作为一名Lv6多年的老B友,最近在破站冲浪的时候发现了一个不得了的现象:大量图片广告位上的广告素材,已经悄悄变成AIGC了。
比如:
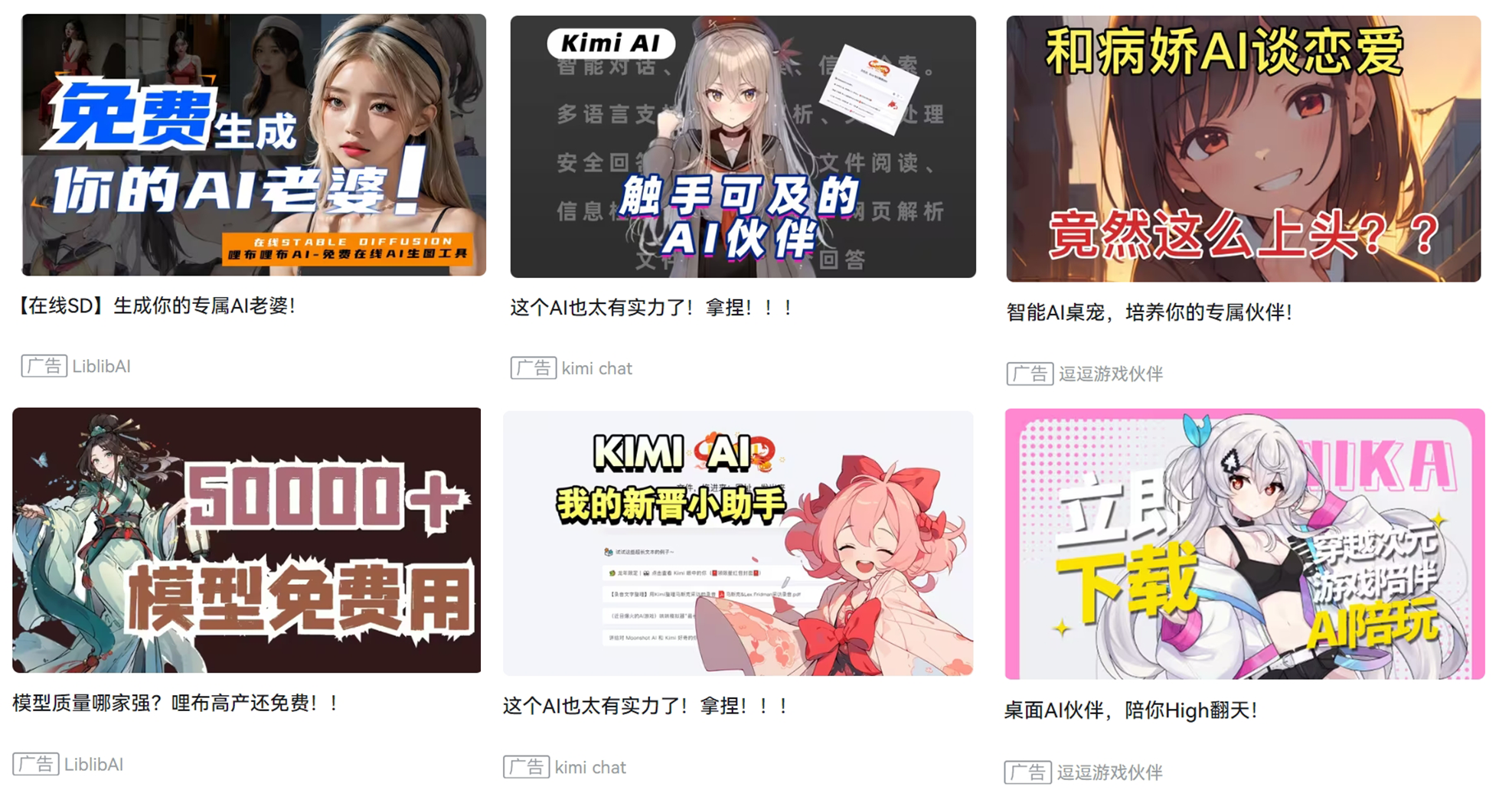
「AI公司使用AI生图倒也合理。」、「二次元罢了用处不大。」
别急着下定论,再看:

这属于是不仅用AI生成了素材,顺带还筛选了脑瓜子符合标准的小猪。

马上又有人要问了:
「AI生成这些素材到底有多容易?咱没概念啊。」
或者
「能不能给俺也整一个?」
别急,我们一条一条慢慢说。
工欲善其事,必先利其器。
首先,你需要能够使用stable diffusion。
如果你的PC性能还行,可以选择本地部署。新手安装赛博佛祖秋叶的webui整合包即可,十分简单,里面还自带了各种插件,很方便;如果无法本地部署,也可以选择在线生图网站,比如上面第一张广告图片里的第一个广告主Liblib(哩布哩布)。
下面正式开整:
一、写实脱(sha)单(zhu)局(pan)
这个可太简单了。
这里需要用到的是真人模型,为了尽可能模拟真实场景,我们先去找一个允许商用的真人模型。
巧了,知名SD1.5模型「麦橘写实」就符合要求。
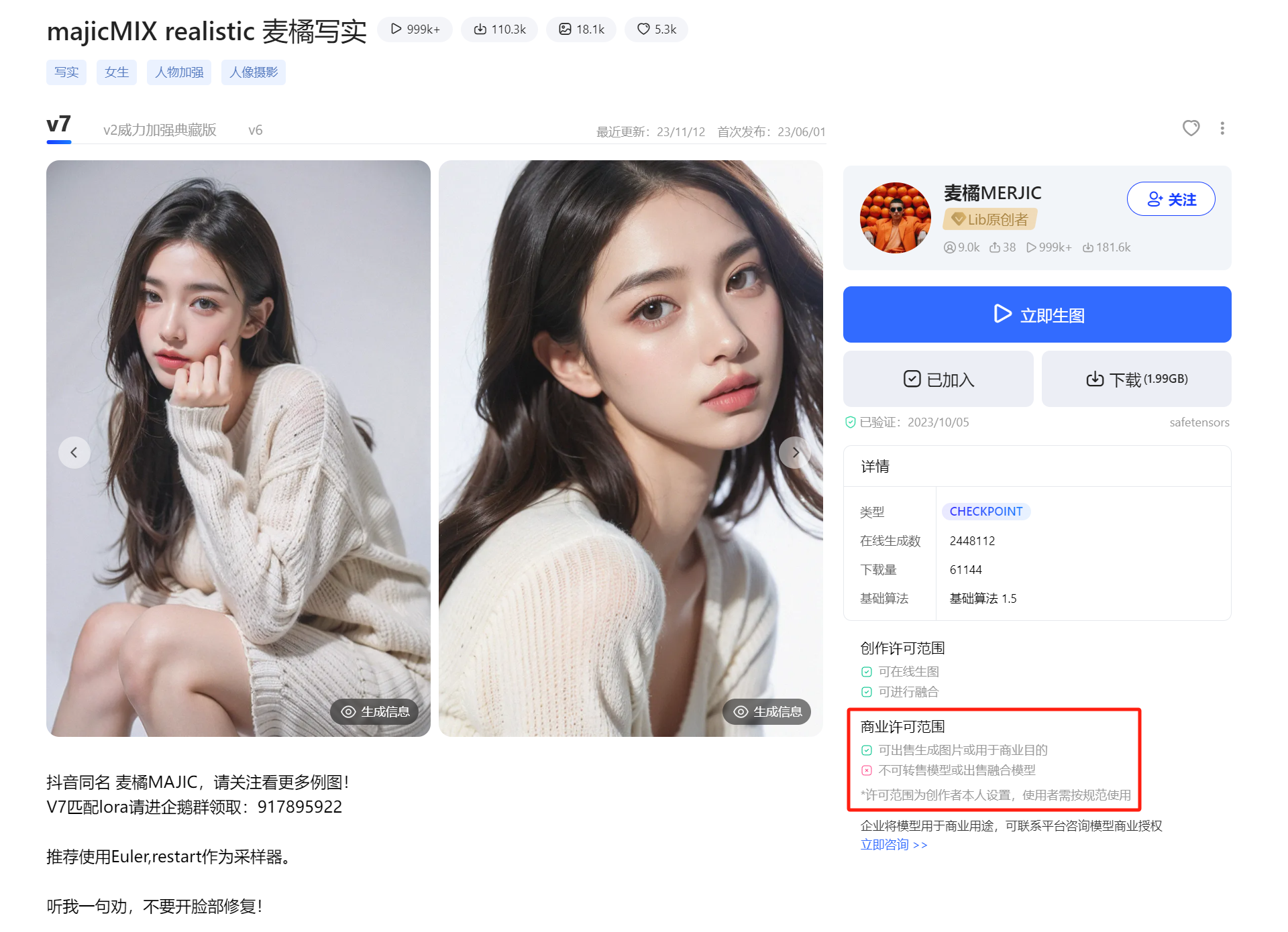
上面那个原图的第一张有点不讲究,一眼就看出来是直接裁剪的人家模型的封面图。连换个参数跑一遍装样子都不装一下,很过分。

所以这张我们就不做了,直接来复刻第二张。

这张按理说直接套一个刻晴的LoRA就可以了,但考虑到作为广告素材使用,最好还是不要跟原图一样搞这么像。
我们直接启动Stable Diffusion,切换模型到麦橘写实。
正好我有OpenAI的API,先来整个活。如果你使用的是秋叶整合包的话,应该自带这个可以使用ChatGPT生成Prompt的提示词插件。
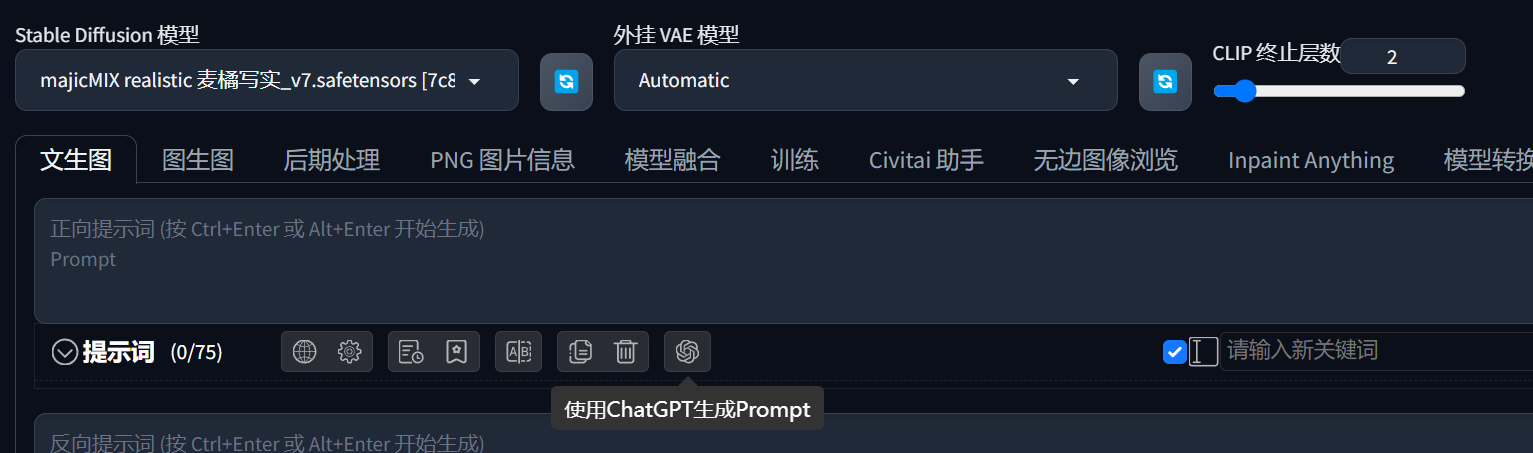
填写上API,选GPT3.5就够了,没有必要用GPT4。然后描述一下原图的这个女生形象。
一个20岁的女孩,正在cosplay原神的角色刻晴。她有紫色的头发和眼睛,银色耳环,紫色领结,紫色手套,露肩,站在路边木屋摆姿势拍照,面向镜头,身后有一些绿植。
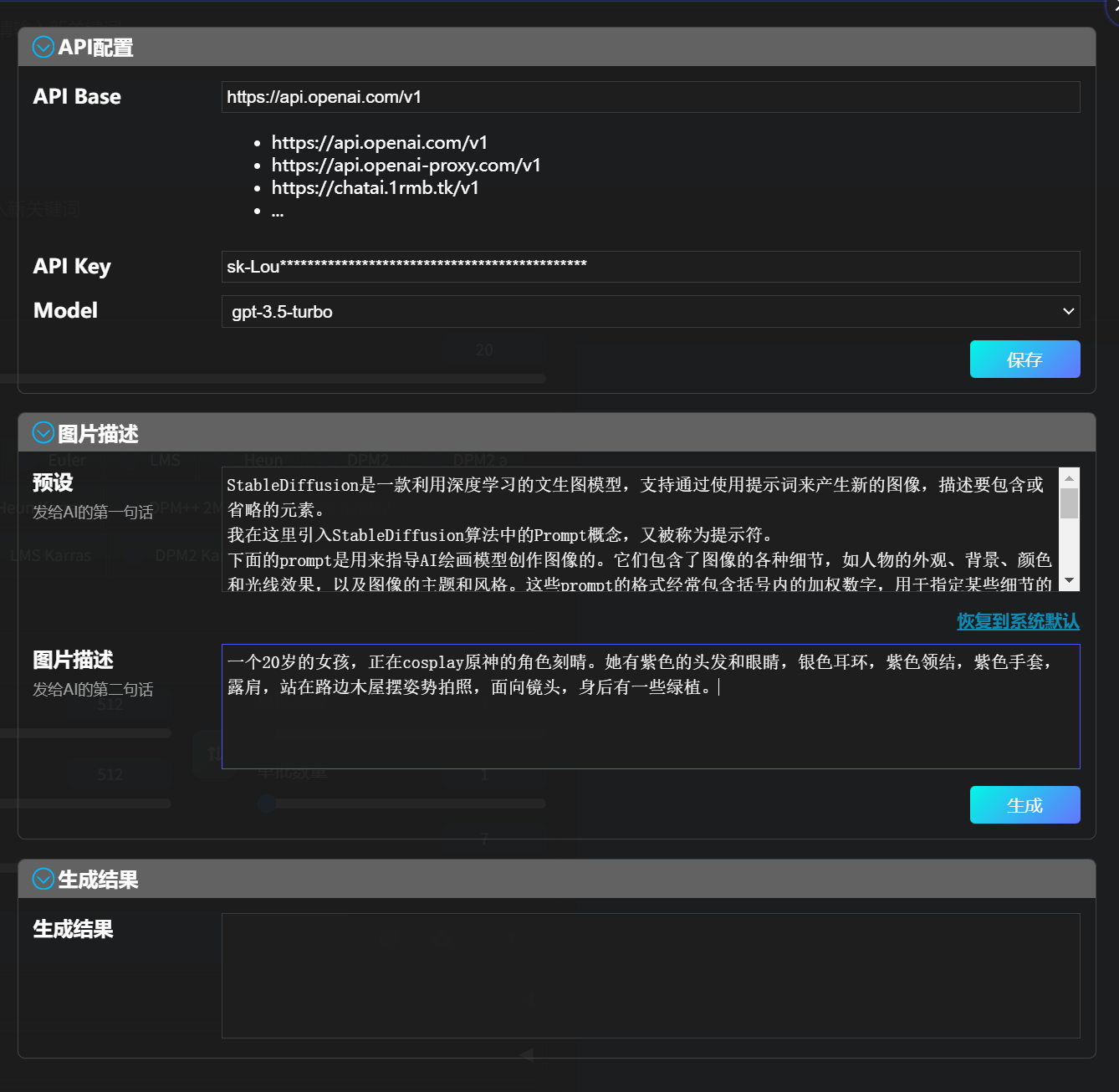
点击生成,GPT直接给到生成结果。再点击使用,这些提示词自动进入正向提示词。
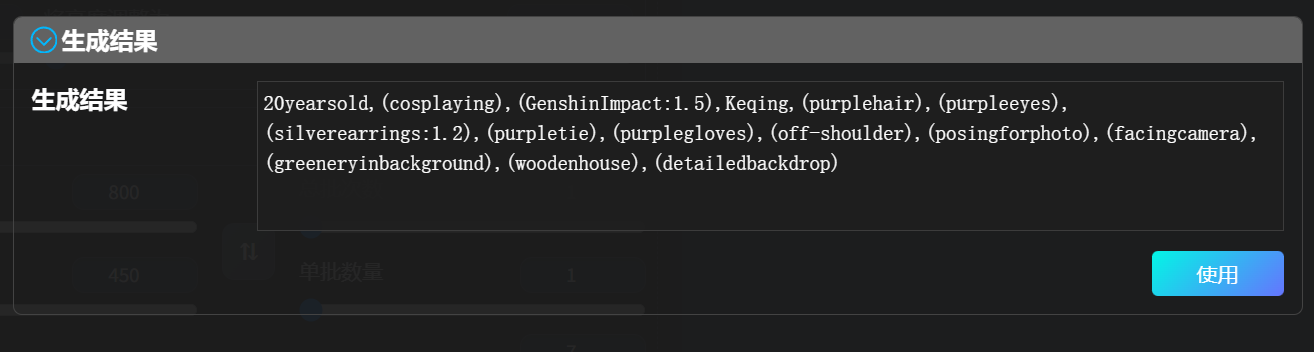
但这些还不够,我们还要在正向提示词里面加入画质相关的词,以及在反向提示词里面输入有问题的手等等词汇。但这些网上都有现成的,所以我就直接勾选三个之前录入好的预设。
同时,为了尽可能控制人物在画面中的比例,避免大头照,加入一个提示词bust(半身像)并稍微加一点权重。

每一个预设里面都带有一组设置好的提示词。
一顿调参操作后,点击生成。
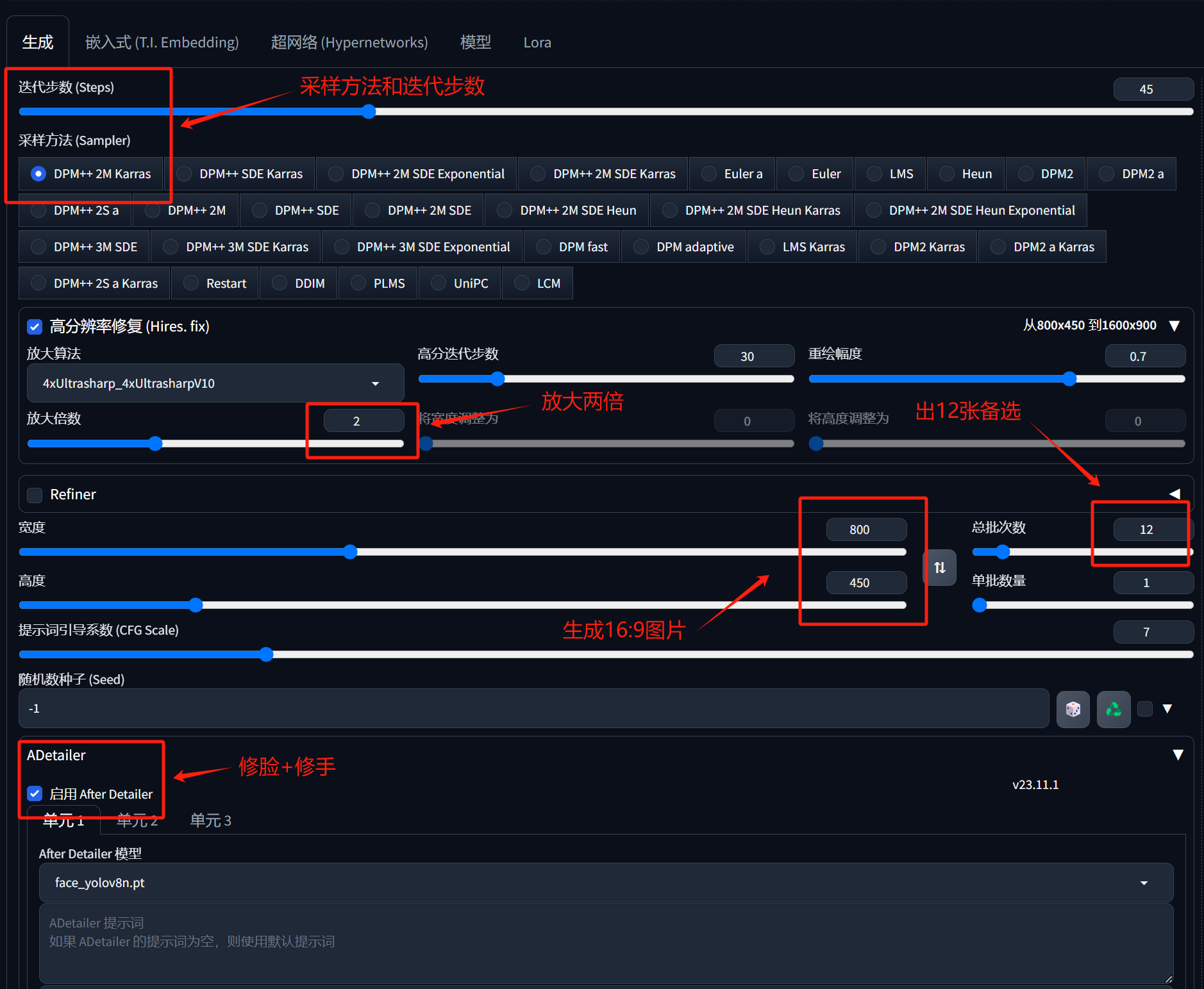
然后得到一版图片:

嗯,木屋的权重有点高了,可以再添加一个绿叶的关键词。但没关系,这一版里面也可以挑出来两张能用的。
女主既看起来像玩Cosplay的,又不是刻晴。


二、动漫底图+字
像这样:

这种就更简单了。
二次元风格就不能继续用刚才的模型了,我们需要再找一个二次元模型。
比如SDXL模型「anima_pencil-XL」。
这个模型同样对生成的图片允许商业使用。
如果你有其他模型分享或者想试试其他模型,我在知乎提过一个问题,可以去补充或查看。
有哪些生成图片允许免费商用的stable diffusion模型?
https://www.zhihu.com/question/645824762/answer/340918924
我们还是启动SD,切到相应的模型。
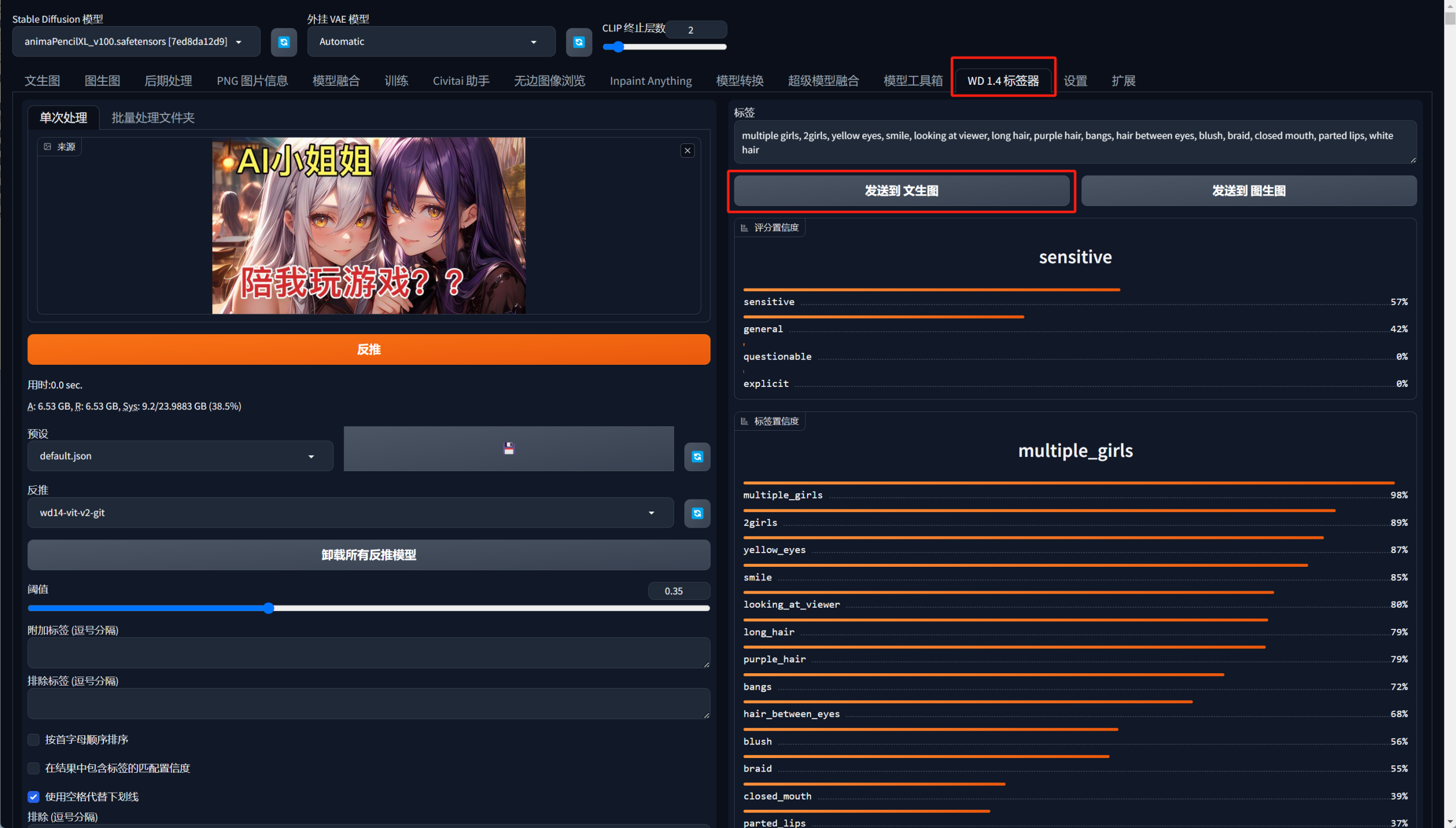
这次不用GPT了,换一个反推提示词插件wd1.4标签器(秋叶整合包自带)。
把需要复刻的图片拖到图片来源位置,右侧自动跟进图片反推出了提示词,然后直接把这些词发送到文生图。
跟刚才一样,增加预设词,调整参数,点击生成。
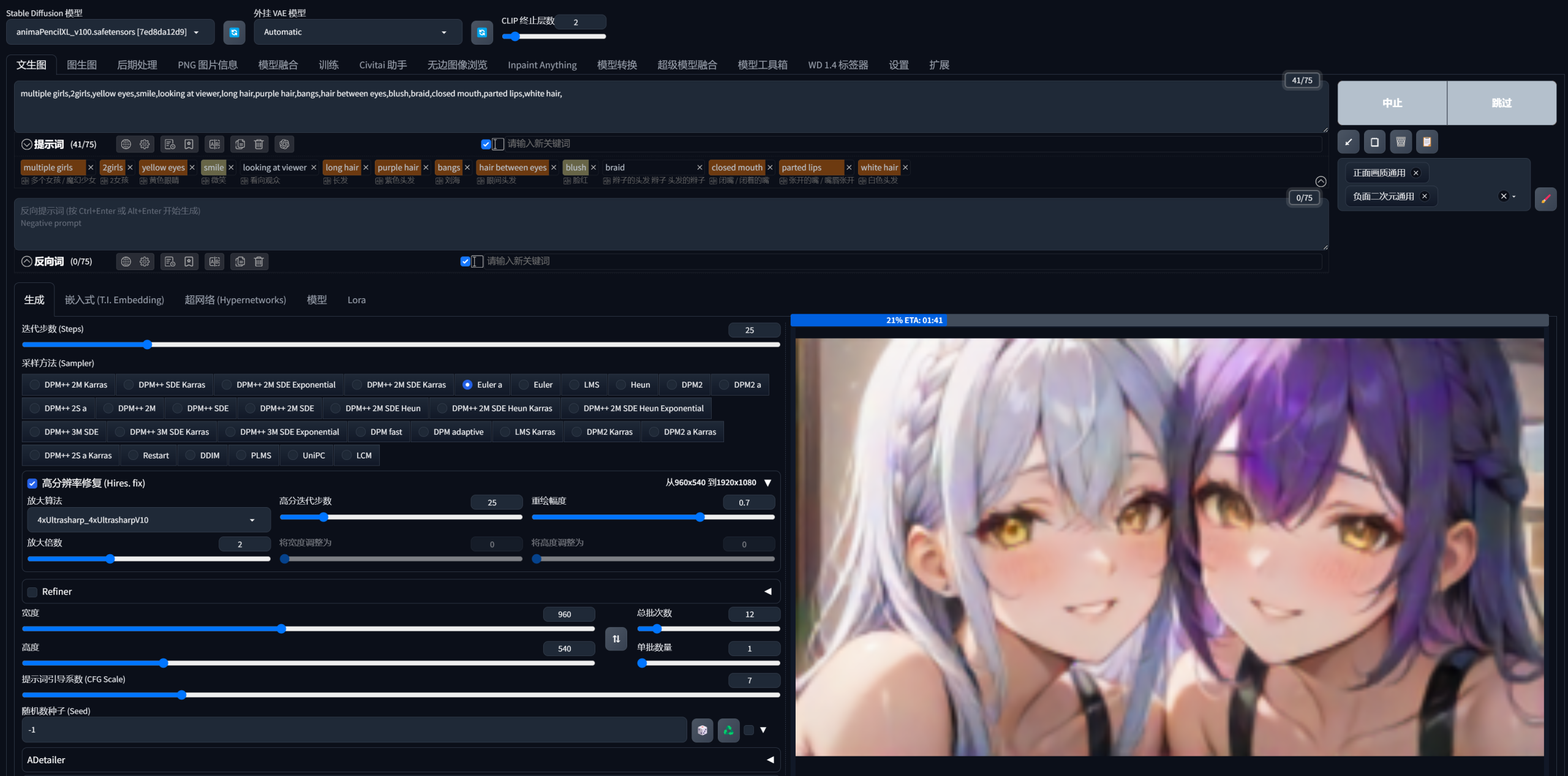
一样一版12张,甚至都不需要开修脸。

再来一版蓝毛猫娘。

随便找个修图软件加上字,哪怕你不用电脑,醒图之类的手机app也行。


三、透明图层+底+字
最近刷到的典型的就是KIMI AI的一些素材:

顺便Kimi是我自己最常用的几个AI Chat工具之一,推荐试试,DDDD。
这种图的重点是需要把动漫人物抠成透明图层,如果像前面一样生成带背景的图片,会很难抠下来。
所以,第一种方法:
删除所有背景提示词,例如窗户、窗帘、书架、书桌等等,同时在正向提示词里增加一个关键词transparent background(透明背景)。

生成一版看看。
这版有点扑街,没出来多少纯黑纯白底。

再来一版。

有了。
像这种纯白底的,就可以在Photoshop里比较容易地把背景去掉。
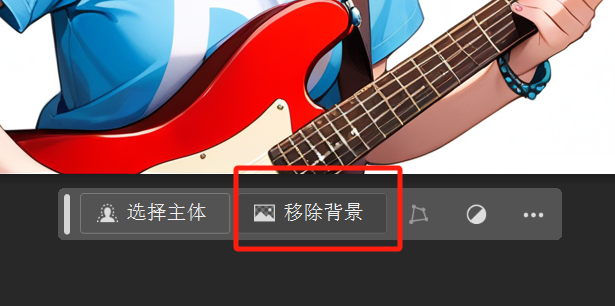

纯黑就要差一些。

但也难免有些识别不准的还要花功夫擦回来,比如这个吉他。
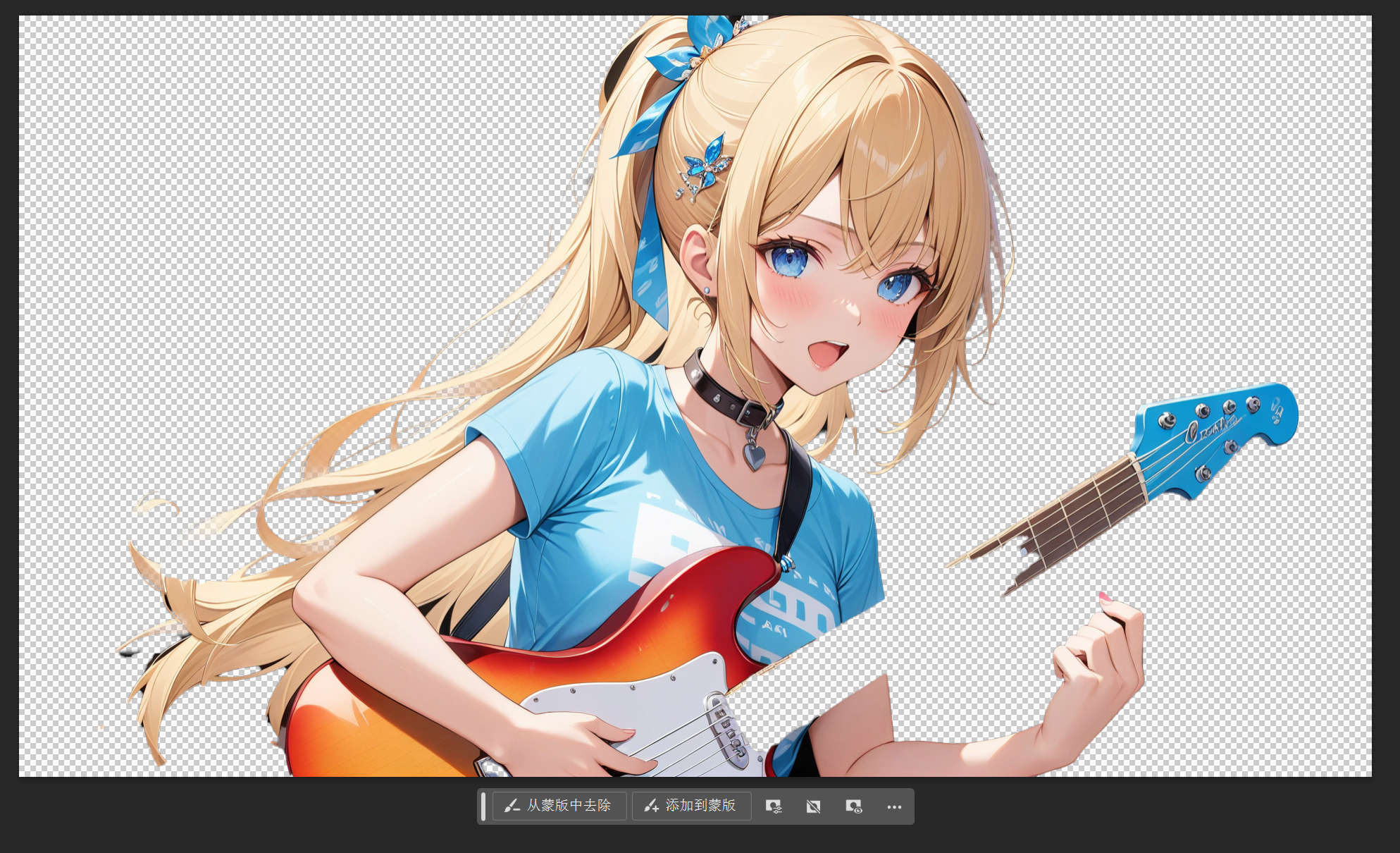
渐变蓝就更麻烦了。

所以这种方法就稍显复杂了,要么前期抽白,要么后期修复。
有没有更好的解决办法呢?
那就要说到第二种方法:通过LayerDiffusion插件,让AI直接输出透明图层。
如果你了解一些AI绘画,那么你或许没听过LayerDiffusion,但你大概率听过ControlNet,而LayerDiffusion就是ControlNet作者的另一个作品。同时,这位大神还制作了一个webui的优化分支stable-diffusion-webui-forge。LayerDiffusion目前只能运行在forge版本的webui上(似乎最近两天也有了非官方的comfyui版本)。
所以,接下来的操作没办法直接继续在秋叶整合包上完成,需要再重新安装forge版webui并安装LayerDiffusion插件。
安装好之后,基础过程没什么区别。注意由于我们只要png透明图,尺寸选择512512方图再高清放大两倍即可,并且在提示词中添加「full body」以尽可能获得全身图,同时启用LayerDiffusion的Only Generate Transparent Image*(Attention Injection)模式(LayerDiffusion还有很强大的blending功能,同时也不仅能应用于二次元模型,但在这里我们只用它来生成动漫人物透明图层)。
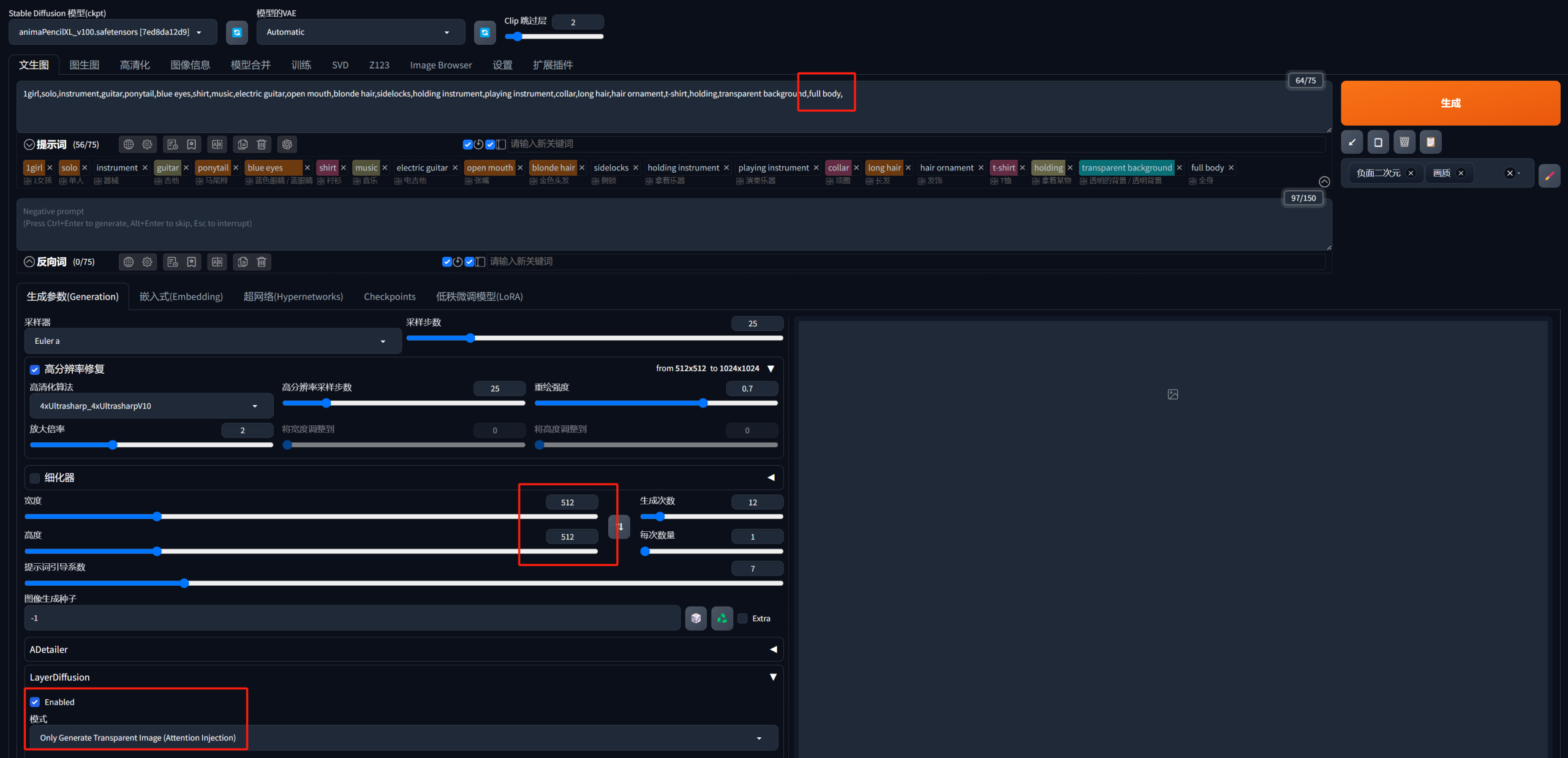
之后正常点击生成。
现在,我们得到了一版透明背景的人物。

以截图作为背景,加上文字,即可达到原图的效果。


图层化的另一个好处可以建立元素与文字直接的空间关系,例如:

这两张原图应该并非AIGC,但不妨碍我们也来复刻一下。
类似的背景,如果你没有素材,同样可以使用AI生成,方法与生成人物一样。但肯定有人又要说,我没有生成背景的模型。
那也简单。我们随便找一个在线图片设计的网站,比如创客贴,筛选它的公众号封面免费模板。

筛选一个跟原图比较接近的边框+波点组合的模板。

删掉多余的部分,只留背景,并调整一下尺寸,这就得到了一个边框,下载备用。

跟前面一样,使用Layer生成一批PNG形象。

跟前面的背景放在一起,开始添加文字。

当然也可以直接把png文件上传到创客贴,在线完成背景调整和文字添加。
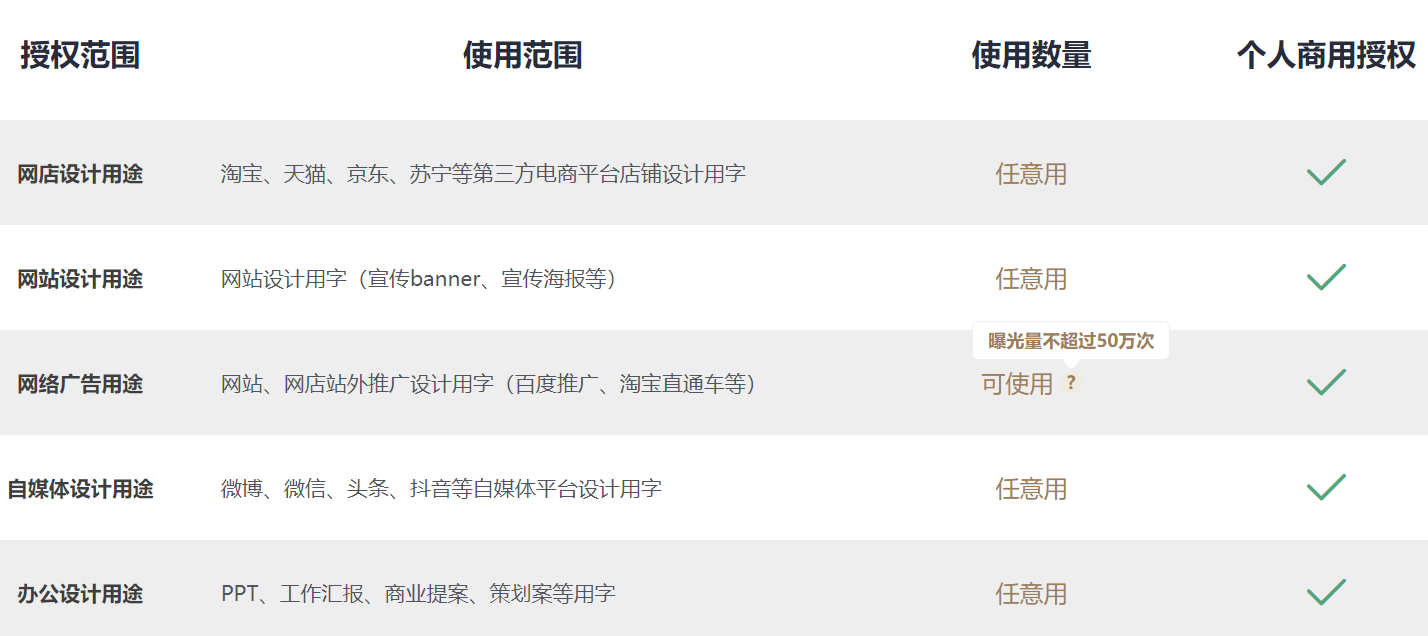
如果你只是作为个人经营或自媒体使用,可以到字魂网等网站花小几百块购买一份个人授权,会比在网上到处找方便得多。

调整一下人物位置,在Photoshop中添加好文字,好了,图片完成。

彩蛋: