到API密钥,新建API密钥。
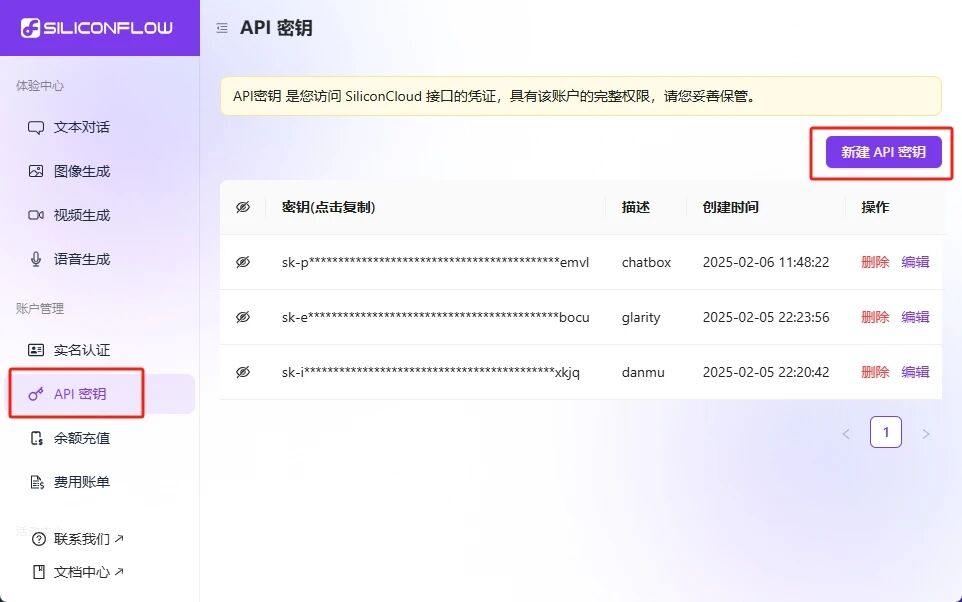
鼠标点击在相应密钥上,可以自动复制密钥。

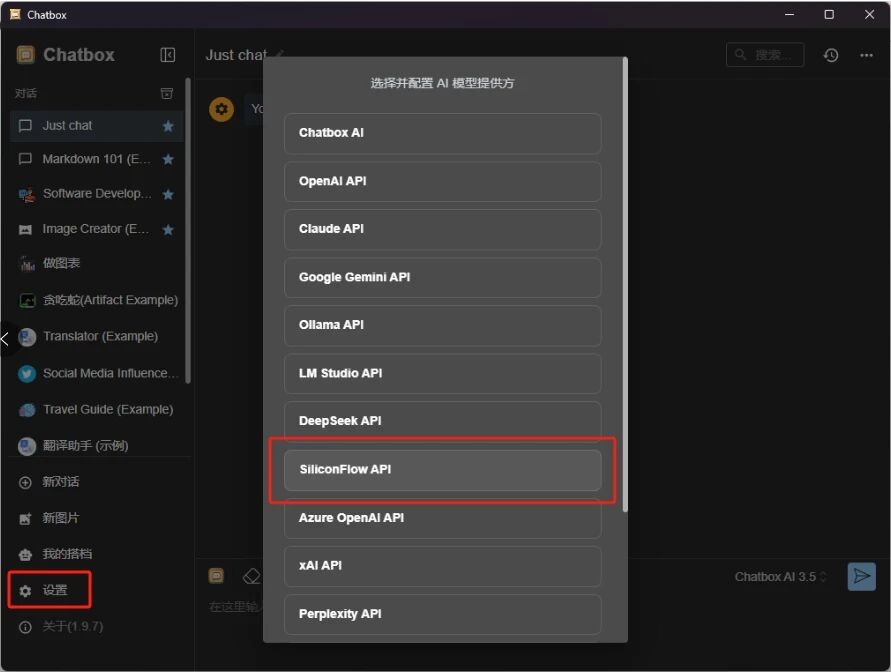
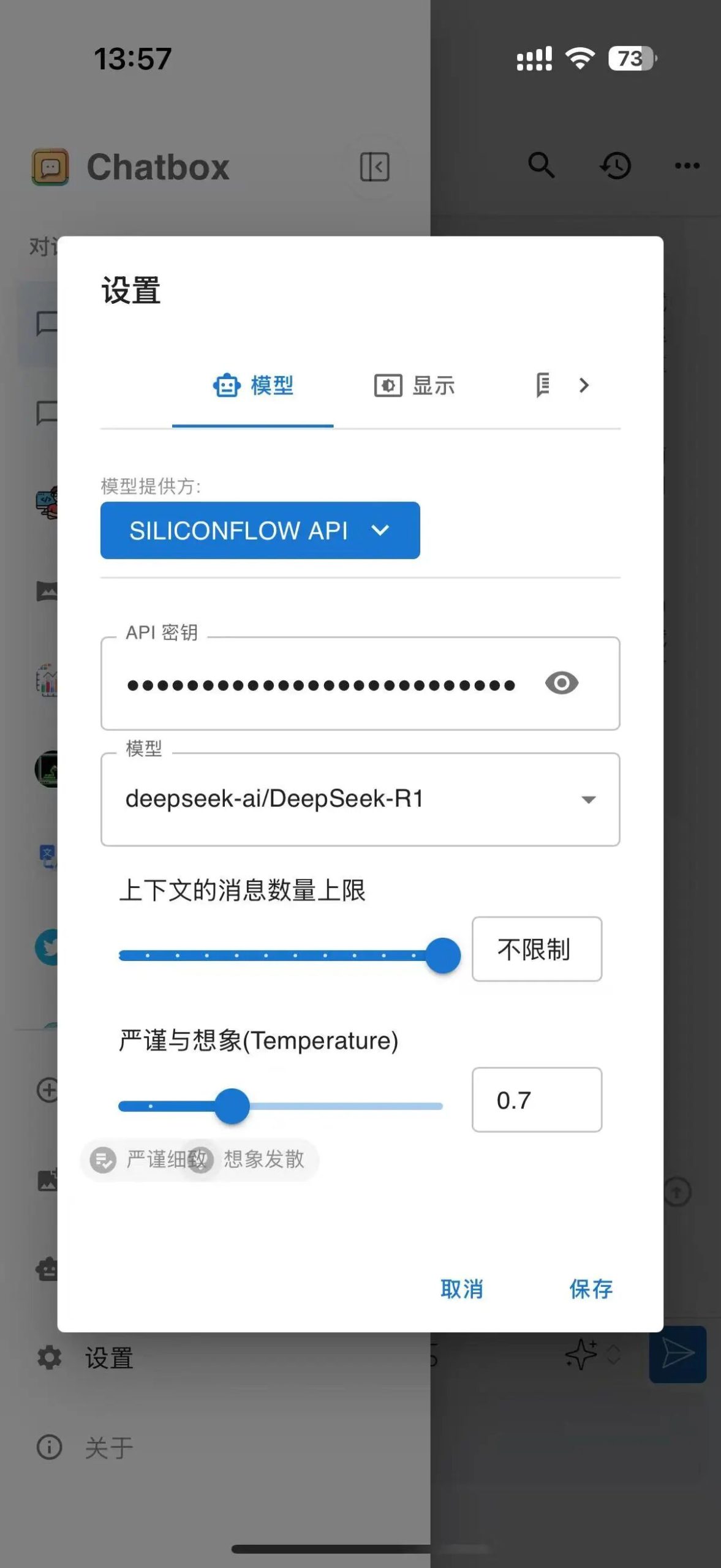
接下来回到Chatbox,点击设置,模型提供方选择SILICONFLOW API。
然后粘贴刚才复制的密钥在密钥填写位置,模型选择deepseek-ai/DeepSeek-R1,或者简单的推理需求也可选择deepseek-ai/DeepSeek-R1-Distill-Llama-70B。
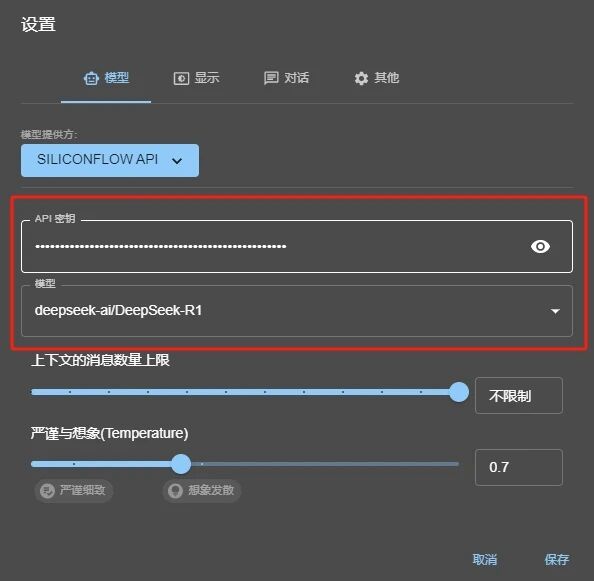
保存后即可直接进行对话使用了。
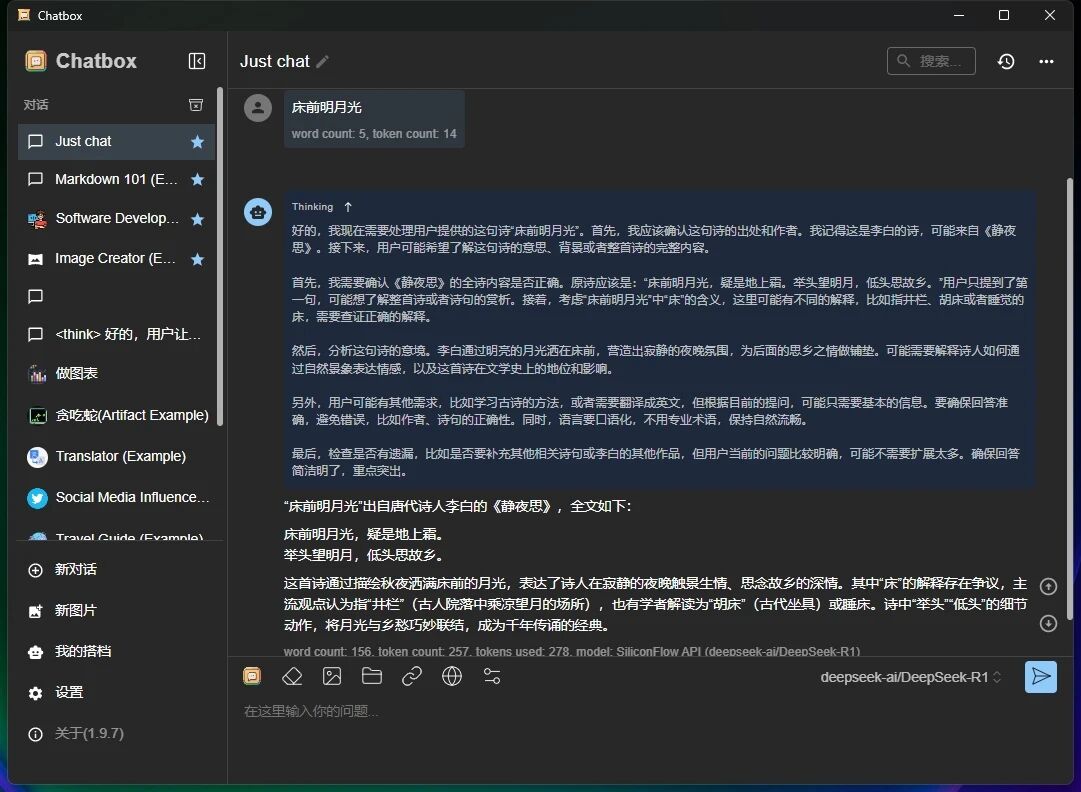
硅基流动还提许多其他大模型的API服务,点击对话框右下角发送键左侧的选单即可以直接切换别的大模型开聊,计费规则网站有说明。
如果你想好好对比下不同的大模型效果,用硅基流动算是用着了。
二、阿里云百炼
阿里云百炼是阿里云的大模型云服务平台,新注册用户和新接入的模型都能获得一些限时免费使用的tokens。
比如这次DeepSeek的API,实测百炼老用户也可以拿到有效期半年的1000万tokens。
还是先注册(或登录),
https://bailian.console.aliyun.com/#/model-market
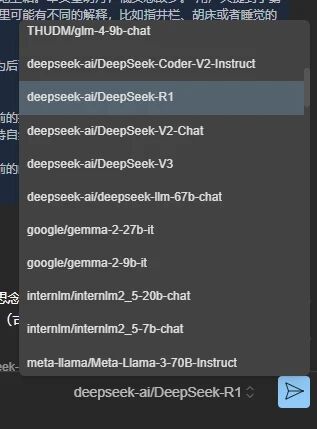
登录后再次打开模型广场。
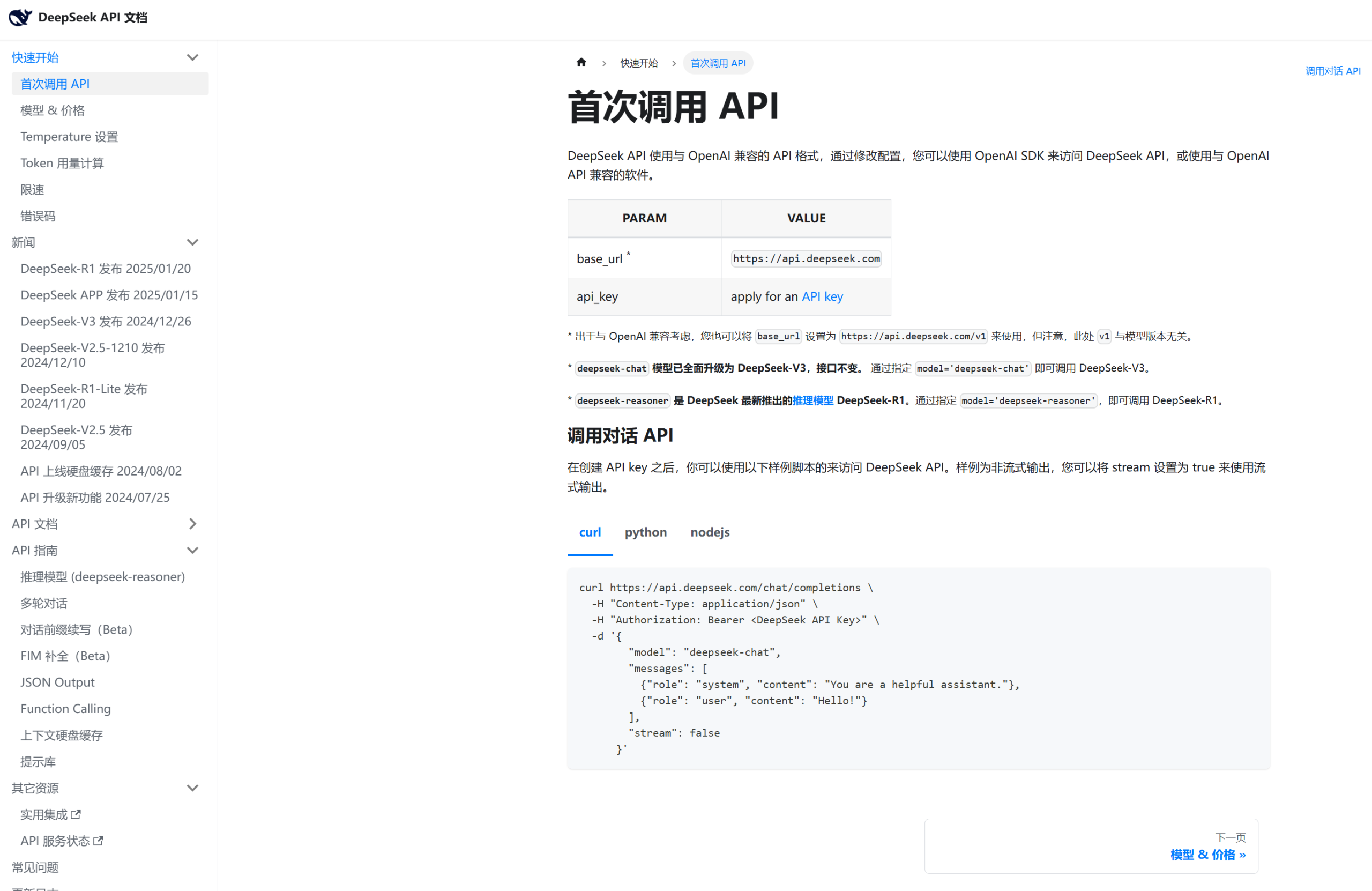
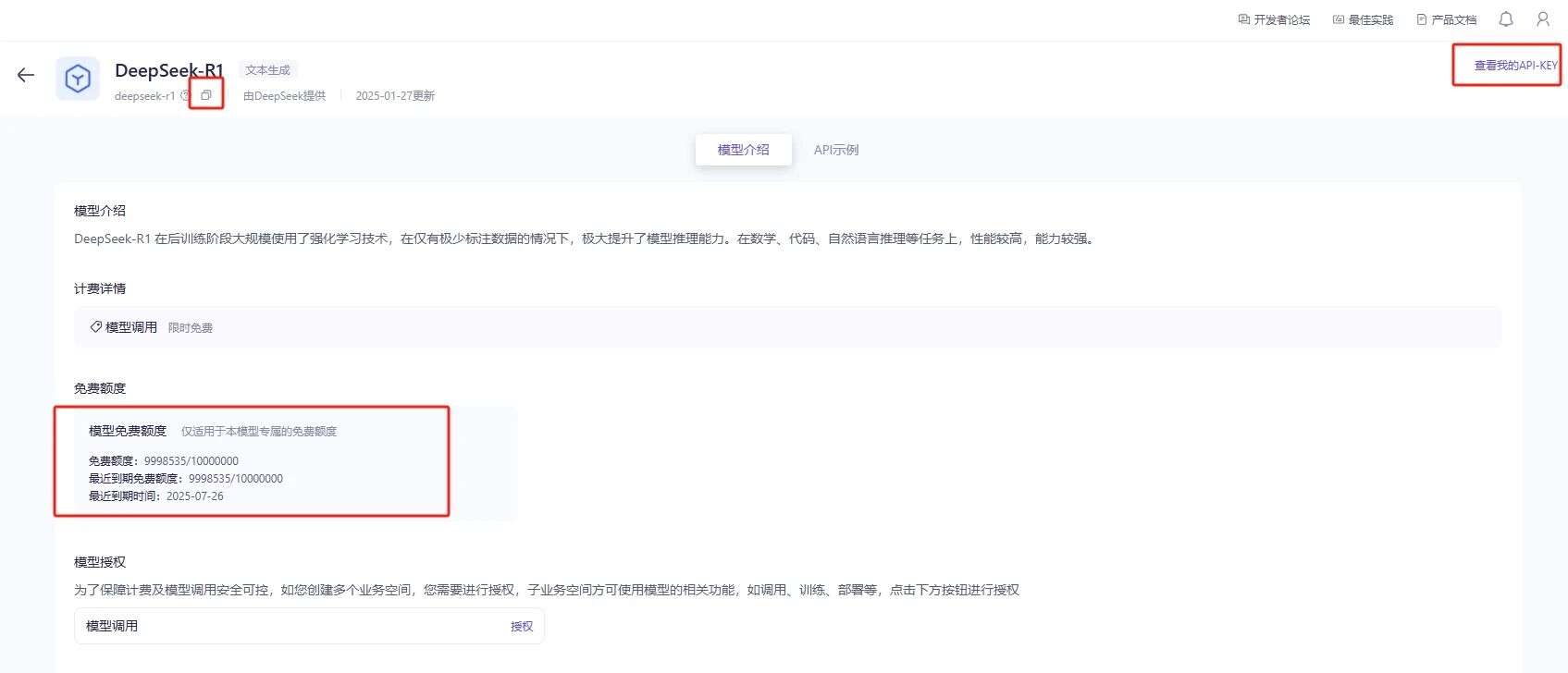
在列表中找到DeepSeek-R1,点击查看详情。
详情界面会显示tokens余量,
点击右上角查看我的API-KEY处,创建一个API-KEY。
然后点击左上角复制按钮,复制模型名称。
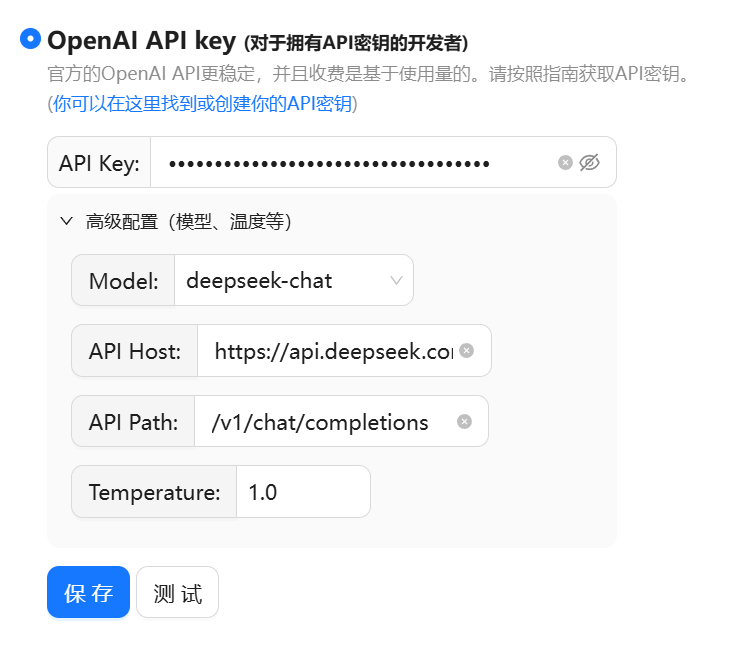
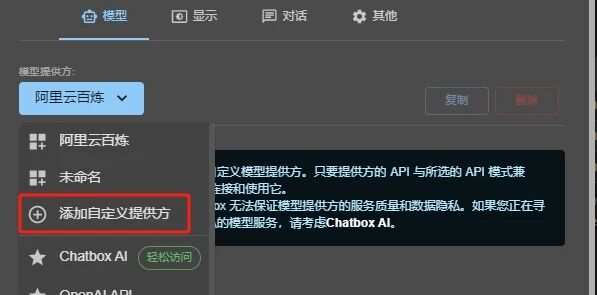
然后回到Chatbox,打开设置。
模型提供方选择添加自定义提供方。
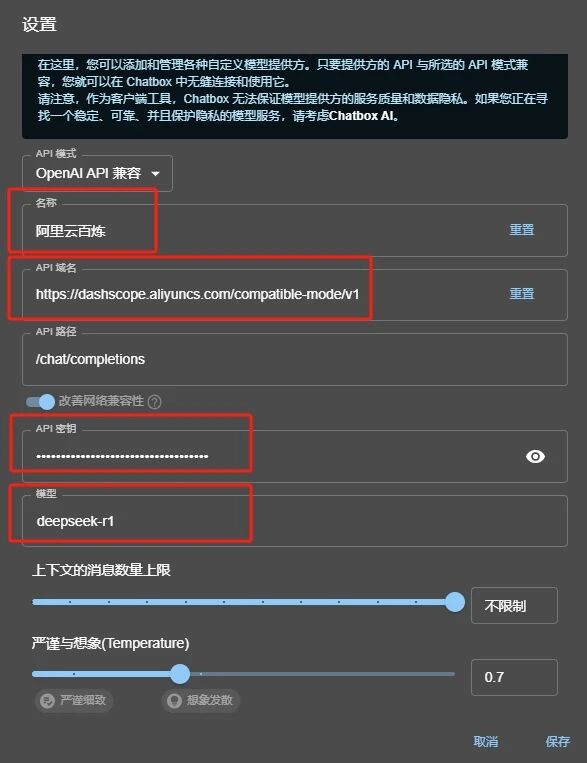
名称填写:阿里云百炼(或者你想填的);
API域名填写:
https://dashscope.aliyuncs.com/compatible-mode/v1;
API密钥:粘贴刚才创建的密钥;
模型:粘贴刚才点击复制按钮复制的deepseek-r1。
保存后即可直接进行对话使用。

三、火山方舟
火山方舟是字节旗下大模型云服务平台。前两天也支持了DeepSeek的API调用,但是作为直接付费调用模型,价格跟前面硅基流动相同。今天突然发现DeepSeek模型也支持豆包的50万tokens免费推理额度了,故添加进来。
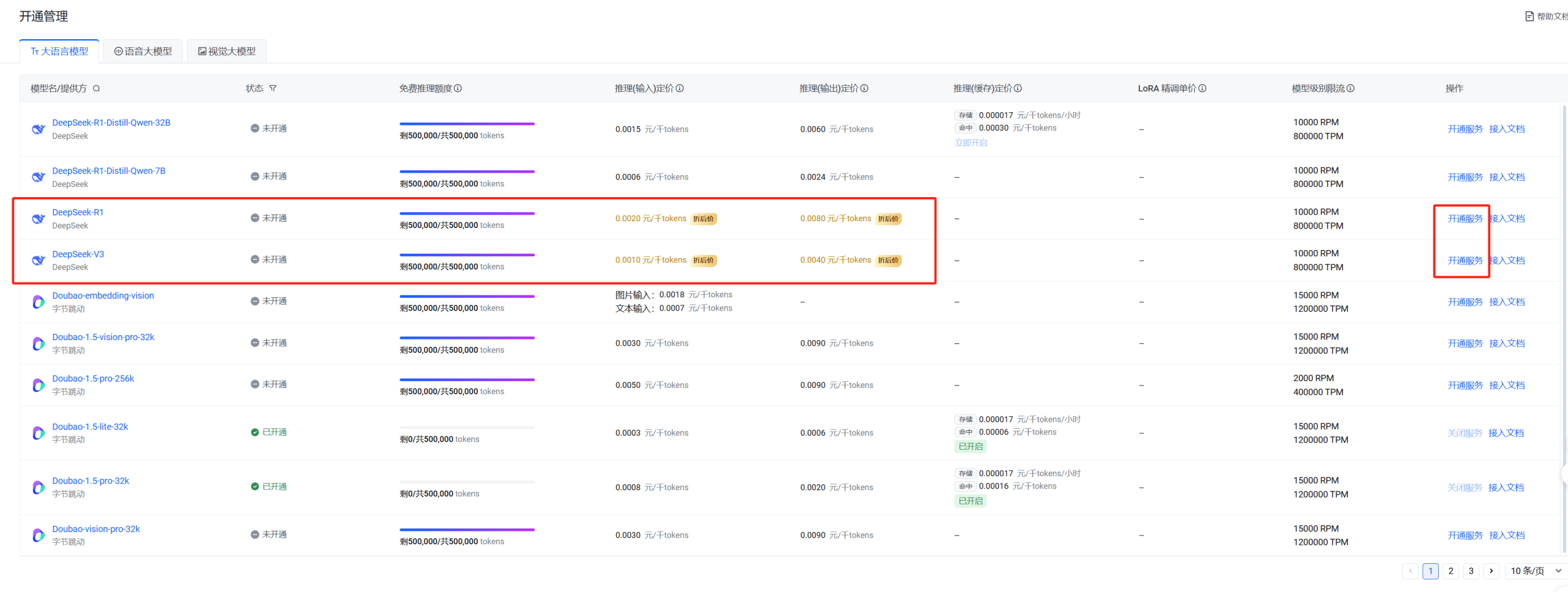
火山的操作方式跟前面两个稍微有所不同。需要先进入开通管理界面,将准备使用的模型开通。
https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement
登录访问链接后的界面如上图,找到DeepSeek-R1模型,点击右边操作下的开通服务。
可以直接把四个都开通。

开通之后,点击左侧菜单的在线推理,然后在右边创建推理接入点。
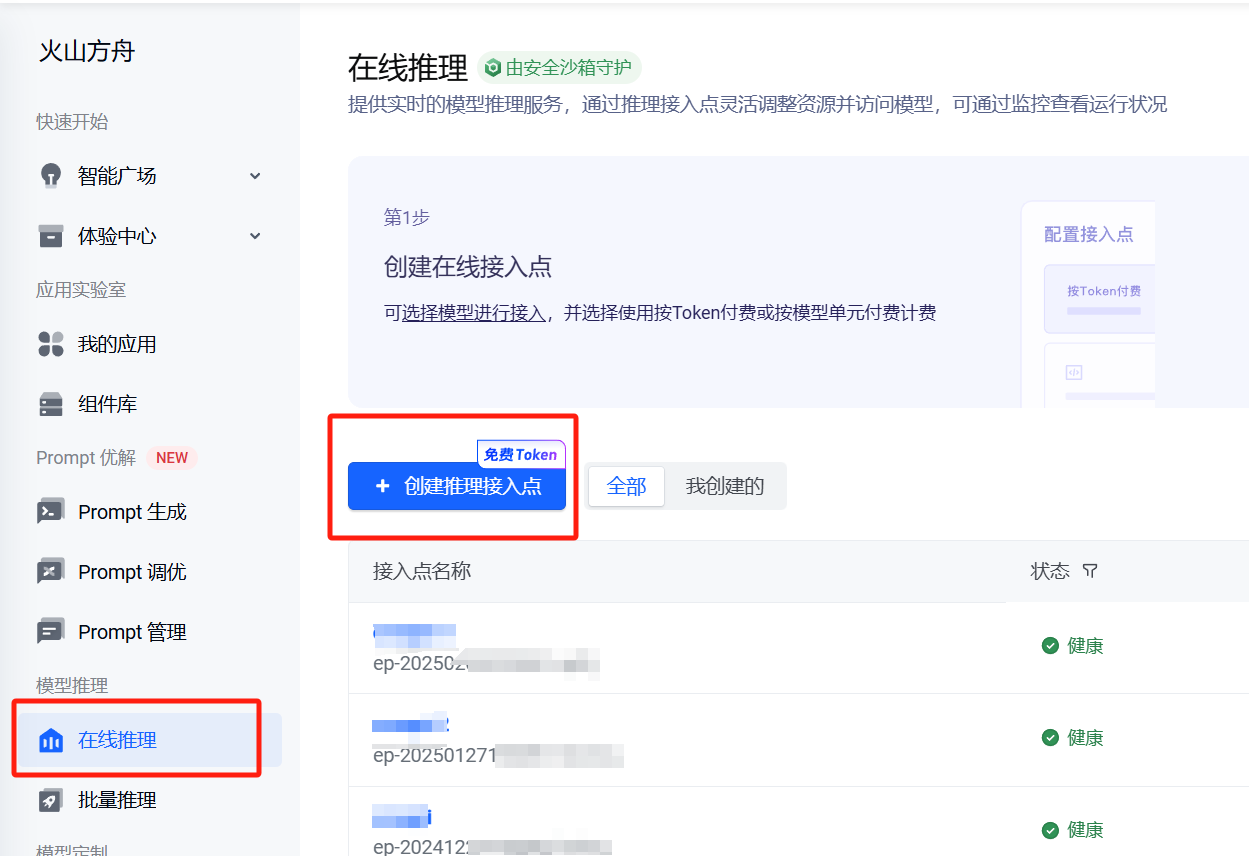
接入点名称随意,模型选择部分选择DeepSeek-R1。
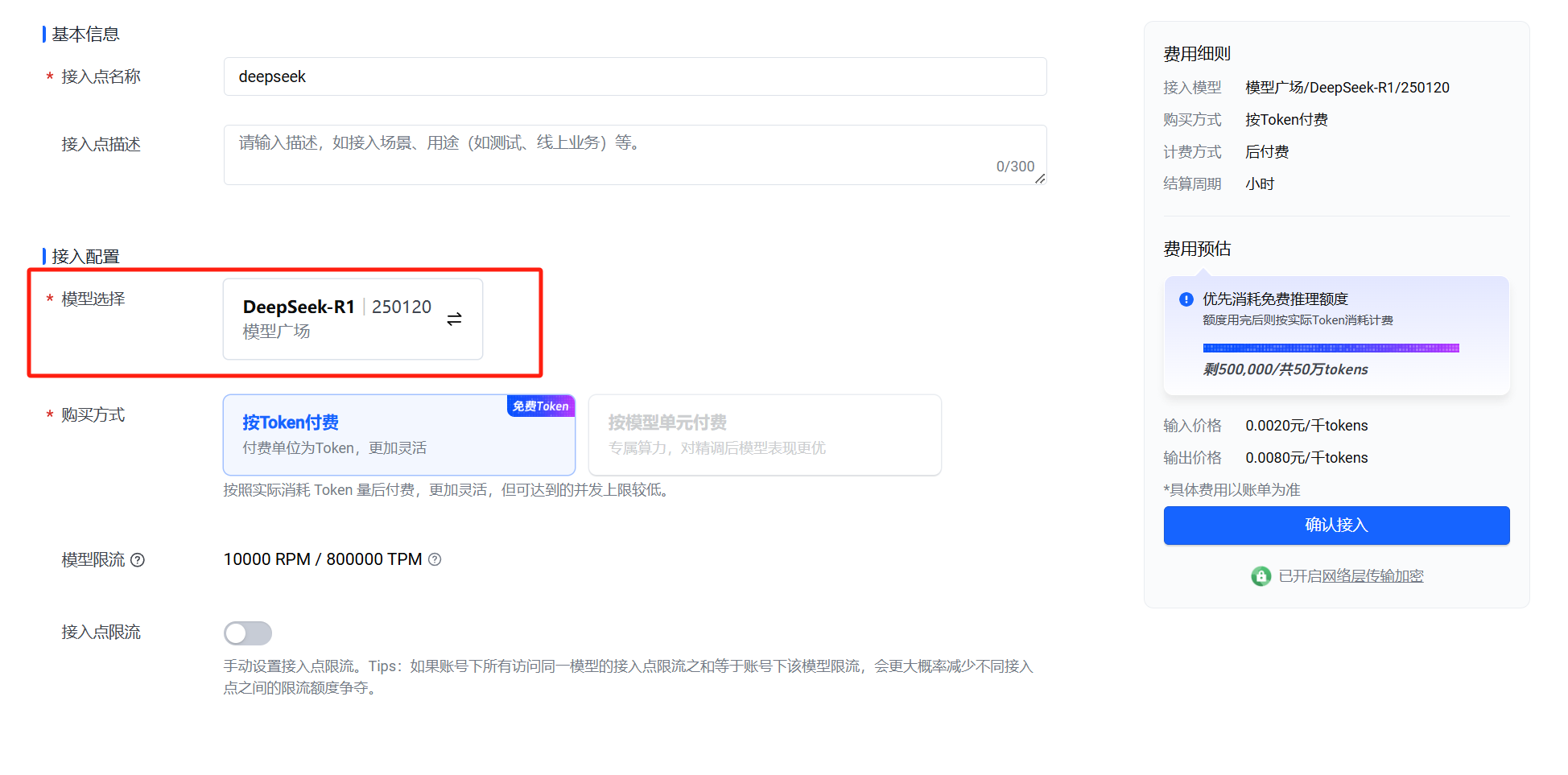
确认接入后,找到刚才创建的接入点。
点击右侧的API调用。

在上面的复制按钮处,复制模型名称。
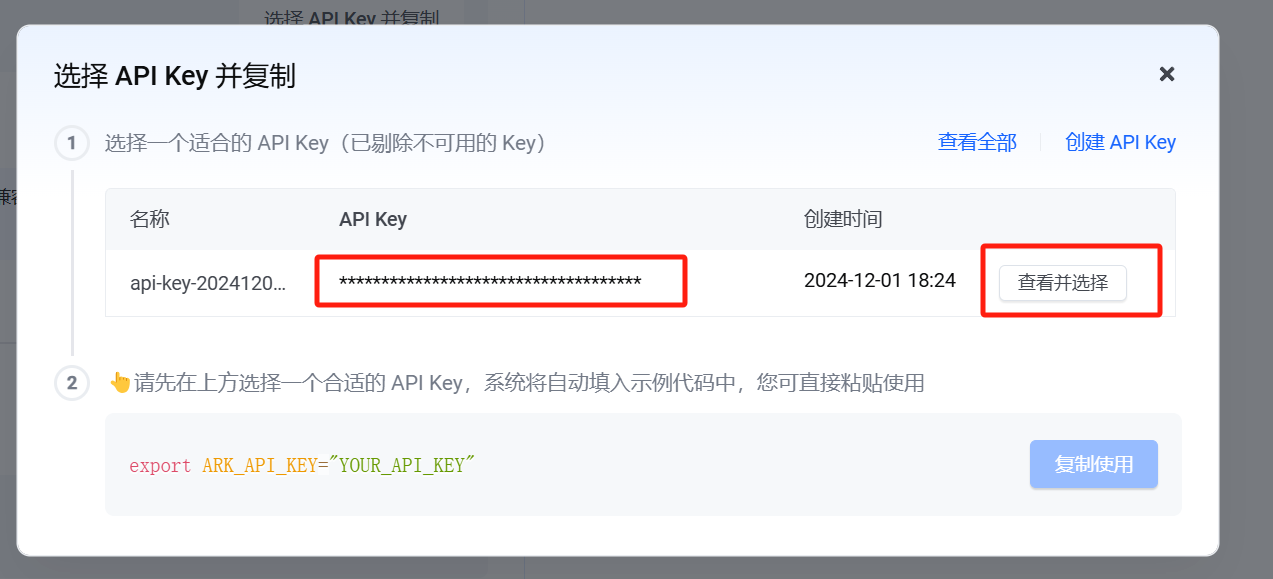
在打开的界面中,右侧选择API Key并复制。
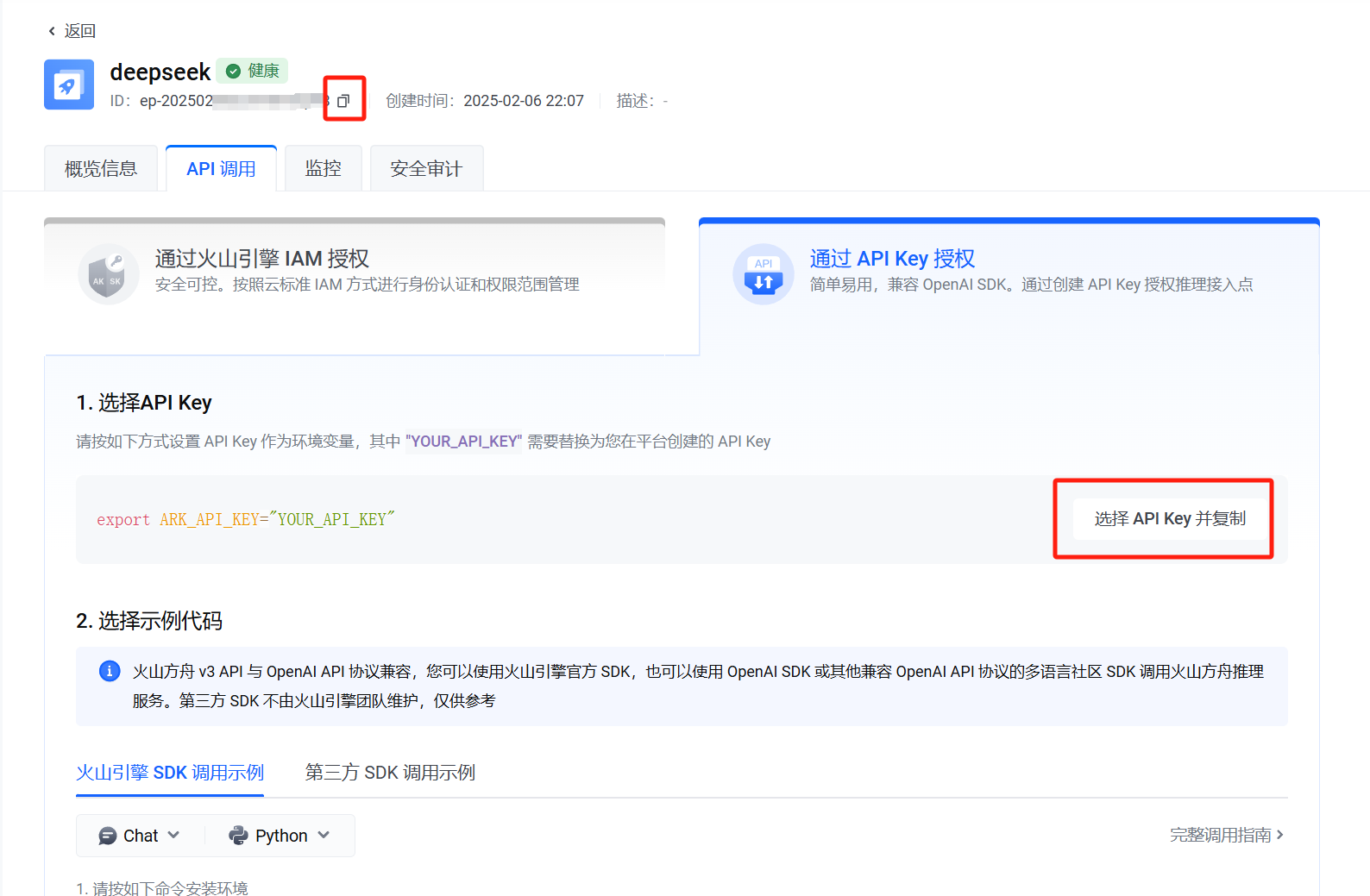
查看API Key并复制。
回到Chatbox中,跟前面阿里云百炼一样。
添加自定义的模型提供方。
名称填写:Doubao(或者你想填的);
API域名填写:
https://ark.cn-beijing.volces.com/api/v3;
API密钥:粘贴刚才创建的密钥;
模型:粘贴刚才点击页面上方复制按钮复制的接入ID。
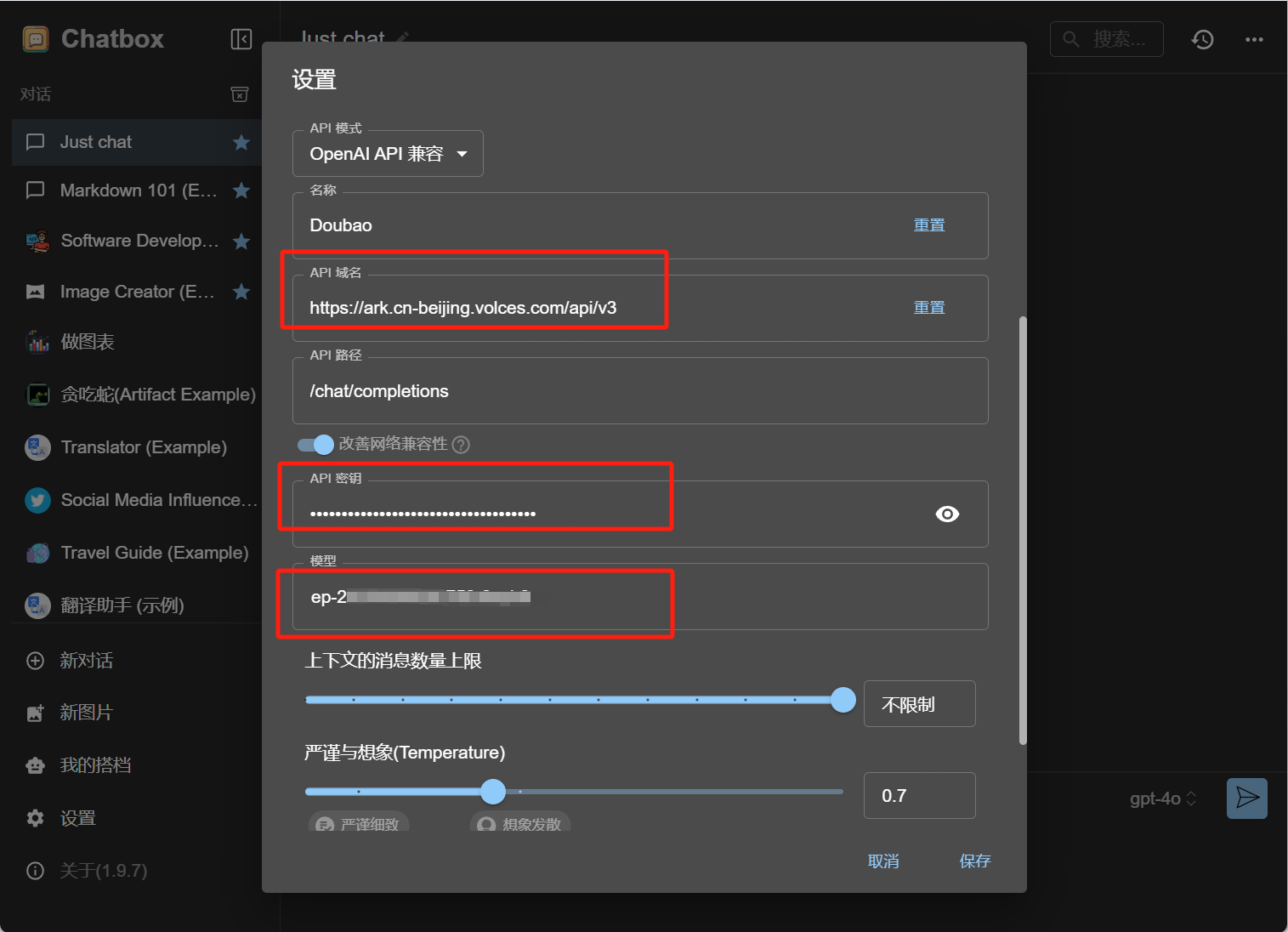
而后保存,就可以直接使用了。
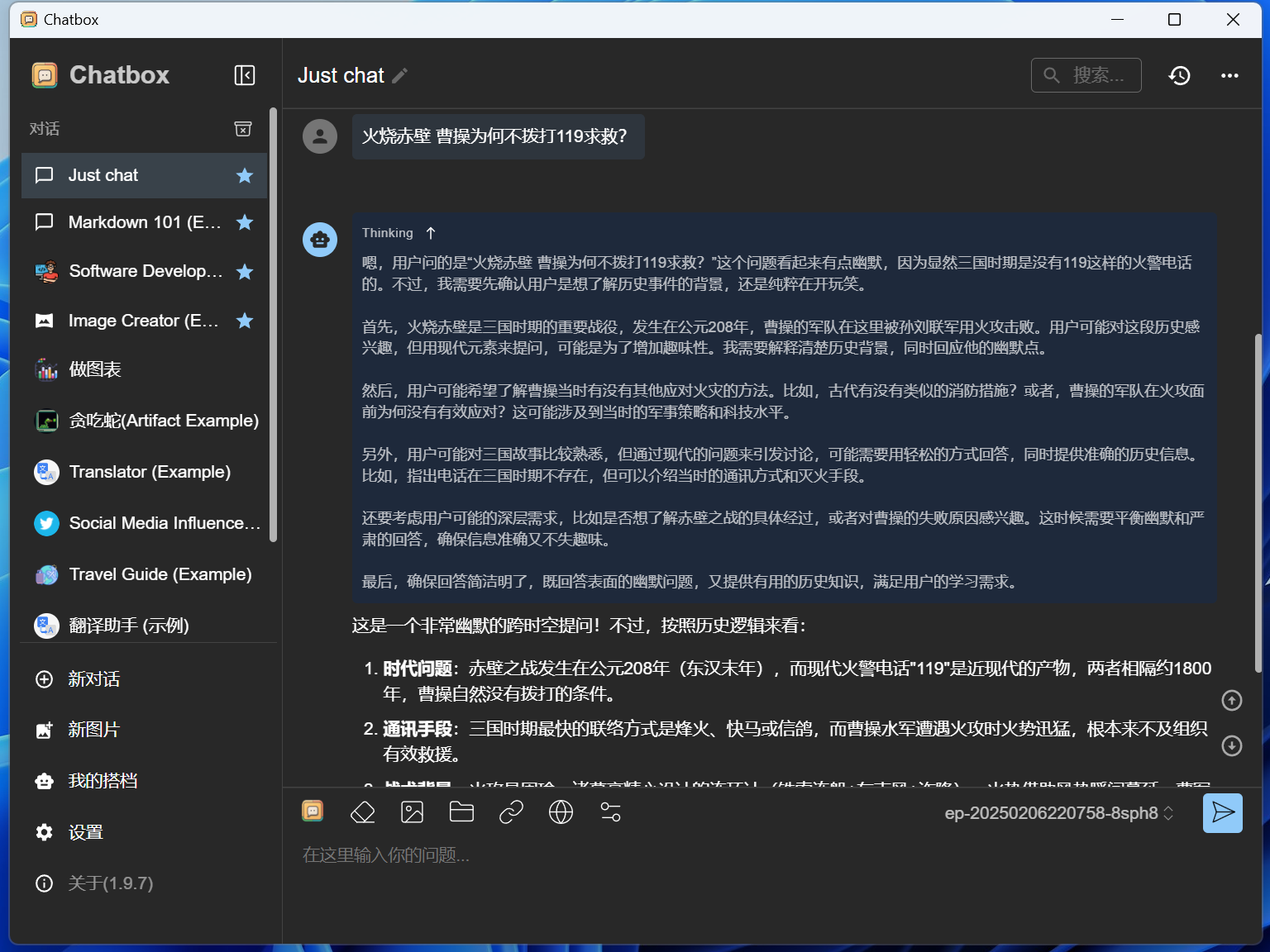
火山方舟的DeepSeek在上述三个里面响应速度可以说是最快的。
可惜免费tokens数量只有50万。
但如果你并不是特别高强度使用的话,50万tokens也是足够用一段时间的了。
手机端的设置跟桌面端基本相同,在此就不赘述了。
另外,除了上述几个之外,百度智能云也有DeepSeek的API提供,并且2月18号前完全免费,不限tokens用量。
但我不太想接百度的回访营销电话(阿里也会打,说做个人研究基本不会纠结啥),所以就没试。感兴趣也可以试试百度平台的。
以及我们之前说过的本地部署:
如何通Ollama本地部署DeepSeek蒸馏模型?小白看这一篇就够了
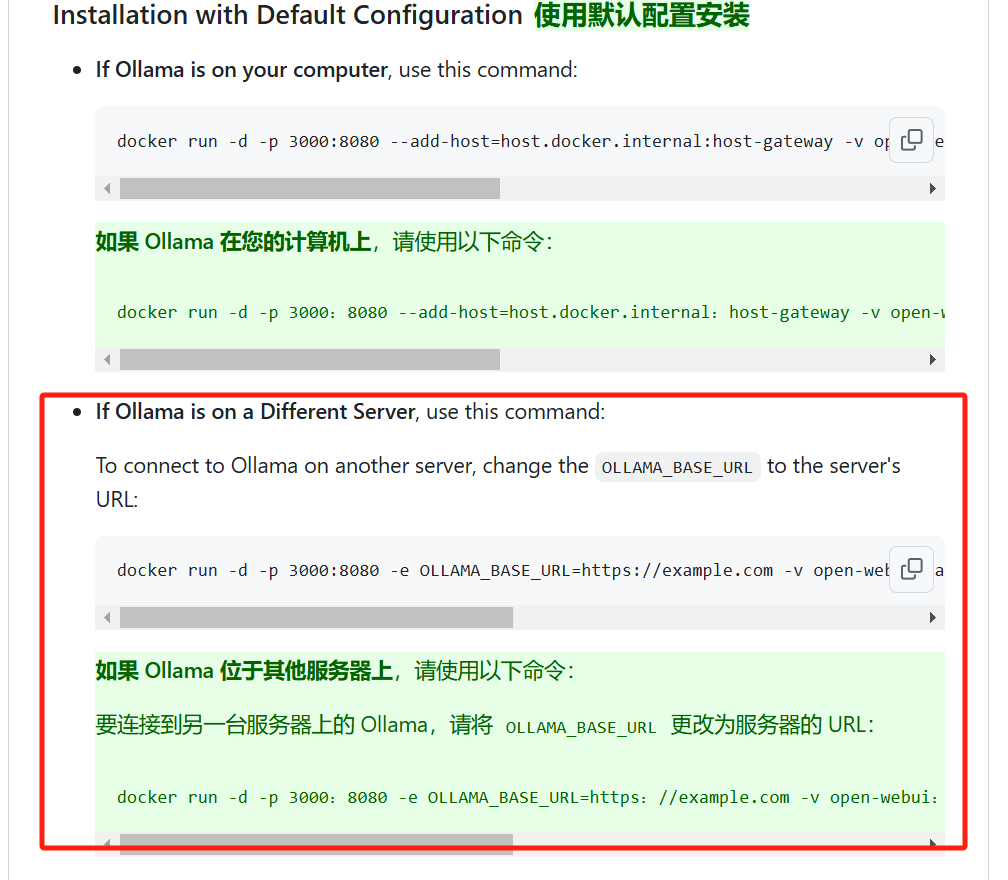
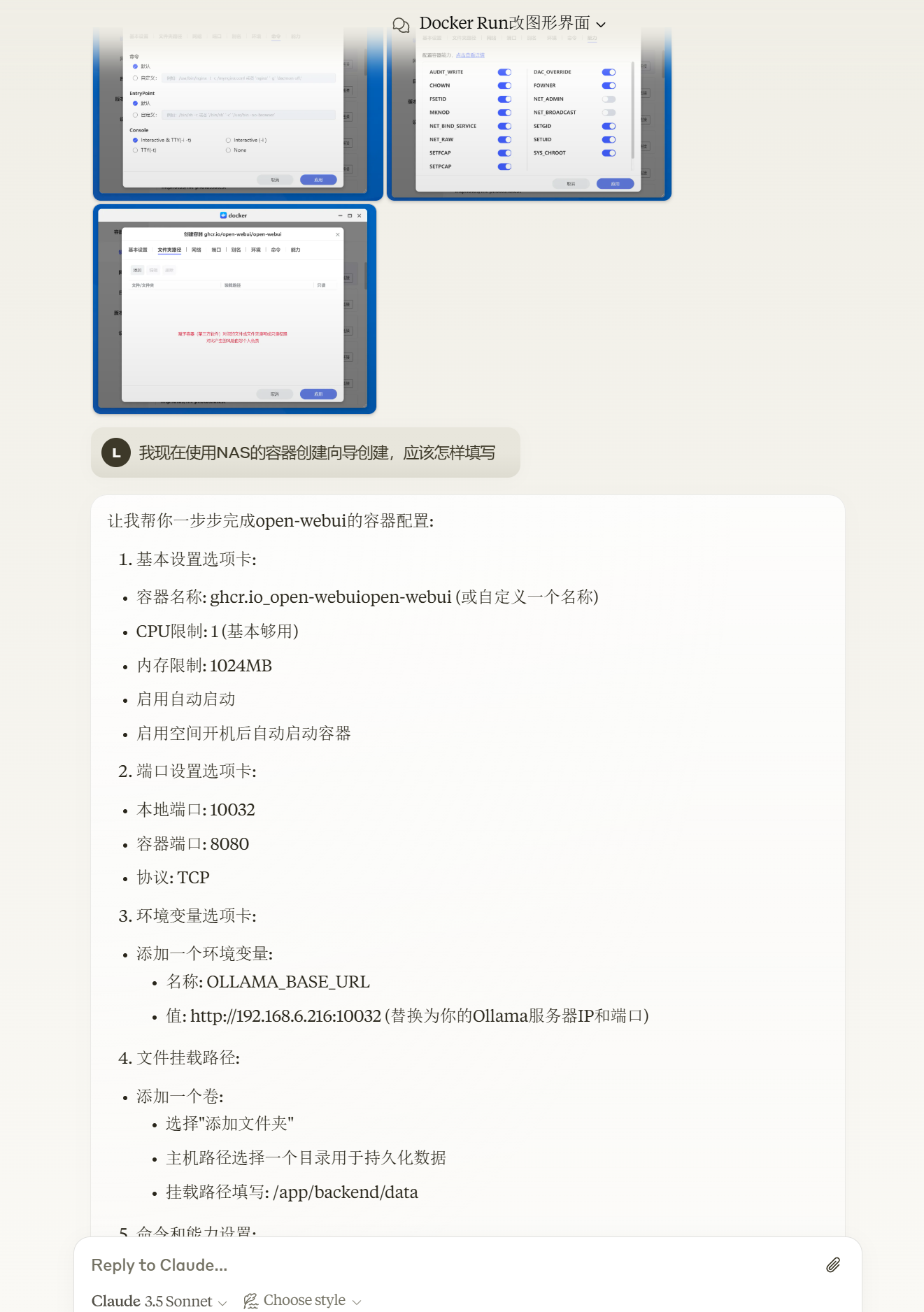
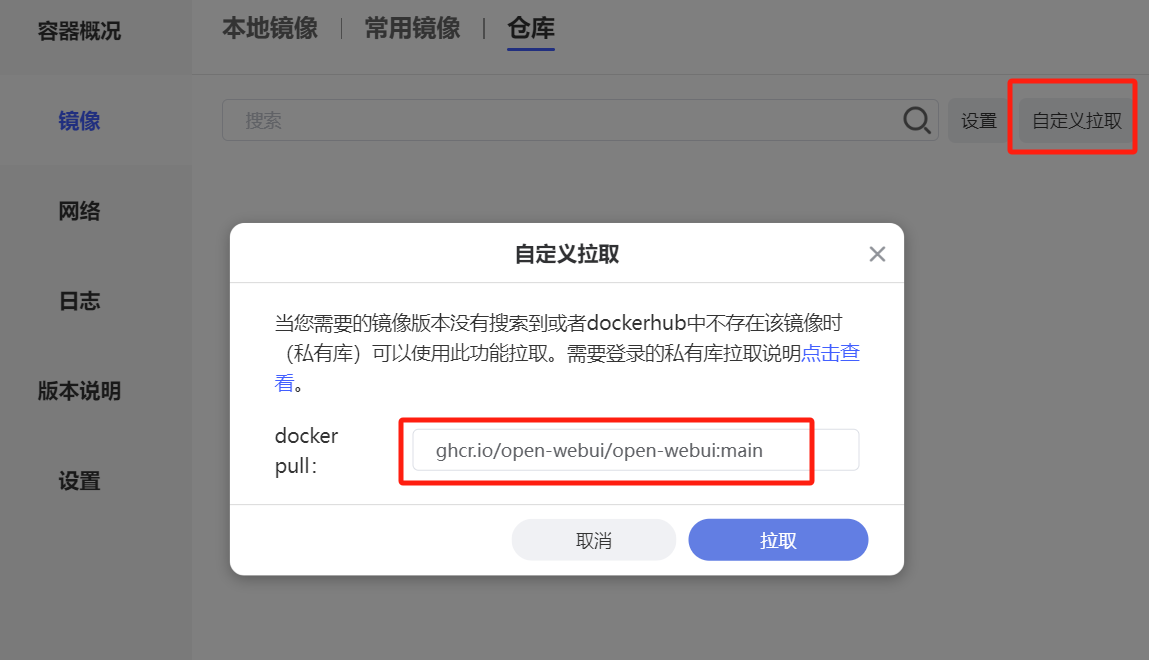
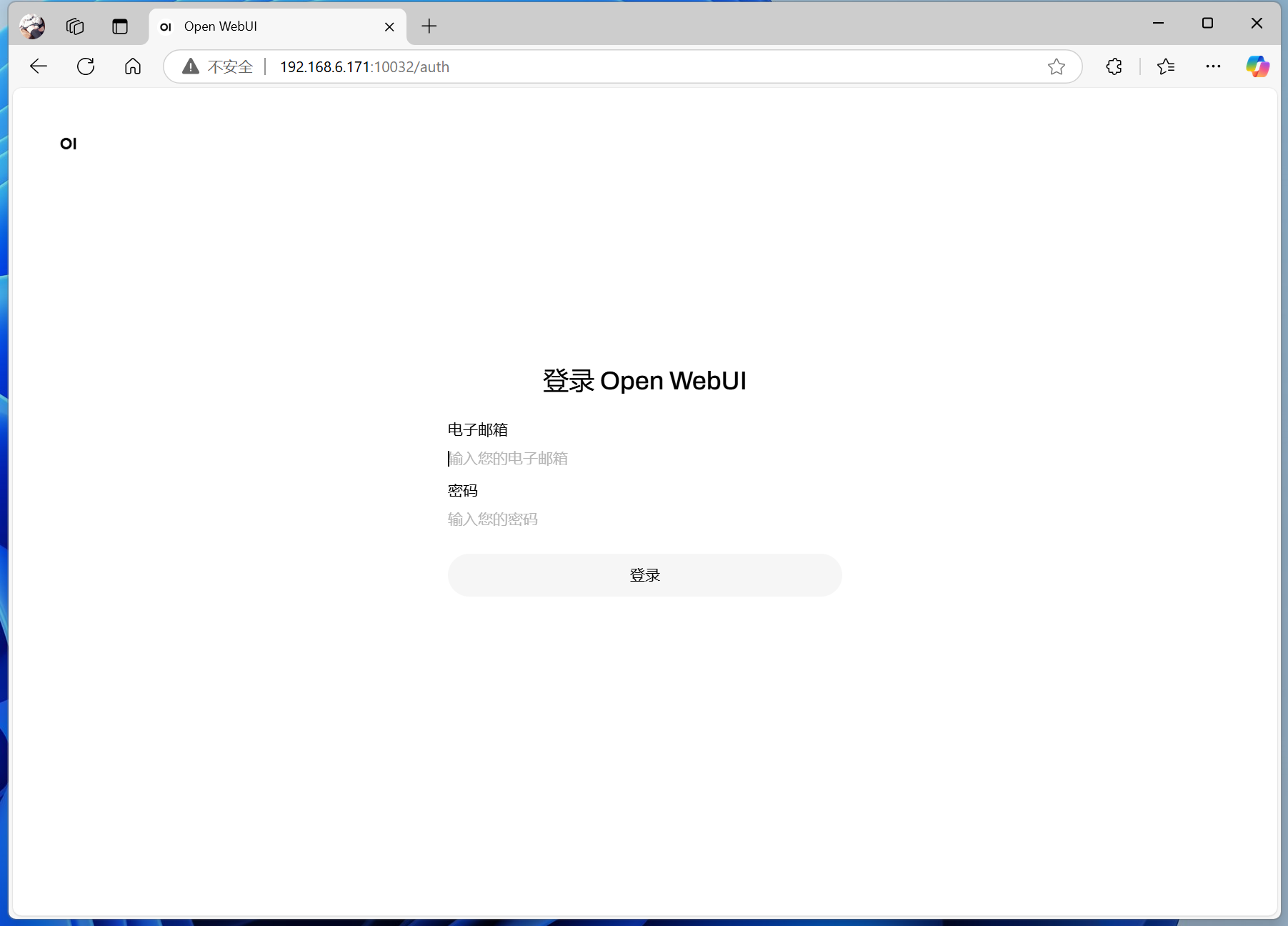
如果你不想使用Open WebUI,或者说想在手机上也能在局域网使用本地部署的大模型,那从这一步开始,也可以改用Chatbox来实现。
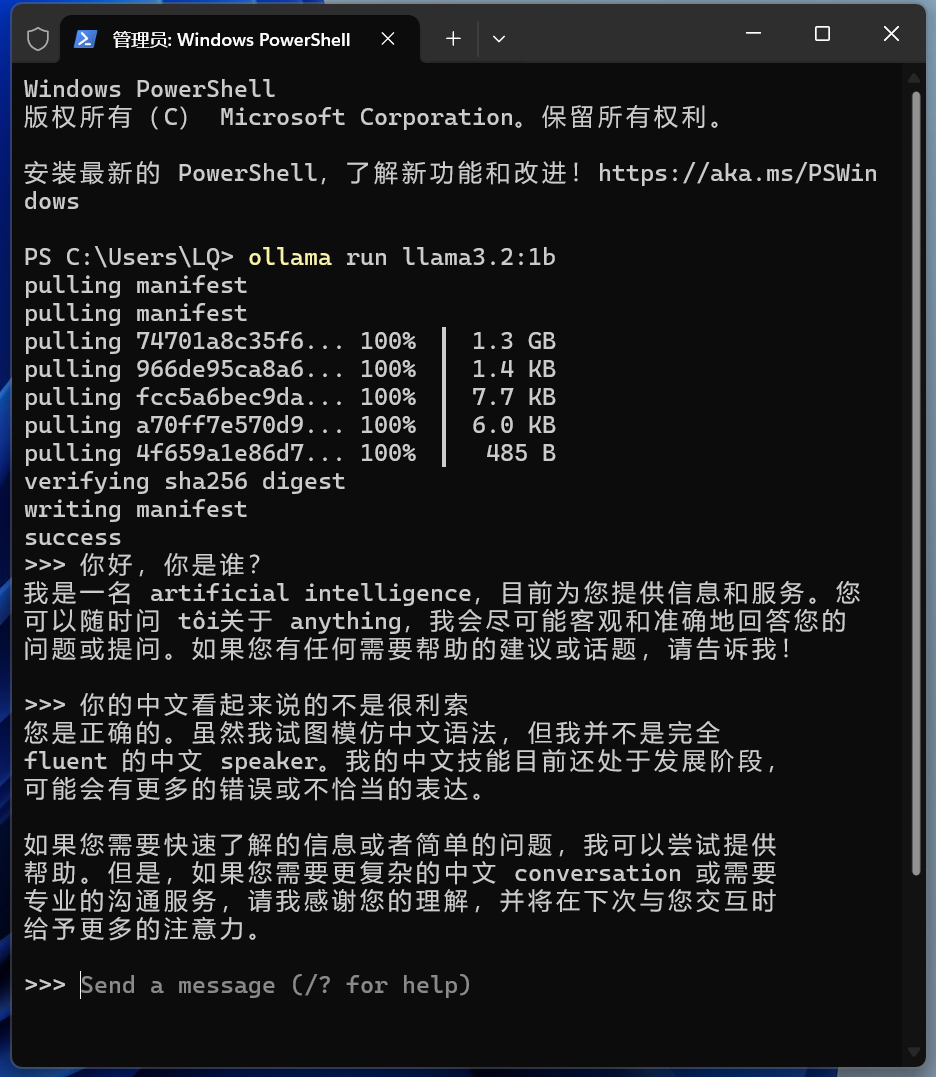
不需要API Key,只需要选择模型提供方为Ollama API,然后填写API域名即可。(当然使用的时候要记得启动Ollama。)
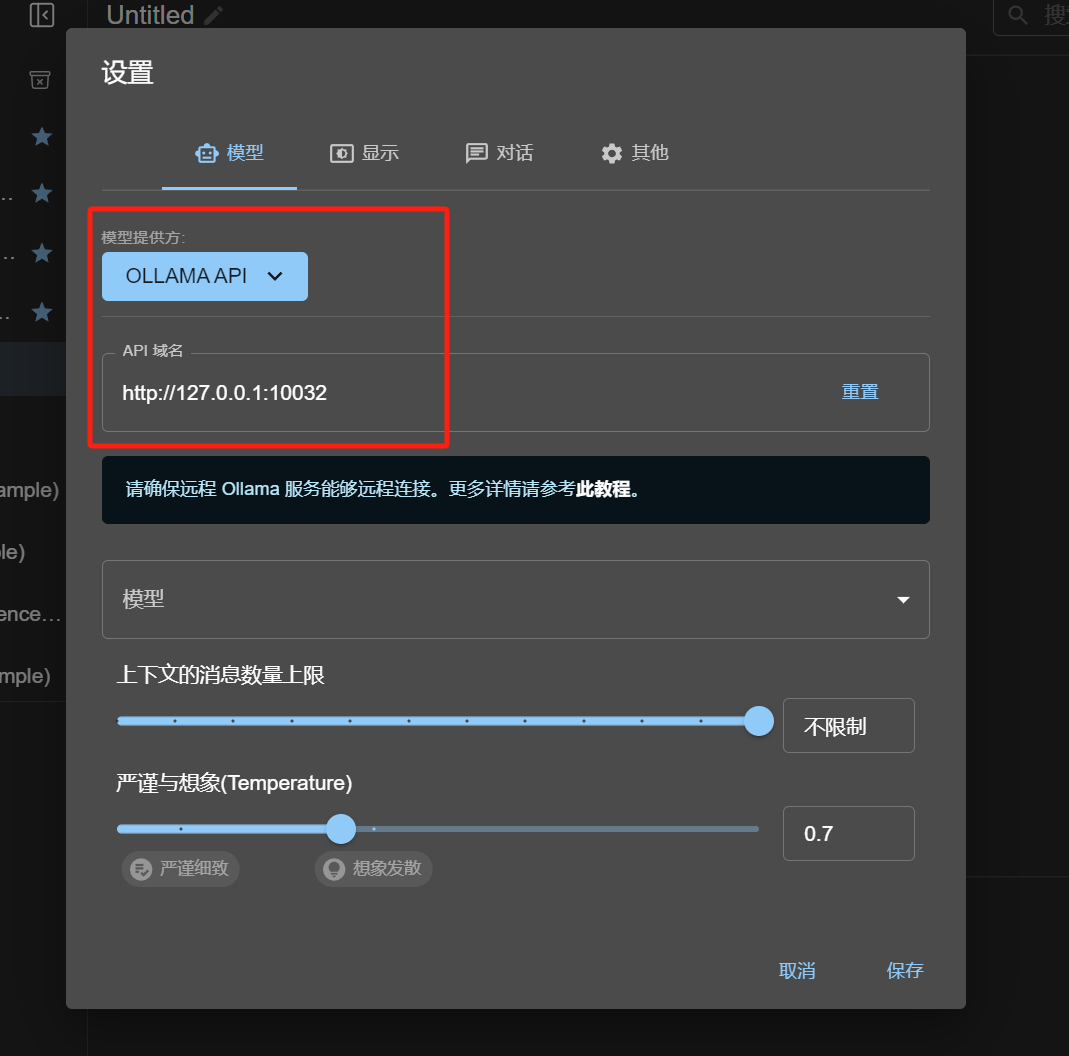
如果Ollama运行在本机,则API域名填写http://127.0.0.1:端口号,或者http://本机局域网IP:端口号;
如果Ollama运行在局域网其他设备,则API域名为http://对应设备的局域网IP:端口号。
端口号如果你是按照教程一步步做下来,应当设置的是11434端口。
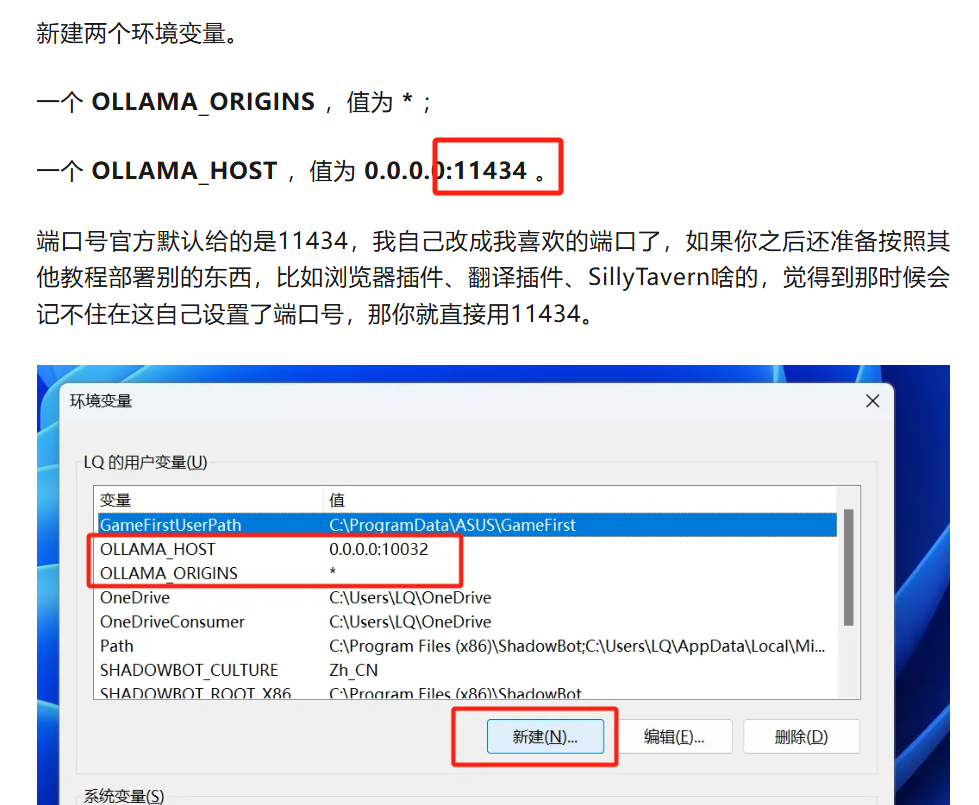
细节可以回去查看刚才说的那篇文章,这里就不赘述了。
配置好后点击保存,你在Ollama上本地部署的开源模型也会直接出现在Chatbox的模型选择列表中。
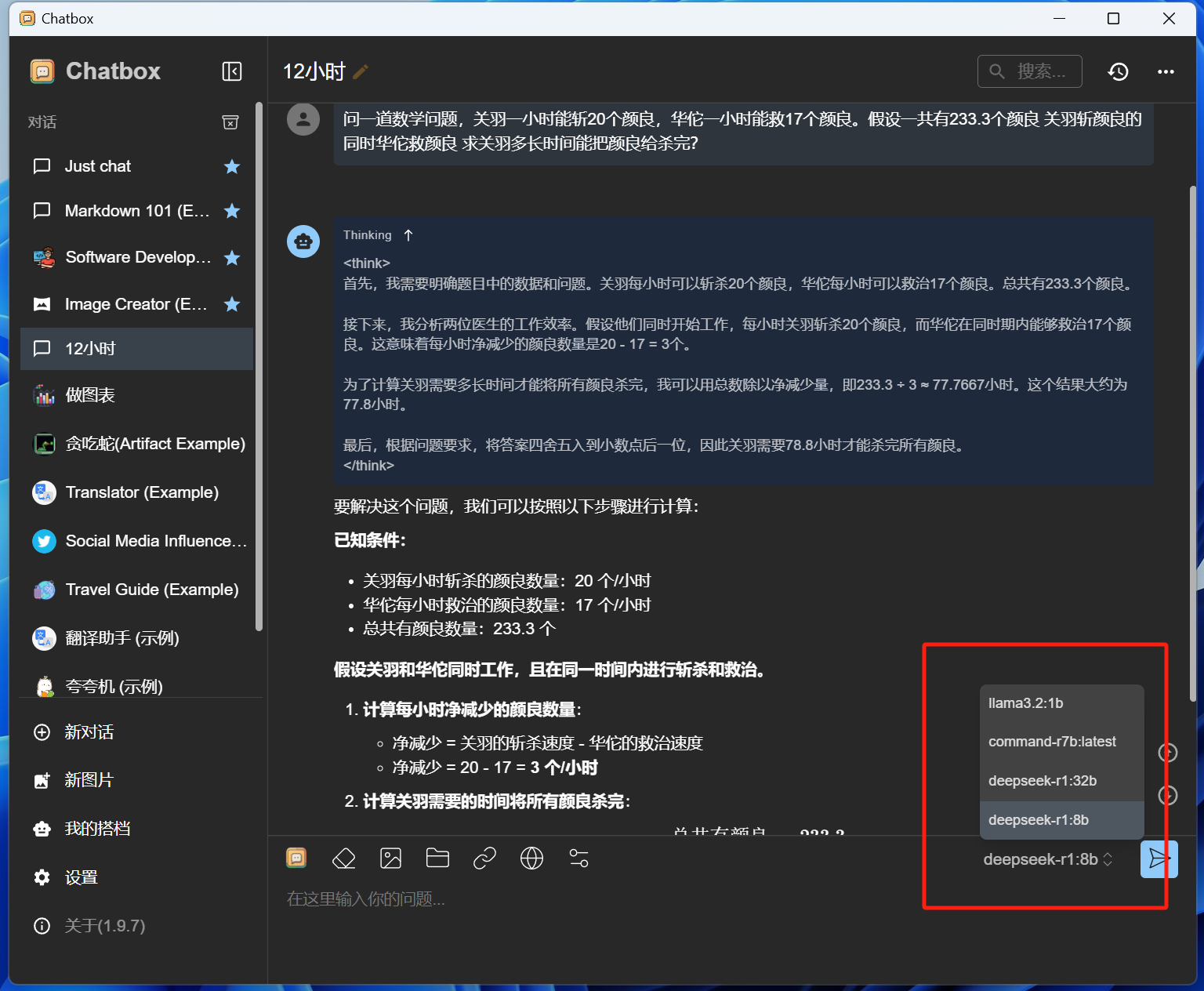
有了这些,应该可以暂且解掉“服务器繁忙稍后再试”的燃眉之急了。
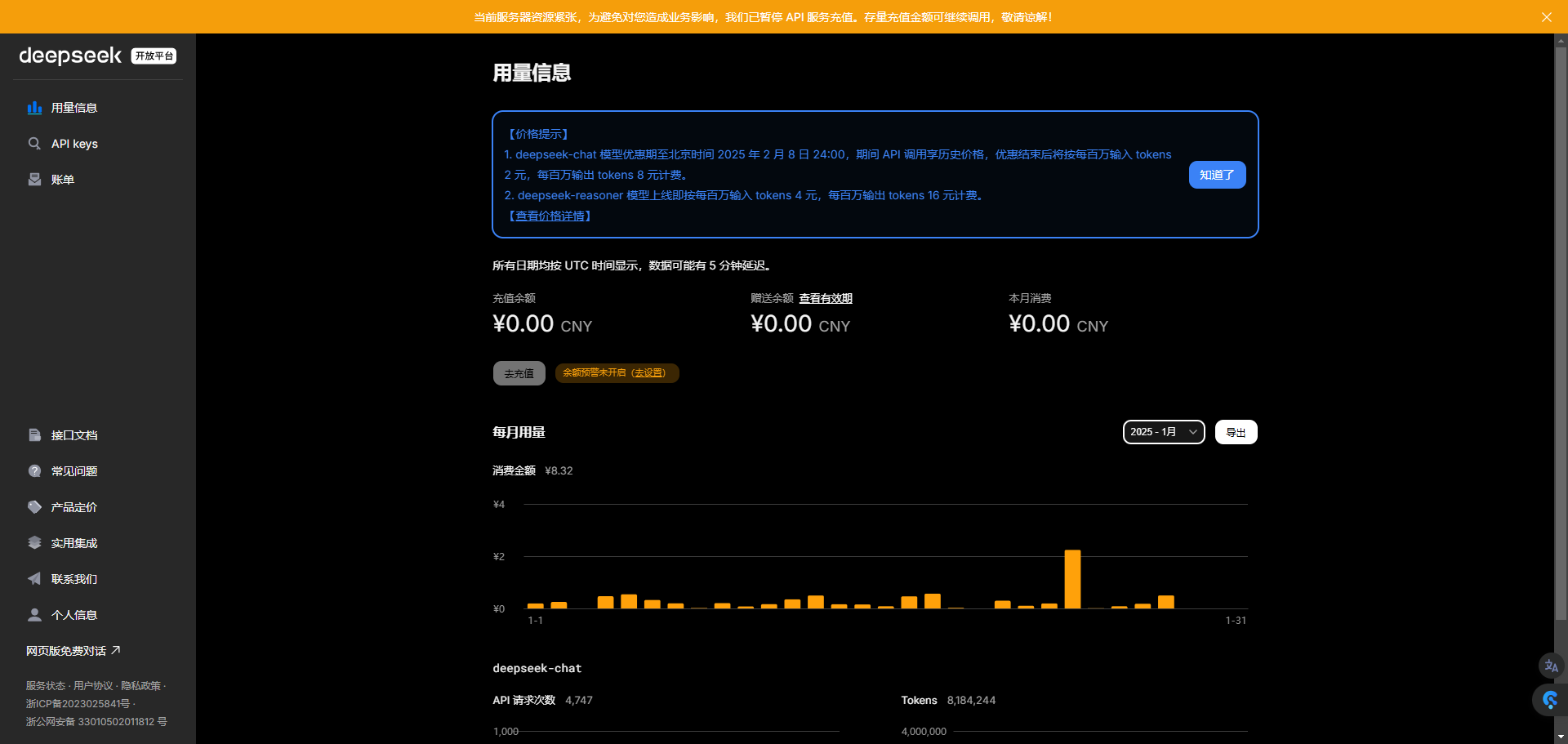
今天DeepSeek官方的开放平台已经恢复登录。虽然根据官方声明,服务器资源依旧紧张,充值功能暂未恢复,但接下来一段时间,官方的服务应该也会开始逐渐改善了。